기술 통계 계산과 요약
pandas의 클래스(DataFrame, Series)는 일반적인 수학 메서드와 통계 메서드를 가지고 있다. 이러한 메서드들을 Numpy의 ndarray에서 제공되는 동일한 메서드와 비교했을 때, pandas 클래스의 메서드는 처음부터 누락된 데이터를 제외하도록 설계되었다.
아래 예제를 보자.
df=pd.DataFrame([[1.4,np.nan],[7.1,-4.5],
[np.nan,np.nan],[0.75,-1.3]],
index=['a','b','c','d'],
columns=['one','two'])
df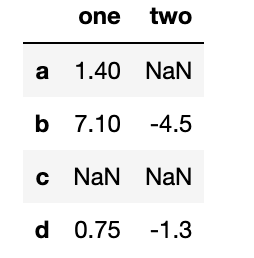
DataFrame의 sum 메서드를 호출하면 각 컬럼의 합을 담은 Series를 반환한다.(axis=1 옵션을 추가해주면 로우의 합을 반환해준다.)
df.sum()
#one 9.25
#two -5.80
#dtype: float64전체 로우나 컬럼의 값이 Nan 이라면 제외하고 계산한다. 하지만, skipna 옵션으로 이를 조정하여 NaN값을 제외하지 않도록 설정할 수 있다.
df.mean(axis=1,skipna=False)
#a NaN
#b 1.300
#c NaN
#d -0.275
#dtype: float64idxmin이나 idxmax 같은 메서드는 최솟값 혹은 최댓값을 가지고 있는 간접 통계(색인값)를 반환한다.
또 다른 메서드로 누산(cumsum)이 있다.
df.idxmax()
#one b
#two d
#dtype: object
df.cumsum()
#one two
#a 1.40 NaN
#b 8.50 -4.5
#c NaN NaN
#d 9.25 -5.8describe 메서드는 한 번에 여러 개의 통계 결과를 만들어낸다.
df.describe()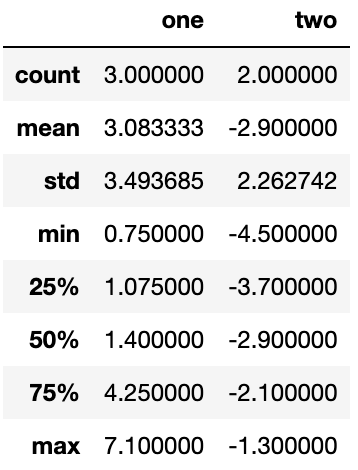
이 뿐만 아니라 요약 통계 관련 메서드는 다양하게 존재한다.
상관관계와 공분산
상관관계나 공분산(2개의 확률변수의 선형 관계를 나타내는 값) 같은 요약 통계 계산은 두 쌍의 인자를 필요로 한다. pandas-datareader 패키지를 이용해서 주식가격과 시가총액을 담고 있는 DataFrame을 만들어보자.
conda install pandas-datareader #jupyter notebook 사용
import pandas_datareader as web
all_data={ticker: web.get_data_yahoo(ticker)
for ticker in ['AAPL','IBM','MSFT','GOOG']}
all_data원래는 위의 코드를 사용하면 된다. 하지만, 위 코드는 코드를 작성한 시간대, 네트워크 연결 상태, 대문자 소문자 구별 유무에 따라서 에러의 발생이 생길 수 있다. 해당 글에서는 다운로드 받은 파일을 불러서 사용하겠다. 파일은 필자의 깃허브에서 다운로드 받을 수 있다.
price = pd.read_pickle("Practice/yahoo_price.pkl")
volume = pd.read_pickle("Practice/yahoo_volume.pkl")이제 시간에 따른 각 주식의 퍼센트 변화율을 계산해보자. 시계열을 다루는 법은 chapter 11에서 자세히 배워보자.
returns=price.pct_change()
returns.tail()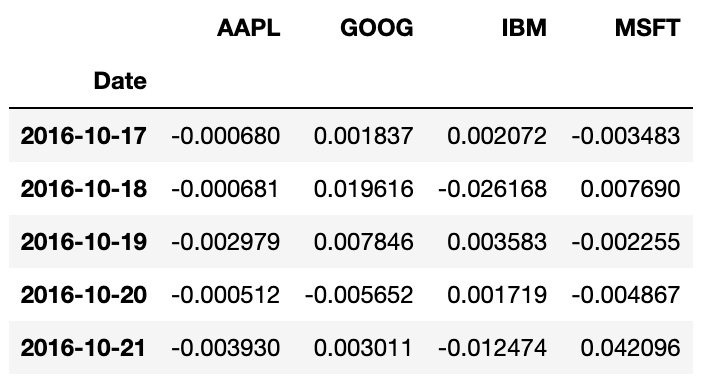 corr 메서드는 NA가 아니며 정렬된 색인에서 두 Series에 대해 상관관계를 계산하고, cov 메서드는 공분산을 계산한다.
corr 메서드는 NA가 아니며 정렬된 색인에서 두 Series에 대해 상관관계를 계산하고, cov 메서드는 공분산을 계산한다.
returns.MSFT.corr(returns.IBM)
#0.49976361144151144
returns.MSFT.cov(returns.IBM)
#8.870655479703546e-05DataFrame에서 corr과 cov 메서드는 DataFrame '행렬'에서 상관관계와 공분산을 계산한다.
returns.corr()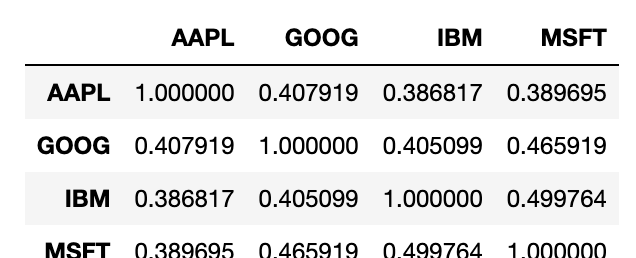
DataFrame의 corrwith 메서드를 사용하면 다른 Series나 DataFrame과의 상관관계를 계산한다.
Series를 넘기면 각 컬럼에 대해 계산한 상관관계를 담고 있는 Series 객체를 반환하고,
DataFrame을 넘기면 맞아 떨어지는 컬럼이름에 대한 상관관계를 계산한다.
returns.corrwith(returns.IBM)
#AAPL 0.386817
#GOOG 0.405099
#IBM 1.000000
#MSFT 0.499764
#dtype: float64
returns.corrwith(volume)
#AAPL -0.075565
#GOOG -0.007067
#IBM -0.204849
#MSFT -0.092950
#dtype: float64returns.corrwith(volume)이 코드를 해석하면 시가총액의 퍼센트 변화율에 대한 상관관계를 계산한 것이다.
유일값, 값 세기, 멤버십
1차원 Series에 담긴 정보를 추출하는 다양한 메서드가 있다.
다음 예제를 보자
obj = pd.Series(["c", "a", "d", "a", "a", "b", "b", "c", "c"])
obj.unique()
#array(['c', 'a', 'd', 'b'], dtype=object)
obj.value_counts()
#c 3
#a 3
#b 2
#d 1
#dtype: int64unique 메서드는 중복되는 값을 제거하고 유일값만 담고있는 Series를 반환한다.
그리고, value_counts 메서드는 Series에서 값의 도수를 계산하여 반환한다.
isin 메서드는 어떤 값이 Series에 존재하는지 나타내는 불리언 벡터를 반환하는데, Series나 DataFrame의 컬럼에서 값을 골라내고 싶을 때 유용하게 사용할 수 있다.
obj
#0 c
#1 a
#2 d
#3 a
#4 a
#5 b
#6 b
#7 c
#8 c
#dtype: object
mask=obj.isin(['c','b'])
mask
#0 True
#1 False
#2 False
#3 False
#4 False
#5 True
#6 True
#7 True
#8 True
#dtype: bool
obj[mask]
#0 c
#5 b
#6 b
#7 c
#8 c
#dtype: objectDataFrame의 여러 컬럼에 대해 히스토그램을 구해야 하는 경우엔, 해당하는 DataFrame객체의 apply 메소드에 pd.data_counts를 부여하면 쉽게 원하는 값을 얻을 수 있다.
data = pd.DataFrame({"Qu1": [1, 3, 4, 3, 4],
"Qu2": [2, 3, 1, 2, 3],
"Qu3": [1, 5, 2, 4, 4]})
data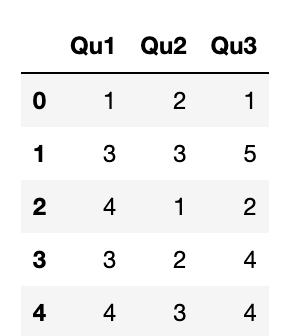
results=data.apply(pd.value_counts).fillna(0.0)
results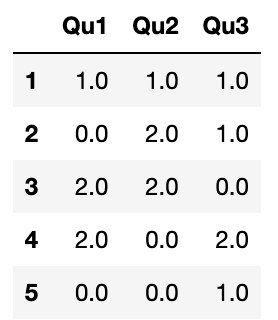
여기서 결괏값의 로우 라벨은 전체 컬럼의 유일한 값들을 담고 있다.value는 각 컬럼에서 해당 값이 몇 번 출력했는 지 나타내므로 히스토그램을 출력하기에 유용하다.
마치며
다음 로그에서는 pandas를 이용해서 데이터셋을 읽고 쓰는 도구를 다루도록 하겠다.
