이동창 함수
시계열 연산에서 사용되는 배열 변형에서 중요한 요소는 움직이는 창 과 지수 가중과 함께 수행되는 통계외 여타 함수들이다.
이러한 이동창 함수(moving window function) 을 이용해서 누락된 데이터로 인해 매끄럽지 않은 시계열 데이터를 다듬을 수 있다.
우선 시계열 데이터를 불러와서 영업일 빈도로 리샘플링하자.
lose_px_all = pd.read_csv('examples/stock_px_2.csv',
parse_dates=True, index_col=0)
close_px = close_px_all[['AAPL', 'MSFT', 'XOM']]
close_px = close_px.resample('B').ffill()
close_px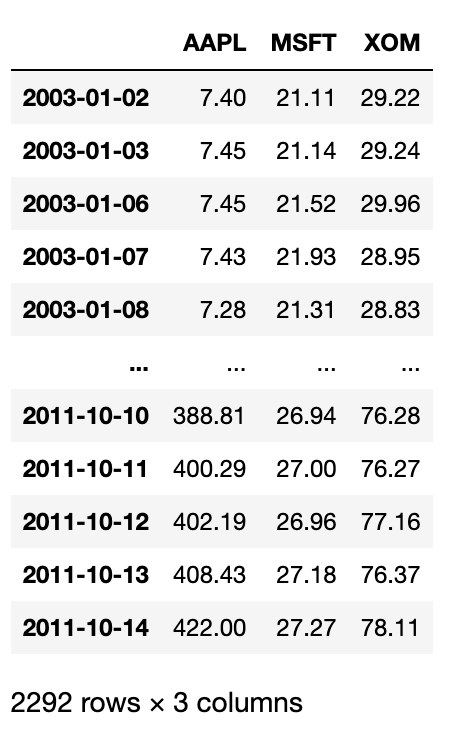
이제 resample 이나 groupby와 유사하게 작동하는 rolling 연산을 알아보자. 이는 Series와 DataFrame에 대해 원하는 기간을 나타내는 window 값과 함께 호출할 수 있다.
import matplotlib.pyplot as plt
close_px.AAPL.plot()
close_px.AAPL.rolling(250).mean().plot()
plt.figure()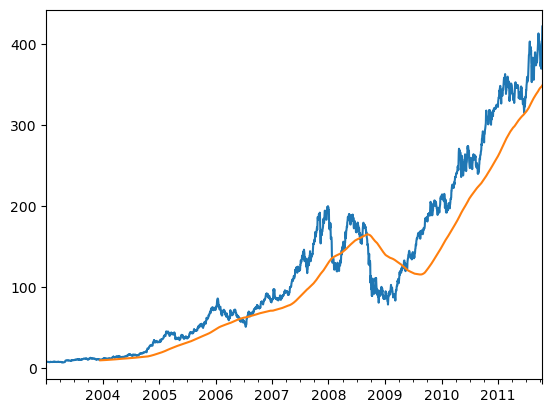
rolling(250) 이라는 표현은 groupby와 비슷해 보이지만 그룹을 생성하는 대신 250일 크기의 움직이는 창을 통해 그룹핑할 수 있는 객체를 생성한다.
rolling 함수는 기본적으로 결측치가 없기를 기대하지만 시계열의 시작 지점에서는 필연적으로 window보다 적은 기간의 데이터를 가지고 있으므로 이를 처리하기 위해 rolling 함수의 동작 방식은 변경될 수 있다.
appl_std250=close_px.AAPL.rolling(250,min_periods=10).std()
appl_std250.plot()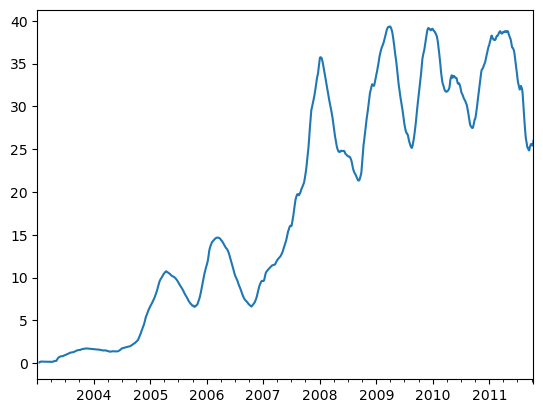
확장창 평균을 구하기 위해서는 rolling 대신 expanding을 사용한다. 확장창 평균은 시계열의 시작 지점에서부터 창의 크기가 시계열의 전체 크기가 될 때까지 창의 크기를 늘린다. apple_std250 시계열의 확장창 평균은 아래처럼 수할 수 있다.
expanding_mean=appl_std250.expanding().mean()
expanding_mean
"""
2003-01-02 NaN
2003-01-03 NaN
2003-01-06 NaN
2003-01-07 NaN
2003-01-08 NaN
...
2011-10-10 18.521201
2011-10-11 18.524272
2011-10-12 18.527385
2011-10-13 18.530554
2011-10-14 18.533823
Freq: B, Name: AAPL, Length: 2292, dtype: float64
"""DataFrame에 대해 이동창 함수를 호출하면 각 컬럼에 적용이 된다.
close_px.rolling(60).mean().plot(logy=True)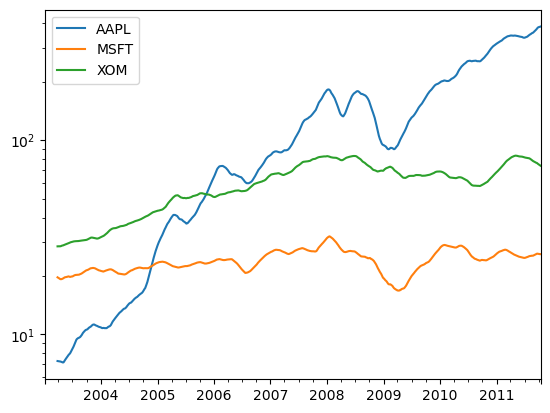
rolling 함수는 고정 크기의 기간 지정 문자열을 넘겨서 호출할 수도 있다. 빈도가 불규칙한 시게열일 경우 유용하게 사용할 수 있다. resample 함수에서 사용했던 것과 같은 형식이다. 20일 크기의 이동평균은 아래처럼 구할 수 있다.
close_px.rolling('20D').mean()
11.7.1 지수 가중 함수
균등한 가중치를 가지는 관찰과 함께 고정 크기 창을 사용하는 다른 방법은 감쇠인자 상수에 좀 더 많은 가중치를 줘서 더 최근 값을 관찰하는 것이다. 감쇠인자 상수를 지정하는 방법은 기간을 이용하는 것이다.
이 방법은 결과를 같은 기간의 창을 가지는 단순 이동창 함수와 비교 가능하도록 해준다.
지수 가중 통꼐는 최근 값에 좀 더 많은 가중치를 두는 방법이므로 균등 가중 방식에 비해 더 빠르게 변화를 수용한다.
pandas는 rolling 이나 expanding과 함께 사용할 수 있는 ewm 연산을 제공한다.
애플 주가 60일 이동 평균을 span=60으로 구한 지수 가중 이동평균과 비교하며 이해해보자.
import matplotlib.pyplot as plt
plt.figure()
aapl_px = close_px.AAPL['2006':'2007']
ma60 = aapl_px.rolling(30, min_periods=20).mean()
ewma60 = aapl_px.ewm(span=30).mean()
ma60.plot(style='k--', label='Simple MA')
ewma60.plot(style='k-', label='EW MA')
plt.legend()matplotlib 라이브러리에 관한 정보는 따로 정리해놓았다.
11.7.2 이진 이동창 함수
상관관계와 공분산 같은 몇몇 통계 연산은 두 개의 시계열을 필요로 한다. 예를 들어, 금융 분석가는 종종 S&P 500 같은 비교 대상이 되는 지수와 주식의 상관관계를 자주 이용한다.
spx_px=close_px_all['SPX']
spx_rets=spx_px.pct_change()
returns=close_px.pct_change()
spx_rets
"""
2003-01-02 NaN
2003-01-03 -0.000484
2003-01-06 0.022474
2003-01-07 -0.006545
2003-01-08 -0.014086
...
2011-10-10 0.034125
2011-10-11 0.000544
2011-10-12 0.009795
2011-10-13 -0.002974
2011-10-14 0.017380
Name: SPX, Length: 2214, dtype: float64
"""returns 변수에 저장된 DataFrame도 spx_rets와 동일하게 각 컬럼별 주가 변화율이 저장되었다.
rolling 함수에 이어 호출한 corr 요약함수는 spx_rets와의 상관관계를 계산한다.
corr=returns.AAPL.rolling(125,min_periods=100).corr(spx_rets)
corr.plot()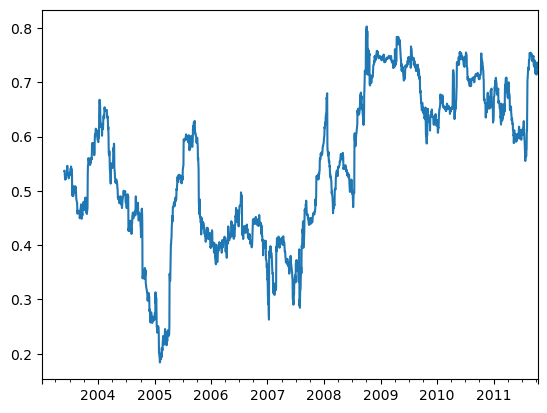
여러 주식과 S&P 500 지수와의 상관관계를 한 번에 계산하고 싶다고 가정하자. 반복문을 작성해서 새로운 DataFrame을 생성하면 쉽겠지만, 좋은 방법이 아니다.
TimeSeries와 DataFrame 그리고 rolling_corr 같은 함수를 넘겨서 TimeSeries와 DataFrame의 각 컬럼 간의 상관관계를 계산하면 된다.
corr=returns.rolling(125,min_periods=100).corr(spx_rets)
corr.plot()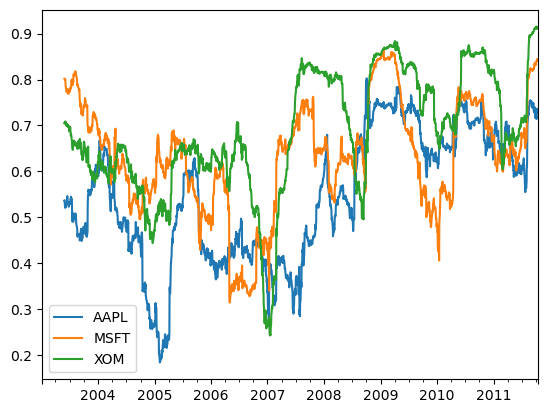
6개월 수익과 S&P 500 지수와의 상관관계를 계산해보았다.
11.7.3 사용자 정의 이동창 함수
rolling 이나 다른 관련 메서드에 apply를 호출해서 이동창에 대한 사용자 정의 연산을 수행할 수도 있다. 유일한 요구사항은 사용자 정의 함수가 배열의 각 조각으로부터 단일 값(감소)을 반환해야 한다.
예를 들어, rolling(...).quantile(q)를 사용해서 표본 변위치를 계산할 수 있는 것처럼 전체 표본에서 특정 값이 차지하는 백분위 점수를 구하는 함수를 작성할 수도 있다.
scipy.stats.percentileofscore 함수가 그런 기능을 한다.
from scipy.stats import percentileofscore
score_at_2percent=lambda x:percentileofscore(x,0.02)
result=returns.AAPL.rolling(250).apply(score_at_2percent)
result.plot()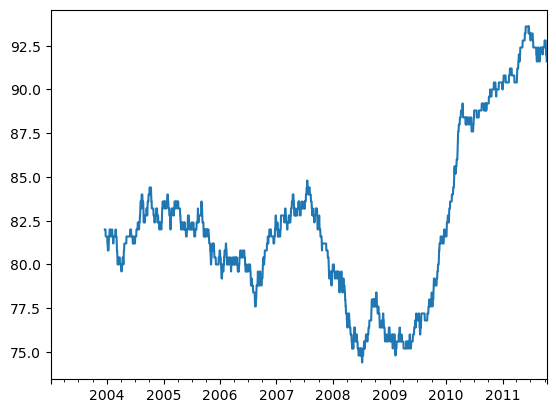
마치며
시계열 데이터는 앞서 살펴본 다른 형태의 데이터와는 다른 종류의 분석과 데이터 변형을 요구하는 것을 알아보았다.
다음 장에서는 고급 pandas 사용자가 되기 위한 몇 가지 기능을 살펴보자.
