중복된 값 제거하기
DataFrame에서 중복된 값을 가지는 row는 자주 발견될 수 있다.
DataFrame의 duplicated Method는 각 로우가 중복인지 아닌지 알려주는 불리언 Series를 반환하고, drop_duplicates Method는 duplicated의 반환 배열에서 False인 값들로 이루어진 DataFrame을 반환한다.
즉,
data = pd.DataFrame({'k1': ['one', 'two'] * 3 + ['two'],
'k2': [1, 1, 2, 3, 3, 4, 4]})
data.duplicated()
"""
0 False
1 False
2 False
3 False
3 two 3
4 one 3
5 two 4
"""이 두 메서드는 기본적으로 모든 컬럼에 적용되며, 중복을 찾아내기 위한 부분합을 따로 지정해줄 수도 있다.
새로운 컬럼을 하나 추가하고 'k1'컬럼을 기반해서 중복을 걸러내려면 다음과 같이 하면 된다.
data['v1']=range(7)
data.drop_duplicates('k1')
"""
k1 k2 v1
0 one 1 0
1 two 1 1
"""duplicated와 drop_duplicates는 기본적으로 처음 발견된 값을 유지한다.keep='last' 옵션을 넘기면 갱신되어 반환한다.
data.drop_duplicates(['k1','k2'],keep='last')
# k1 k2 v1
#0 one 1 0
#1 two 1 1
#2 one 2 2
#3 two 3 3
#4 one 3 4
#6 two 4 6함수나 매핑을 이용해서 데이터 변형하기
데이터를 다루다 보면 DataFrame의 컬럼이나 Series 배열 내의 값을 기반으로 데이터의 형태를 변환하고 싶은 경우가 있다. 이를 위해 가상으로 수집한 육류에 대한 DataFrame을 살펴보자.
data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon',
'Pastrami', 'corned beef', 'Bacon',
'pastrami', 'honey ham', 'nova lox'],
'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})여기에 해당 육류가 어떤 동물의 고기인지 알려줄 수 있는 컬럼을 하나 추가한다고 가정하고, 이를 위한 사전 데이터를 작성하자.
meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
}위 데이터는 육류 이름에 대소문자가 섞여 있는 문제가 있으므로 str.lower 메서드를 사용해서 모두 소문자로 대체한다. 물론 lambda func를 넘겨서 같은 일을 수행할 수도 있다.
이렇게하면 각 로우에 적절한 데이터가 mapping된 Series객체를 얻을 수 있다.
lowercased=data['food'].str.lower()
data['animal']=lowercased.map(meat_to_animal)
#data['food'].map(lambda x:meat_to_animal[x.lower()])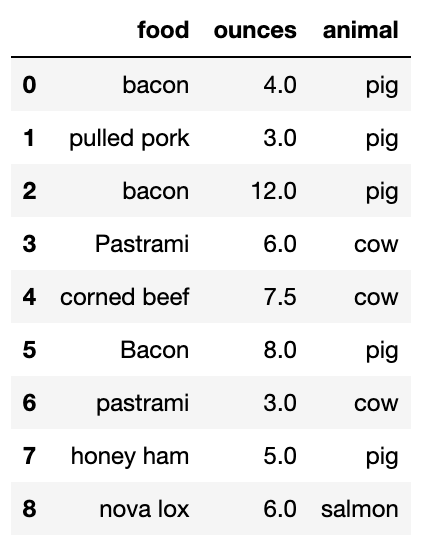
값 치환하기
fillna 메서드를 사용해서 누락된 값을 채우는 일이 일반적인 치환 작업이라고 볼 수 있다. 하지만, 이전 과정에서 fillna 메서드는 많이 다뤄봤으므로, replace 메서드로 값을 치환해보자. map 메서드는 한 객체 안에서 값의 부분집합을 변경하는데 사용했다면, replace는 같은 작업에 대해 더 간단하고 유연한 방법을 제공한다.
data = pd.Series([1., -999., 2., -999., -1000., 3.])-999는 누락된 데이터를 나타내기 위한 값이다. replace 메서드를 이용하면 이 값을 pandas에서 인식할 수 있는 NA 값으로 치환한 새로운 Series를 생성할 수 있다.
data.replace(-999.,np.nan)
#0 1.0
#1 NaN
#2 2.0
#3 NaN
#4 -1000.0
#5 3.0
#dtype: float64같은 출력값을 map, lambda를 활용하여 출력할 수 있다.
data.map(lambda x:np.nan if x==-999. else x)여러 개의 값을 한 번에 치환하려면 하나의 값 대신 치환하려는 값의 리스트를 넘기면 된다. 또, 치환하려는 값마다 다른 값으로 치환하려면 새로 지정할 값의 리스트를 사용하면 된다.(List 뭉치가 아닌 Dictionary를 이용하는 것도 가능하다)
data.replace([-999.,-1000],[np.nan,0.])
#data.replace({-999.:np.nan,-1000.:0.})
#0 1.0
#1 NaN
#2 2.0
#3 NaN
#4 0.0
#5 3.0
#dtype: float64index 이름 바꾸기
Series의 값들처럼 index 역시 유사한 방식으로 함수나 새롭게 바꿀 값을 이용해서 변환할 수 있다.
Series와 마찬가지로 축 색인에도 map 메서드가 있는데, 이를 활용해 변경된 index를 DataFrame에 바로 대입할 수 있다.
data = pd.DataFrame(np.arange(12).reshape((3, 4)),
index=['Ohio', 'Colorado', 'New York'],
columns=['one', 'two', 'three', 'four'])
data.index=data.index.map(lambda x:x[:4].upper())
data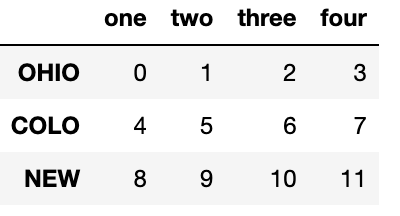
여기서 원래 객체를 변경하지 않고 새로운 객체를 생성하려면 rename 메서드를 사용하면 된다.
data.rename(index=str.title,columns=str.upper)
# ONE TWO THREE FOUR
#Ohio 0 1 2 3
#Colo 4 5 6 7
#New 8 9 10 11rename 메서드는 사전 형식의 객체를 이용해서 축 이름 중 일부만 변경하는 것도 가능하다. 또한, DataFrame을 직접 복사해서 index, columns 속성을 갱신할 필요 없이 바로 변경할 수 있다. 원본데이터를 바로 변경할려면 inplace= True 옵션을 넘겨주면 된다.
data.rename({'OHIO':'Indiana'},inplace=True)
data
# one two three four
#Indiana 0 1 2 3
#COLO 4 5 6 7
#NEW 8 9 10 11개별화와 양자화
연속성 데이터는 종종 '개별로 분할'하거나 아니면 분석을 위해 '그룹별(Category)로 나누기'도 하는데, 수업에 참여하는 학생 그룹 데이터가 있고, 나이대에 따라 분류한다고 하자. pandas의 cut 함수를 이용하면 나이대 그룹으로 나눌 수 있다.
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
bins = [18, 25, 35, 60, 100]
cats = pd.cut(ages, bins)
cats
pandas의 cut 함수가 반환하는 객체는 Categorical 이라는 특수한 객체인데, 이 객체는 '그룹(Category)이 담긴 배열'이라고 생각하면 된다. 이 객체와 value_counts 함수를 이용해서 그룹에 속하는 데이터 수를 구할 수 있다.
pd.value_counts(cats)
#(18, 25] 5
#(25, 35] 3
#(35, 60] 3
#(60, 100] 1
#dtype: int64'('와']'로 값이 닫혀있는걸 볼 수 있는데, 간격을 나타내는 표기법으로 소괄호 쪽은 값을 포함하지 않고, 대괄호 쪽은 값을 포함하는 것을 나타낸다. 이는 right=False 옵션을 넘겨 괄호의 방향을 반대로 바꿀 수 있다.
labels 옵션으로 그룹의 이름을 직접 넘겨줄 수도 있다. 아랫 코드에서는 그룹을 나누는 기준은 bins 변수의 리스트를 이용했고, 이렇게 구분된 그룹의 이름을 group_names로 부여하였다
group_names=['Youth','YouthAdult','MiddleAged','Senior']
m=pd.cut(ages,bins,labels=group_names)
pd.value_counts(m)
#Youth 5
#YouthAdult 3
#MiddleAged 3
#Senior 1
#dtype: int64만약 cut 함수에 명시적으로 그룹의 경곗값을 넘기지 않고 그룹의 개수를 넘겨주면 데이터에서 최솟값과 최댓값을 기준으로 균등한 길이의 그룹을 자동으로 계산하여 생성한다.
data=np.random.rand(20)
pd.cut(data,4,precision=2) #precision 옵션은 소수점 아래 2자리까지 제한함을 표현
#Categories (4, interval[float64, right]): [(0.028, 0.27] < (0.27, 0.5] < (0.5, #0.74] < (0.74, 0.98]]그룹의 분류를 자동으로 계산할 때는 qcut 함수를 이용하면 좋다. qcut은 표본 변위치를 기반으로 데이터를 나누기에 그룹마다 데이터 수가 다르게 나뉘는 경우가 적고, 적당히 같은 크기의 그룹으로 나눌 수 있는 장점이 있다.
data=np.random.rand(1000)
m=pd.qcut(data,4,precision=2)
pd.value_counts(m)
#(-0.009918, 0.27] 250
#(0.27, 0.51] 250
#(0.51, 0.78] 250
#(0.78, 1.0] 250
#dtype: int64그룹 분석과 변위치를 다룰 때는 qcut과 cut 함수 같은 이산함수가 특히 더 유용한데, 이 내용은 그룹 연산을 다루는 chapter 10에서 다루겠다.
이상값(Outlier)을 찾고 제외하기
배열 연산을 수행할 때는 특이값을 제외하거나 적당한 값으로 대체하는 것은 중요하다. 적절히 분산된 값이 담겨 있는 DataFrame을 살펴보자.
data=pd.DataFrame(np.random.randn(1000,4))
data.describe()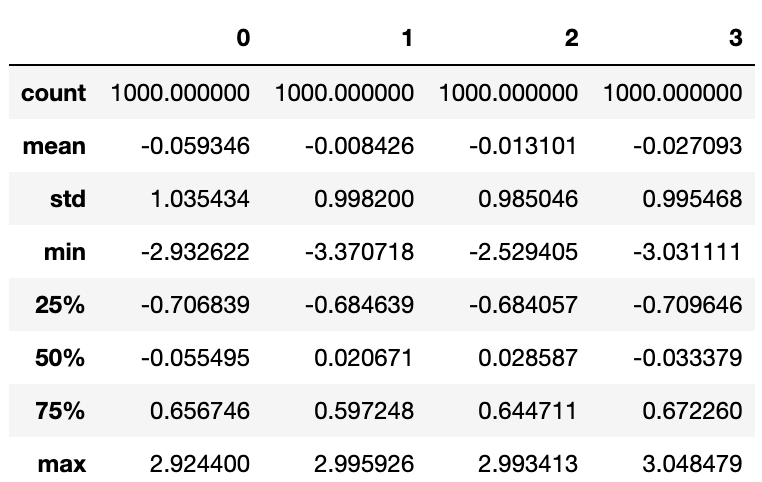
절댓값이 3을 초과하는 값이 들어 있는 모든 로우를 선택하려면 불리언 DataFrame에서 any 메서드를 사용하면 된다.
data[(np.abs(data)>3).any(1)]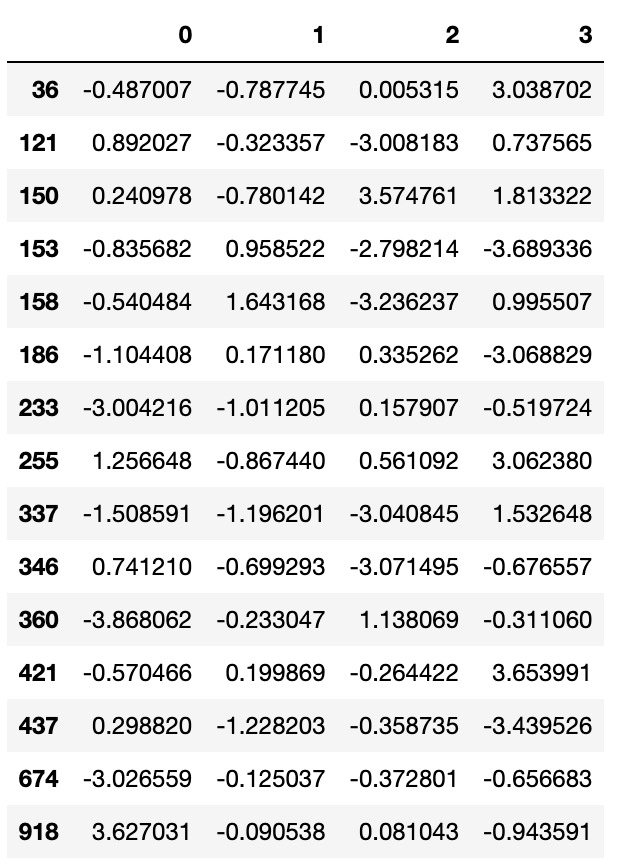
이 기준대로 쉽게 값을 선택할 수 있으며, 아래 코드로 -3이나 3을 초과하는 값을 -3.또는 3.으로 지정할 수 있다.
data[np.abs(data)>3]=np.sign(data)*3
data.describe()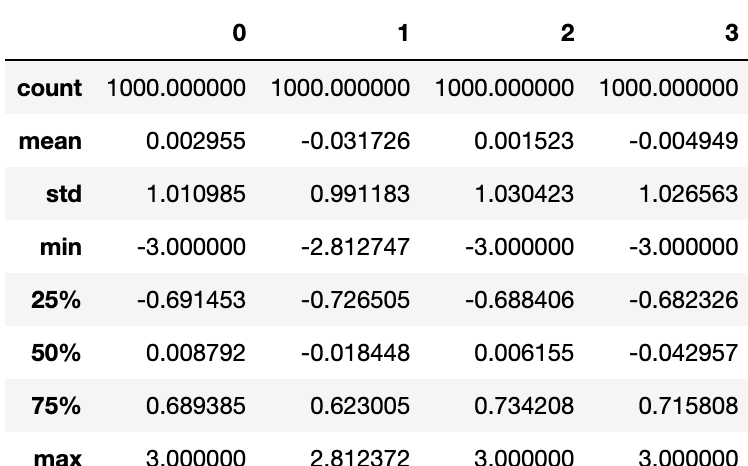
sign함수는 data값이 양수이면 1., 음수이면 -1.이 담긴 배열을 반환한다.
치환과 임의 샘플링
numpy.random.permutation 메서드를 이용하면 Series나 DataFrame의 로우를 쉽게 임의의 순서로 재배치(shuffle)할 수 있다.순서를 바꾸고 싶은 만큼의 길이를 permutation 함수로 넘기면 바뀐 순서가 담긴 정수 배열이 생성된다.
df=pd.DataFrame(np.arange(5*4).reshape((5,4)))
sampler=np.random.permutation(5)
sampler
#array([0, 2, 4, 1, 3])
df.take(sampler)
# 0 1 2 3
#0 0 1 2 3
#2 8 9 10 11
#4 16 17 18 19
#1 4 5 6 7
#3 12 13 14 15치환 없이 일부만 임의로 선택하려면 Series나 DataFrame의 sample 메서드를 사용하면 된다.
df.sample(n=3)
#0 1 2 3
#3 12 13 14 15
#2 8 9 10 11
#4 16 17 18 19
df.sample(n=300,replace=True)replace 옵션에 True값을 넘겨주면 반복 선택을 허용하며 표본을 생성해준다.
표시자/더미 변수 계산하기
통계 모델이나 머신러닝 애플리케이션을 위한 또 다른 데이터 변환은 분류값을 '더미'나 '표시자'행렬로 전환하는 것이다. 어떤 DataFrame의 한 컬럼에 k가지의 값이 있다면 k개의 컬럼이 있는 DataFrame이나 행렬을 만들고 값으로는 1과 0을 채울 것이다. pandas의 get_dummies가 이를 위한 함수이다.
df=pd.DataFrame({'key':['b','b','a','c','a','b'],'data1':range(6)})
# key data1
#0 b 0
#1 b 1
#2 a 2
#3 c 3
#4 a 4
#5 b 5
pd.get_dummies(df['key'])
# a b c
#0 0 1 0
#1 0 1 0
#2 1 0 0
#3 0 0 1
#4 1 0 0
#5 0 1 0두 DataFrame을 살펴보면 '한 컬럼에 k가지의 값이 있다면 k개의 컬럼이 있는'을 이해하는데 도움이 될 것이다.
표시자 DataFrame안에 있는 컬럼에 접두어를 추가한 후 다른 데이터와 병합하고 싶을 경우엔, get_dummies 함수의 prefix인자를 사용하면 이를 수행할 수 있다.
dummies=pd.get_dummies(df['key'],prefix='key')
df_with_dummy=df[['data1']].join(dummies)
df_with_dummy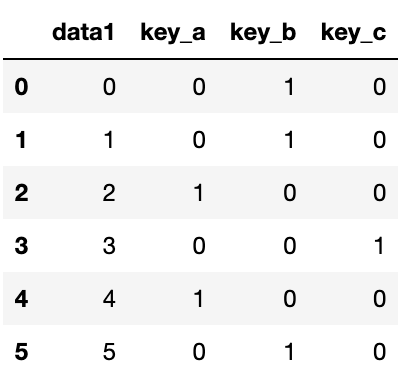
DataFrame의 한 로우가 여러 카테고리에 속한다면 복잡해지는데, 아래 영화 평점 데이터를 통해 살펴보자.
mnames=['movie_id','title','genres']
movies=pd.read_table('examples/movies.dat',sep='::',
header=None,names=mnames)
movies[:10]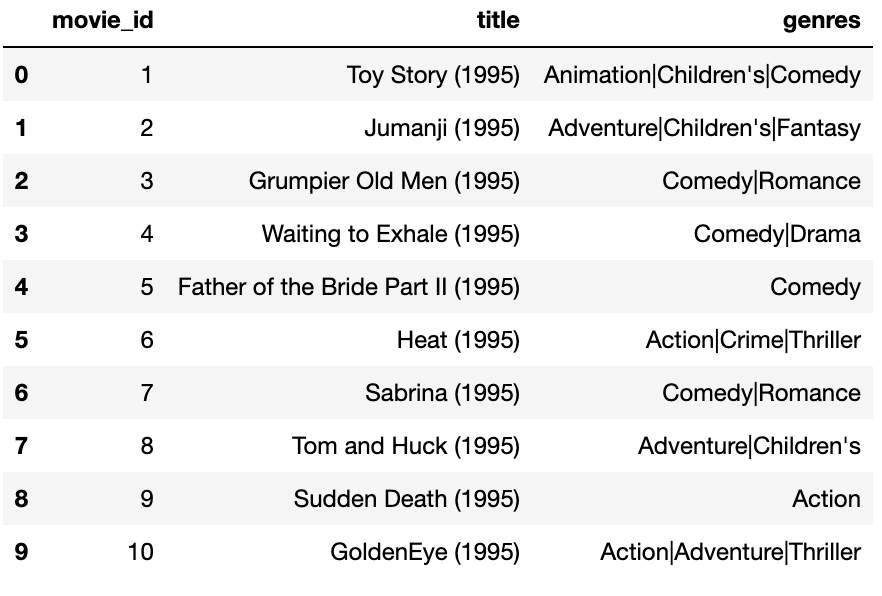 각 장르마다 표시자 값을 추가하려면 먼저 데이터 묶음에서 유일한 장르 목록을 추출해야 한다.
각 장르마다 표시자 값을 추가하려면 먼저 데이터 묶음에서 유일한 장르 목록을 추출해야 한다.
all_genres=[]
for x in movies.genres:
all_genres.extend(x.split('|'))
genres=pd.unique(all_genres)
genres
#array(['Animation', "Children's", 'Comedy', 'Adventure', 'Fantasy',
# 'Romance', 'Drama', 'Action', 'Crime', 'Thriller', 'Horror',
# 'Sci-Fi', 'Documentary', 'War', 'Musical', 'Mystery', 'Film-Noir',
# 'Western'], dtype=object)이제 표시자 DataFrame을 생성하기 위해 0으로 초기화된 DataFrame을 생성하자.
zero_matrix=np.zeros((len(movies),len(genres)))
dummies=pd.DataFrame(zero_matrix,columns=genres)
dummies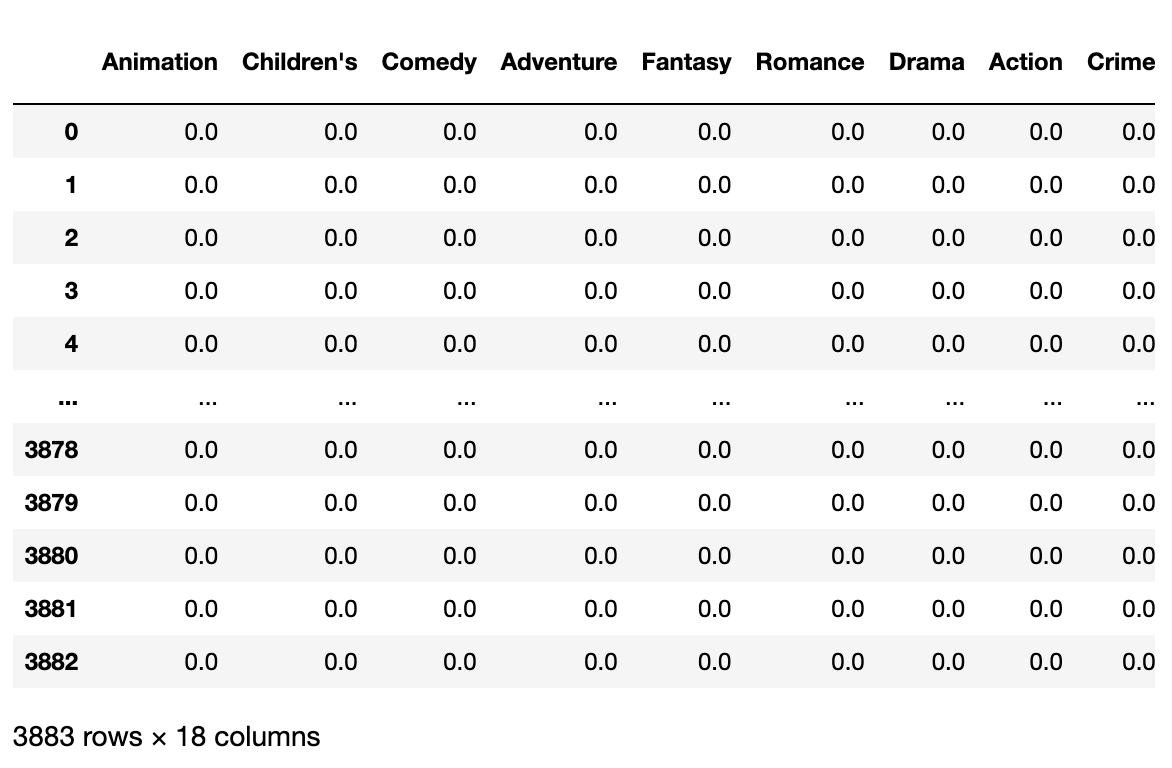
각 영화를 순회하면서 dummies의 각 로우의 항목을 1로 설정한다. 각 장르의 컬럼 색인을 계산하기 위해 dummies.columns를 이용하자.
gen = movies.genres[0]
gen.split('|')
dummies.columns.get_indexer(gen.split('|'))그리고 iloc를 이용해서 색인에 맞게 값을 대입하자.
for i, gen in enumerate(movies.genres):
indices = dummies.columns.get_indexer(gen.split('|'))
dummies.iloc[i, indices] = 1이제 앞에서 한 것처럼 movies와 조합하면 된다.
movies_windic = movies.join(dummies.add_prefix('Genre_'))
movies_windic.iloc[100]
pandas.get_dummies 함수는 이후에 다시 살펴볼 것이다.
마치며
이번 챕터에서 많은 도구들을 살펴봤지만 여기서 본 것들이 전부는 아니다.. 다음 장에서는 pandas의 데이터 병합과 그룹 기능을 살펴보겠다.
