재형성과 피벗
표 형식의 데이터를 '재배치하는 다양한 기본 연산'이 존재한다. 이런 연산을 재형성 또는 피벗 연산이라고 한다.
계층적 색인으로 재형성하기
계층적 색인은 DataFrame의 데이터를 재배치하는 다음과 같은 방식을 제공한다.
stack:데이터의 컬럼을 로우로 회전시킨다.
unstack:데이터의 로우를 컬럼으로 회전시킨다.
data = pd.DataFrame(np.arange(6).reshape((2, 3)),
index=pd.Index(['Ohio', 'Colorado'],
name='state'),
columns=pd.Index(['one', 'two', 'three'],
name='number'))
data
data에 stack 메서드를 사용하면 데이터의 컬럼을 로우로 회전시키기 때문에 계층색인을 가진 Series 객체를 반환하게 된다.
result=data.stack()
result
이 data 객체가 stack된 Series를 다시 unstack하게 되면 초기의 DataFrame 객체를 반환하게 된다.
기본값은 가장 안쪽에 있는 level부터 끄집어 내는데. level 숫자나 이름을 전달해서 끄집어낼 단계를 지정할 수도 있다.
result.unstack(0)
#result.unstack('state') -> 같은 출력값을 가진다.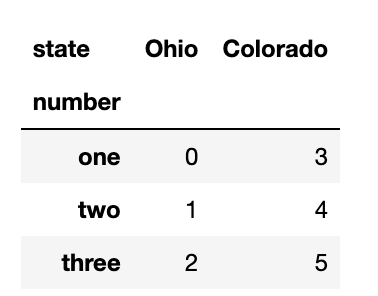
해당 level에 있는 모든 값이 하위그룹에 속하지 않을 경우 unstack을 하게 되면 NaN값이 생길 수도 있다.
s1 = pd.Series([0, 1, 2, 3], index=['a', 'b', 'c', 'd'])
s2 = pd.Series([4, 5, 6], index=['c', 'd', 'e'])
data2 = pd.concat([s1, s2], keys=['one', 'two'])
data2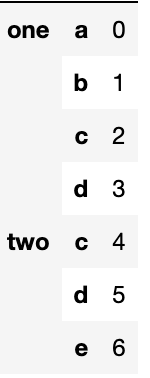
data2.unstack()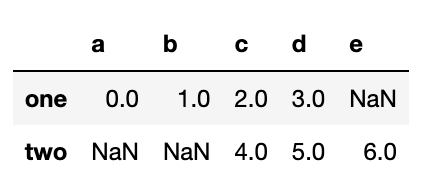
이런 경우 stack 메서드는 누락된 데이터를 자동으로 걸러내기 때문에, 쉽게 복구시킬 수 있다.
data2.unstack().stack()
앞서 보았듯, DataFrame을 unstack()할 때 unstack되는 레벨은 결과에서 가장 낮은 단계가 된다.또한, stack을 호출할 때 쌓을 축의 이름을 지정할 수 있다.
df = pd.DataFrame({'left': result, 'right': result + 5},
columns=pd.Index(['left', 'right'],
name='side'))
df
df.unstack('state').stack('side')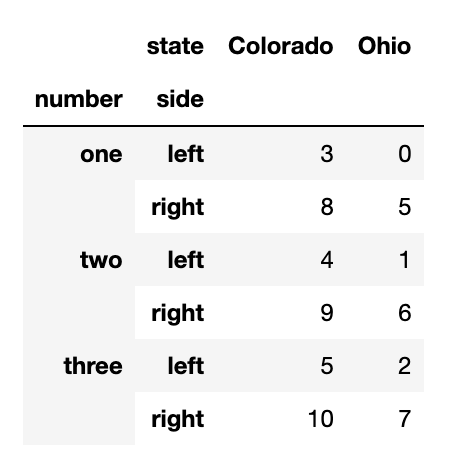
긴 형식에서 넓은 형식으로 피벗하기
데이터베이스나 csv파일에 여러 개의 시계열 데이터를 저장하는 일반적인 방법은 시간 순서대로 나열하는 것이다.
예제 데이터를 읽어서 시계열 데이터를 다뤄보자. 시계열 데이터는 chapter 11에서 다룰 것이므로 간단히 훑어보자.
data = pd.read_csv('examples/macrodata.csv')
data.head()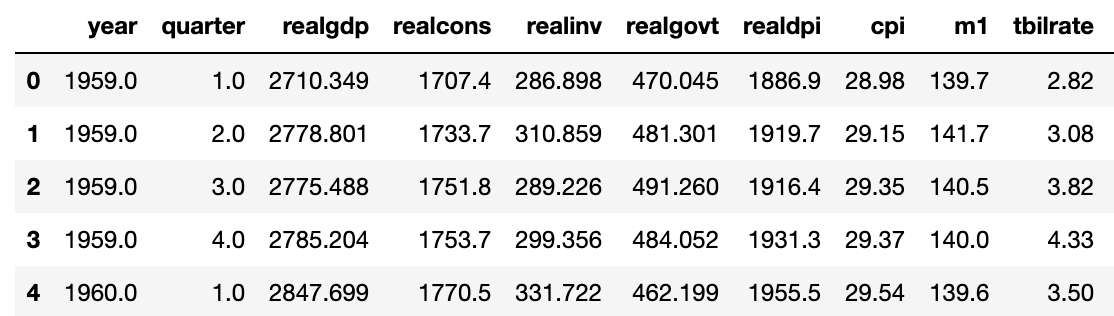
PeriodIndex는 간단히 설명하자면 시간 간격을 나타내기 위한 자료형으로, year와 quater 컬럼을 합친다.
columns 변수는 불필요한 컬럼을 남기고, 필요한 columns만을 추린 것이다. 또 이렇게 생성된 columns를 data 객체에 reindex 해준다.
periods = pd.PeriodIndex(year=data.year, quarter=data.quarter,
name='date',freq='Q-DEC')
columns = pd.Index(['realgdp', 'infl', 'unemp'], name='item')
data = data.reindex(columns=columns)
dataldata는 다음과 같다.
data.index = periods.to_timestamp('D')
ldata = data.stack().reset_index().rename(columns={0: 'value'})
ldata[:10]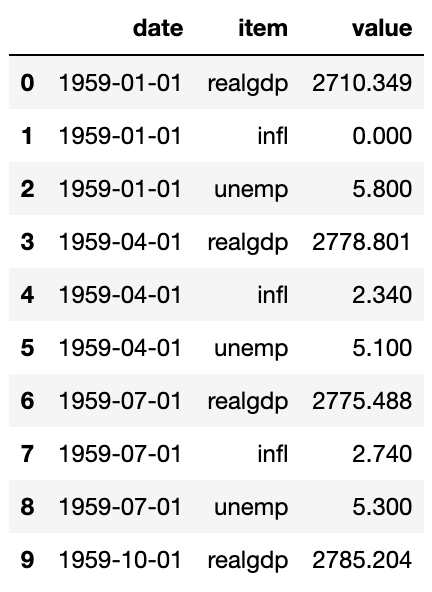
이를 긴 형식이라고 부르며, 여러 시계열이나 둘 이상의 키를 가지는 다른 관측 데이터에서 사용한다.
길이가 긴 형식으로는 작업이 용이하지 않으므로 하나의 DataFrame에 Date 컬럼의 시간값으로 색인된 개별 item 컬럼으로 포함시키는 것을 선호할 지도 모른다. DataFramedml pivot 메서드가 바로 이런 변향을 지원한다.
pivoted = ldata.pivot(index='date',columns='item',values='value')
pivoted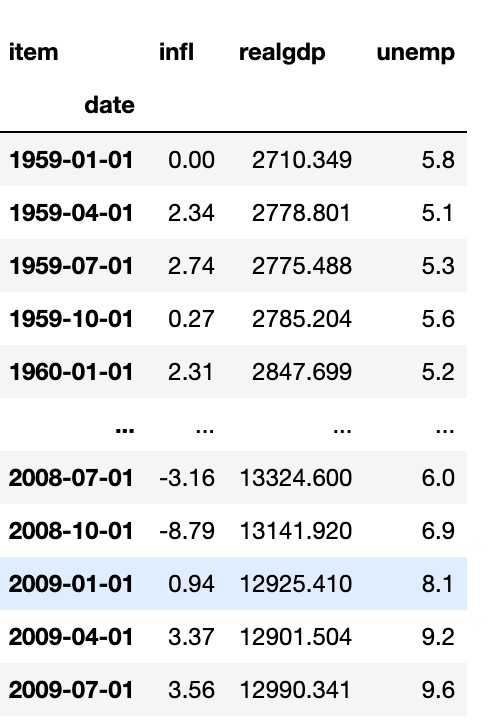
pivot 메서드의 처음 두 인자는 로우와 컬럼 색인으로 사용될 컬럼 이름이고 마지막 두 인자는 DataFrame에 채워 넣을 값을 담고 있는 컬럼 이름이다. 한 번에 두 개의 컬럼을 동시에 변형한다고 하자.
ldata['value2']=np.random.randn(len(ldata))
ldata[:10]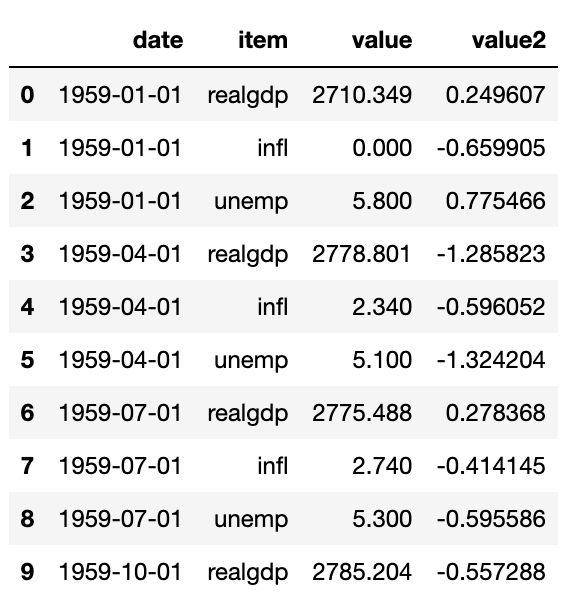
마지막 인자를 생략해서 계층적 컬럼을 가지는 DataFrame을 얻을 수 있다.
pivoted = ldata.pivot(index='date',columns= 'item')
pivoted[:5]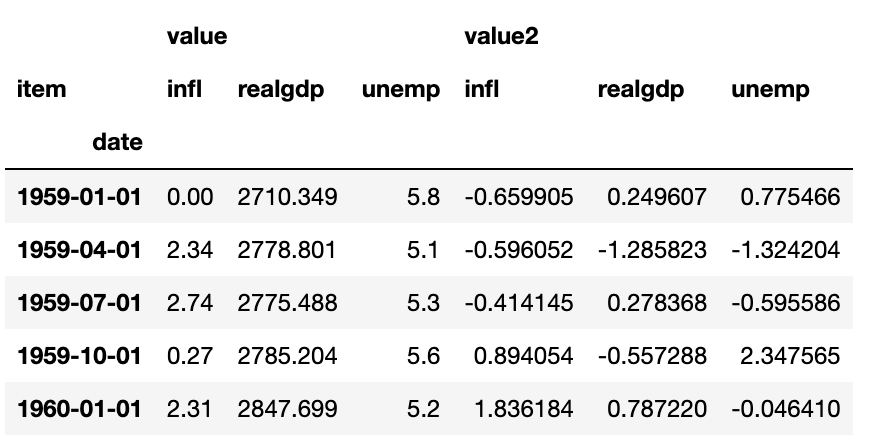
pivoted['value'][:5]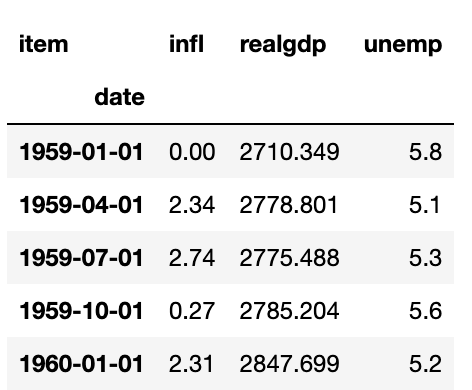 pivot은 단지 set_index를 사용해서 계층적 색인을 만들고 unstack 메서드를 이용해서 형태를 변ㄴ형하는 단축키 같은 메서드이다.
pivot은 단지 set_index를 사용해서 계층적 색인을 만들고 unstack 메서드를 이용해서 형태를 변ㄴ형하는 단축키 같은 메서드이다.
8.2.3 넓은 형식에서 긴 형식으로 피벗하기
pivot과 반대되는 연산은 pandas.melt다. 하나의 컬럼을 여러 개의 새로운 DataFrame으로 생성하기보다는 여러 컬럼을 하나로 병합하고 DataFrame을 입력보다 긴 형태로 만들어낸다.
df = pd.DataFrame({'key': ['foo', 'bar', 'baz'],
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]})
df
# key A B C
#0 foo 1 4 7
#1 bar 2 5 8
#2 baz 3 6 9'key' 컬럼을 그룹 구분자로 사용할 수 있고 다른 컬럼을 데이터값으로 사용할 수 있다.pandas.melt를 사용할 때는 반드시 어떤 컬럼을 그룹 구분자로 사용할 것인지 지정해야한다.
melted = pd.melt(df, ['key'])
melted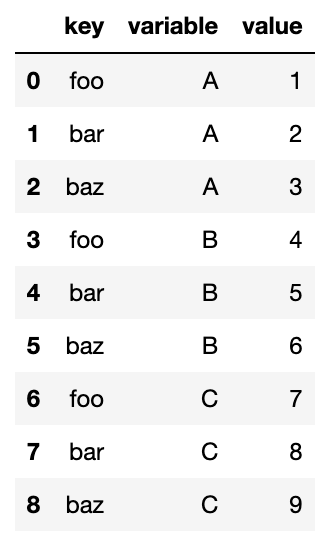
pivot을 사용해서 원래 모양으로 되돌릴 수있다.
reshaped = melted.pivot(index='key', columns='variable',values= 'value')
reshaped
#variable A B C
#key
#bar 2 5 8
#baz 3 6 9
#foo 1 4 7pivot의 결과는 로우 라벨로 사용하던 컬럼에서 색인을 생성하므로 reset_index를 이용해서 데이터를 다시 컬럼으로 돌려놓자.
reshaped.reset_index()
#variable key A B C
#0 bar 2 5 8
#1 baz 3 6 9
#2 foo 1 4 7데이터값으로 사용할 컬럼들의 집합을 지정할 수도 있다.
pd.melt(df, id_vars=['key'], value_vars=['A', 'B'])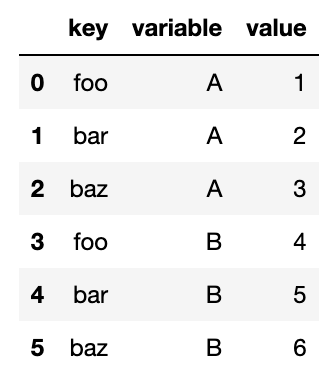
마치며
지금까지 pandas에서 데이터를 불러오고, 정제하고, 재배열하는 방식을 익혔다. 이제 다음 챕터에서는 이러한 객체들을 시각화 해보는 시간을 가져보겠다.
