Period
며칠, 몇 개월, 몇 해 같은 기간은 Period 클래스로 표현할 수 있으며 문자열이나 정수 그리고 빈도를 가지고 생성한다.
p=pd.Period(2007,freq='A-DEC')
p
#Out:Period('2007', 'A-DEC')여기서 Period 객체는 2007년 1월 1일부터 같은 해 12월 31일까지의 기간을 표현한다. 이 기간에 정수를 더하거나 빼서 편리하게 정해진 빈도에 따라 기간을 이동시킬 수 있다.
p+5
#Out:Period('2012', 'A-DEC')
p-2
#Out:Period('2005', 'A-DEC')만약 두 기간이 같은 빈도를 가진다면 차는 둘 사이의 간격이 된다.
pd.Period('2014',freq='A-DEC')-p
#Out:<7 * YearEnds: month=12>일반적인 기간 범위는 period_range 함수로 생성할 수 있다.
rng=pd.period_range('2000-01-01','2000-06-30',freq='M')
rng
#Out:PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '2000-#06'], dtype='period[M]')PeriodIndex 클래스는 순차적인 기간을 저장하며 다른 Pandas 자료구조에서 축 색인과 마찬가지로 사용된다.
pd.Series(np.random.randn(6),index=rng)
"""
2000-01 1.254762
2000-02 1.330094
2000-03 0.764259
2000-04 -0.920961
2000-05 -0.970009
2000-06 -0.017024
Freq: M, dtype: float64
"""다음과 같은 문자열 배열을 이용해서 PeriodIndex 클래스를 생성하는 것도 가능하다.
values=['2001Q3','2002Q2','2003Q1']
index=pd.PeriodIndex(values,freq='Q-DEC')
index
#Out:PeriodIndex(['2001Q3', '2002Q2', '2003Q1'], dtype='period[Q-DEC]')Period 빈도 변환
Period와 PeriodIndex 객체는 asfreq 메서드를 통해 다른 빈도로 변환할 수도 있다. 예를 들어 새해 첫날부터 시작하는 연간 빈도를 월간 빈도로 변환해보자.
p = pd.Period('2007', freq='A-DEC')
p
#Out:Period('2007', 'A-DEC')
p.asfreq('M', how='end')
#Out:Period('2007-12', 'M')
p.asfreq('M', how='start')
#Out:Period('2007-01', 'M')이 경우, 회계연도 마감이 12월이 아닌 경우에는 월간 빈도가 달라지게 된다.
p = pd.Period('2007', freq='A-JUN')
p
#Out:Period('2007', 'A-JUN')
p.asfreq('M','start')
#Out:Period('2006-07', 'M')
p.asfreq('M','End')
#Out:Period('2007-06', 'M')빈도가 상위에서 하위로 변환되는 경우 (Ex: 년 -> 월 ) 상위 기간은 하위 기간이 어디에 속했는 지에 따라 결정된다. 예를 들어 빈도가 A-JUN일 경우 2007년 8월은 2008년에 속하게 된다.
p = pd.Period('Aug-2007', 'M')
p.asfreq('A-JUN')
#Out:Period('2008', 'A-JUN')모든 PeriodIndex 객체나 시계열은 같은 방식으로 변환할 수 있다.
rng = pd.period_range('2006', '2009', freq='A-DEC')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
"""
2006 0.711508
2007 -0.132376
2008 -0.734192
2009 -0.398720
Freq: A-DEC, dtype: float64
"""
ts.asfreq('M', how='start')
"""
2006-01 0.711508
2007-01 -0.132376
2008-01 -0.734192
2009-01 -0.398720
Freq: M, dtype: float64
"""분기 빈도
분기 데이터는 재정, 금융 및 다양한 분야에서 표준으로 사용한다. 대부분의 분기 데이터는 일반적으로는 회계연도의 끝인 12월의 마지막 업무일을 기준으로 보고한다. pandas에서는 이 뿐만이 아니라, 12가지 모든 경우의 분기 빈도를 지원한다.
p=pd.Period('2007',freq='A-DEC')
p
#Out:Period('2007', 'A-DEC')
p.asfreq('D','start')
#Out:Period('2007-01-01', 'D')
p.asfreq('D','end')
#Out:Period('2007-12-31', 'D')이렇게 하여 기간 연산을 매우 쉽게 할 수 있는데, 그 예로 분기 영업마감일의 오후 4시를 가리키는 타임스탬프는 다음과 같이 구할 수 있다.
p4pm=(p.asfreq('B','e')-1).asfreq('T','s')+16*60
p4pm
#Out:Period('2007-12-28 16:00', 'T')
p4pm.to_timestamp()
#Out:Timestamp('2007-12-28 16:00:00')period_range를 사용해서 분기 범위를 생성할 수 있다. 연산 역시 동일한 방법으로 수행할 수 있다.
rng=pd.period_range('2011Q3','2012Q4',freq='Q-JAN')
ts=pd.Series(np.arange(len(rng)),index=rng)
ts
"""
2011Q3 0
2011Q4 1
2012Q1 2
2012Q2 3
2012Q3 4
2012Q4 5
Freq: Q-JAN, dtype: int64
"""
new_rng=(rng.asfreq('B','e')-1).asfreq('T','s')+16*60
ts.index=new_rng.to_timestamp()
new_rng
"""
PeriodIndex(['2010-10-28 16:00', '2011-01-28 16:00', '2011-04-28 16:00',
'2011-07-28 16:00', '2011-10-28 16:00', '2012-01-30 16:00'],
dtype='period[T]')
"""
ts
"""
2010-10-28 16:00:00 0
2011-01-28 16:00:00 1
2011-04-28 16:00:00 2
2011-07-28 16:00:00 3
2011-10-28 16:00:00 4
2012-01-30 16:00:00 5
dtype: int64
"""타임스탬프와 기간 서로 변환하기
타임스탬프로 색인된 Series와 DataFrame 객체는 to_period 메서드를 사용해서 기간으로 변환 가능하다.
rng = pd.date_range('2000-01-01', periods=3, freq='M')
ts = pd.Series(np.random.randn(3), index=rng)
ts
"""
2000-01-31 -0.758246
2000-02-29 -1.746781
2000-03-31 0.080676
Freq: M, dtype: float64
"""
pts = ts.to_period()
pts
"""
2000-01 -0.758246
2000-02 -1.746781
2000-03 0.080676
Freq: M, dtype: float64
"""여기서 말하는 기간은 겹치지 않는 시간상의 간격으로 주어진 빈도에서 타임스탬프는 하나의 기간에만 속한다.
새로운 PeriodIndex의 빈도는 기본적으로 타임스탬프 값을 통해 추론되지만 원하는 빈도를 직접 지정할 수도 있다.
rng=pd.date_range('1/29/2000',periods=6,freq='D')
ts2=pd.Series(np.random.randn(6),index=rng)
ts2
"""
2000-01-29 0.327303
2000-01-30 0.788592
2000-01-31 -1.423814
2000-02-01 0.553347
2000-02-02 -0.076683
2000-02-03 2.158374
Freq: D, dtype: float64
"""
ts2.to_period('M')
"""
2000-01 0.327303
2000-01 0.788592
2000-01 -1.423814
2000-02 0.553347
2000-02 -0.076683
2000-02 2.158374
Freq: M, dtype: float64
"""배열로 PeriodIndex 생성하기
고정된 빈도를 갖는 데이터는 종종 여러 컬럼에 걸쳐 기간에 대한 정보가 저장되기도 한다.
예를들어 거시경제화 데이터셋에는 연도와 분기가 구분된 컬럼에 존재한다.
data=pd.read_csv('examples/macrodata.csv')
data.head(5)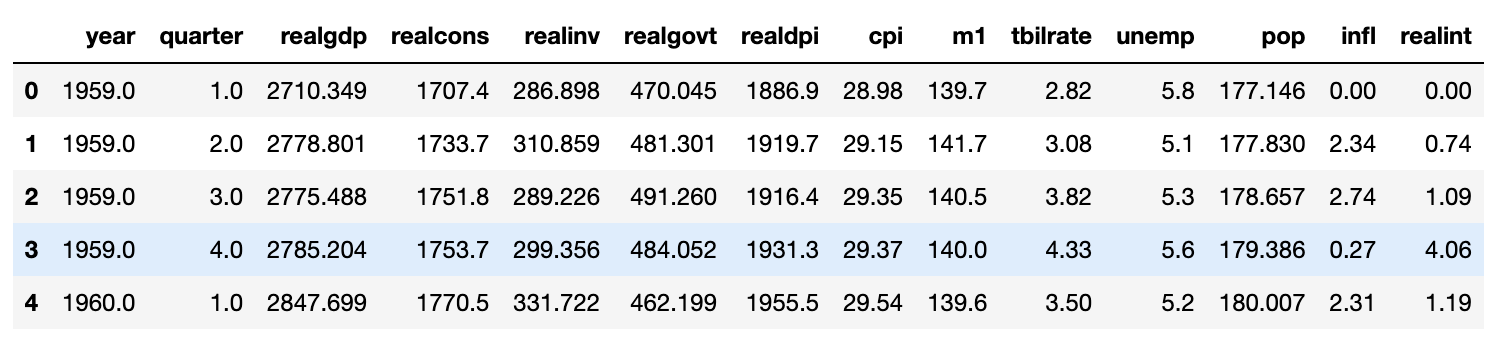 이 배열을 PeriodIndex에 빈도값과 함께 전달하면 이를 조합해서 DataFrame에서 사용할 수 있는 색인을 만들어낸다.
이 배열을 PeriodIndex에 빈도값과 함께 전달하면 이를 조합해서 DataFrame에서 사용할 수 있는 색인을 만들어낸다.
index=pd.PeriodIndex(year=data.year,quarter=data.quarter,freq='Q-DEC')
index
"""
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='period[Q-DEC]', length=203)
"""
data.index=index
data.infl
"""
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
...
2008Q3 -3.16
2008Q4 -8.79
2009Q1 0.94
2009Q2 3.37
2009Q3 3.56
Freq: Q-DEC, Name: infl, Length: 203, dtype: float64
"""마치며
이번 로그에선 Period 에 대해 다루어 보았다. 다음 로그에서는 리샘플링과 이동창 함수에 대해 다뤄보자.
