리샘플링은 시계열의 빈도를 변환하는 과정을 일컫는다. 상위 빈도의 데이터를 하위 빈도로 집계하는 것을 다운샘플링, 반대 과정을 업샘플링이라고 한다. 모든 리샘플링이 두가지 범주에 들어가지는 않는다.
Ex: (day->month : 업샘플링, month->day : 다운샘플링)
리샘플링과 빈도 변환
pandas객체는 resample 메서드를 가지고 있는데, 빈도 변환과 관련된 모든 작업에서 유용하게 사용되는 메서드다.
resample은 groupby와 비슷한 API를 가지고 있는데 resample을 호출해서 데이터를 그룹 짓고 요약함수를 적용하는 식이다.
rng=pd.date_range('2000-01-01',periods=100,freq="D")
ts=pd.Series(np.random.randn(len(rng)),index=rng)
ts
"""
2000-01-01 0.956576
2000-01-02 2.328780
2000-01-03 -1.689931
2000-01-04 -1.609933
2000-01-05 -0.077653
...
2000-04-05 -0.679465
2000-04-06 -0.870280
2000-04-07 1.139444
2000-04-08 1.535472
2000-04-09 -1.240627
Freq: D, Length: 100, dtype: float64
"""
ts.resample('M',kind='period').mean()
"""
2000-01 0.022139
2000-02 0.358112
2000-03 0.007719
2000-04 -0.140448
Freq: M, dtype: float64
"""resmaple은 유연한 고수준의 메서드로, 매우 큰 시계열 데이터를 처리할 수 있다. 다음 resample 인자를 기억해두자.
| 인자 | 설명 |
|---|---|
| freq | 원하는 리샘플링 빈도를 가리키는 문자열이나 DateOffset 리샘플링을 수행할 축 |
| axis | 리샘플링을 수행할 축 선택. 기본값 axis=0 |
| fill_method | 업샘플링 시 사용할 보간 방법.'ffill'과 'bfill'이 있다. |
| closed | 다운샘플링 시 각 간격의 어느 쪽을 포함할지 가리킨다. 기본 값은 right이다. |
| label | 다운샘플링 시 집계된 결과의 라벨을 결정한다.right or left 중 선택 |
| loffset | 나뉜 그룹의 라벨에 맞추기 위한 오프셋 '-1s'/Second(-1)은 집계된 라벨을 1초 앞당긴다. |
| limit | 보간법을 사용할 때 보간을 적용할 최대 기간 |
| kind | 기간(period) 혹은 timestamp별로 집계할 것인지 구분, 기본값은 시계열 색인의 종류와 같다. |
| convention | 기간을 리샘플링할 때 상위 빈도로 변환 시의 방식.start or end |
다운샘플링
시계열 데이터를 규칙적인 하위 빈도로 집계하는 일은 자주있다.
집계할 데이터는 고정 빈도를 가질 필요가 없으며 잘라낸 시계열 조각의 크기를 원하는 빈도로 정의한다.
resample을 사용해서 데이터를 다운샘플링할 때 고려해야 할 사항이 몇 가지 있다.
1)각 간격의 양끝 중에서 어느 쪽을 닫아둘 것인가
2)집계하려는 구간의 라벨을 간격의 시작으로 할지 끝으로 할지 여부
분 단위 데이터를 통해 알아보자.
rng=pd.date_range('2000-01-01',periods=12,freq='T')
rng
"""
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 00:01:00',
'2000-01-01 00:02:00', '2000-01-01 00:03:00',
'2000-01-01 00:04:00', '2000-01-01 00:05:00',
'2000-01-01 00:06:00', '2000-01-01 00:07:00',
'2000-01-01 00:08:00', '2000-01-01 00:09:00',
'2000-01-01 00:10:00', '2000-01-01 00:11:00'],
dtype='datetime64[ns]', freq='T')
"""
ts=pd.Series(np.arange(12),index=rng)
ts
"""
2000-01-01 00:00:00 0
2000-01-01 00:01:00 1
2000-01-01 00:02:00 2
2000-01-01 00:03:00 3
2000-01-01 00:04:00 4
2000-01-01 00:05:00 5
2000-01-01 00:06:00 6
2000-01-01 00:07:00 7
2000-01-01 00:08:00 8
2000-01-01 00:09:00 9
2000-01-01 00:10:00 10
2000-01-01 00:11:00 11
Freq: T, dtype: int64
"""이 데이터를 5분 단위로 묶어서 각 그룹의 합을 집계해보자.
ts.resample('5min',closed='left').sum()
"""
2000-01-01 00:00:00 10
2000-01-01 00:05:00 35
2000-01-01 00:10:00 21
Freq: 5T, dtype: int64
"""
ts.resample('5min',closed='right').sum()
"""
1999-12-31 23:55:00 0
2000-01-01 00:00:00 15
2000-01-01 00:05:00 40
2000-01-01 00:10:00 11
Freq: 5T, dtype: int64
"""두 출력값을 비교해보면 closed 옵션에 대해 더 잘 이해할 수 있다.
인자로 넘긴 빈도는 5분 단위로 증가하는 그룹의 경계를 정의한다. 기본적으로 시작값을 그룹의 왼쪽에 포함시키므로 00:00의 값은 첫번째 그룹의 00:00~00:05까지의 값을 집계한다.
그러므로 closed='right'를 넘기면 시작값을 그룹의 오른쪽에 포함시킨다.
결과로 반환된 시계열은 각 그룹의 왼쪽 타임스탬프(start) 가 라벨로 지정되었다. label='right'를 넘겨서 각 그룹의 오른쪽 값을 라벨(end)로 사용할 수 있다.
ts.resample('5min',closed='right',label='right').sum()
"""
2000-01-01 00:00:00 0
2000-01-01 00:05:00 15
2000-01-01 00:10:00 40
2000-01-01 00:15:00 11
Freq: 5T, dtype: int64
"""출력값을 잘 뜯어보면 label과 closed 옵션에 대해 명확히 이해하는데 도움될 것 같다.
반환된 결과의 색인을 특정 크기만큼 이동시키고 싶은 경우, loffset을 사용하여 그룹의 오른쪽 끝에서 1초를 빼서 타임스탬프가 참조하는 간격을 좀 더 명확히 보여줄 수 있다. 근데 난 이게 더 헷갈린다.
ts.resample('5min',closed='right',label='right',loffset='-1s').sum()
"""
1999-12-31 23:59:59 0
2000-01-01 00:04:59 15
2000-01-01 00:09:59 40
2000-01-01 00:14:59 11
Freq: 5T, dtype: int64
"""loffset 옵션 대신 반환된 결과에 shift 메서드를 사용해도 같은 결과를 얻을 수 있다.
OHLC 리샘플링
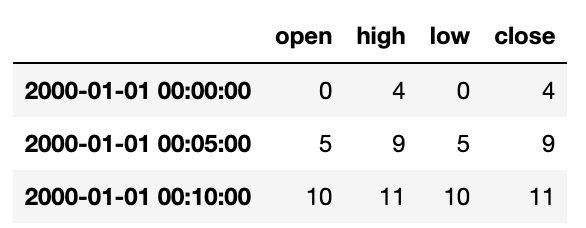
금융 분야에서 시계열 데이터를 집계하는 아주 흔한 방식은 각 버킷에 대해 4가지 값을 계산하는 것이다. 이 4가지 값은 시가, 고가, 저가, 종가 이고 이를 OHLC(Oepn-High-Low-Close)라 칭한다. Resample에how='ohlc'를 넘겨서 한 번에 이 값을 담고 있는 컬럼을 가지는 DataFrame을 얻을 수 있다.
ts.resample('5min').ohlc()
업샘플링과 보간
하위 빈도에서 상위 빈도로 변환할 때는 집계가 필요하지 않다. 주간 데이터를 담고 있는 DataFrame을 살펴보자.
frame=pd.DataFrame(np.random.randn(2,4),
index=pd.date_range('1/1/2000',periods=2,
freq='W-WED'),
columns=['Colorado','Texas','New York','Ohio'])
frame
"""
Colorado Texas New York Ohio
2000-01-05 1.053746 -0.428858 1.388716 0.522045
2000-01-12 -1.114398 1.196264 -1.142413 -0.041166
"""이 데이터에 요약함수를 사용하면 그룹당 하나의 값이 들어가고 그 사이에 결측치가 들어간다.
asfreq메서드를 이용해서 어떤 요약함수도 사용하지 않고 상위 빈도로 리샘플링 해보자.
df_daily=frame.resample('D').asfreq()
df_daily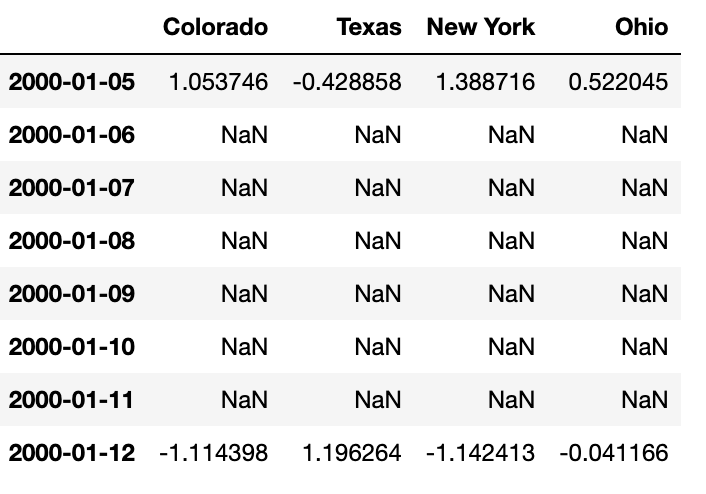
수요일이 아닌 요일에는 이전 값을 채워서 보간을 수행해보자. fillna와 reindex메서드에서 사용했던 보간 메서드를 resampling에서도 사용할 수 있다.
frame.resample('D').ffill()
#frame.resample('D').ffill(limit=2)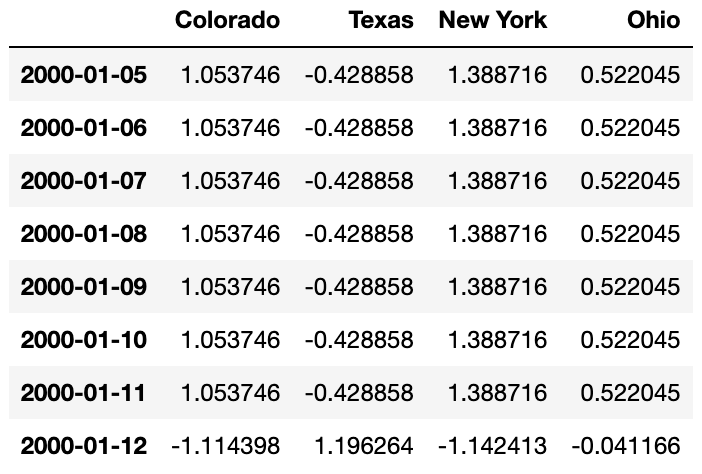
limit옵션을 사용해서 보간법을 적용할 범위를 지정하는 것도 가능하다.
기간 리샘플링
기간으로 색인된 데이터를 리샘플링하는 것은 타임스탬프와 유사하다.
frame=pd.DataFrame(np.random.randn(24,4),
index=pd.period_range('1-2000','12-2001',
freq='M'),
columns=['Colorado','Texas','New York','Ohio'])
frame[:5]
"""
Colorado Texas New York Ohio
2000-01 -0.499756 -0.196175 -0.348911 0.266555
2000-02 0.124501 -2.258968 -0.080503 1.235623
2000-03 -0.306233 -0.402273 2.220443 -1.674967
2000-04 -0.562149 1.589268 0.937833 -0.351387
2000-05 1.529830 -0.169147 0.127895 -0.848859
"""
annual_frame=frame.resample('A-DEC').mean()
annual_frame
"""
Colorado Texas New York Ohio
2000 -0.263742 0.223428 -0.387383 -0.092515
2001 0.255489 -0.338622 0.083106 -0.040381
"""업샘플링은 asfreq 메서드처럼 리샘플링하기 전에 새로운 빈도에서 구간의 끝을 어느 쪽에 두어야할 지 미리 결정해야한다. convention 인자의 기본값은 start 이지만 end로 지정할 수도 있다.
annual_frame.resample('Q-DEC').ffill()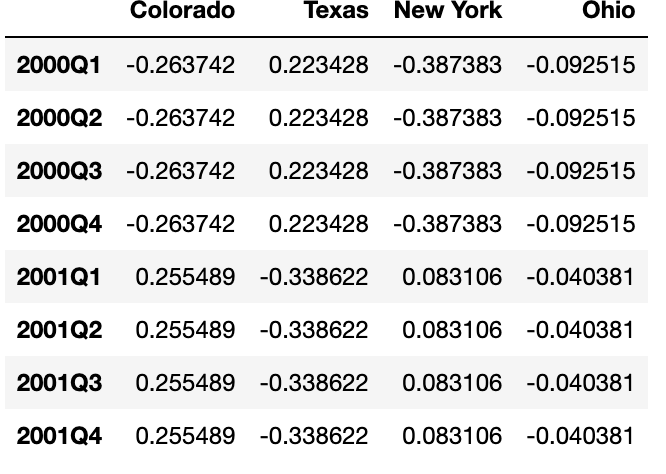
annual_frame.resample('Q-DEC',convention='end').ffill()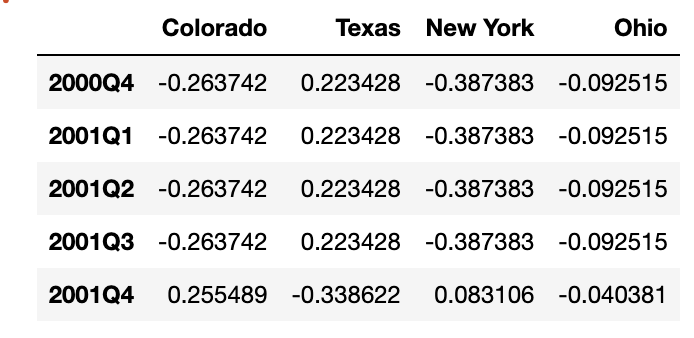
기간의 업샘플링과 다운샘플링은 좀 더 엄격하다.
- 다운샘플링의 경우 대상 빈도는 반드시 원본 빈도의 하위 기간이어야한다.
- 업샘플링의 경우 대산 빈도는 반드시 원본 빈도의 상위 기간이어야한다.
위 조건을 만족하지 않으면 예외가 발생한다. 이 예외는 주로 분기, 연간, 주간 빈도에서 발생하는데, 예로 Q-MAR로 정의된 기간은 A-MAR,A-JUN,A-SEP,A-DEC로만 이루어져야 한다.
마치며
이번 로그에선 time series의 resample에 대해서 다루었다. 다음 로그에서는 이동창 함수에 대해서 알아보자
