대부분의 경우 데이터는 분석하기 쉽지 않은 형태로 기록되어 있다. 해당 Log에서는 데이터를 합치고, 재배열할 수 있는 도구들을 살펴보자.
계층적 색인(Hierarchical Indexing)
계층적 색인은 Pandas의 주요 기능 중 하나인데 축에 대해 다중 색인을 지원한다.
추상적으로 높은 차원의 데이터를 낮은 차원의 형식으로 다룰 수 있게 해주는 기능으로 볼 수도 있다.
import numpy as np
import pandas as pd
data=pd.Series(np.random.randn(9),
index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],
[1, 2, 3, 1, 3, 1, 2, 2, 3]])
data
"""
a 1 1.032027
2 -0.286479
3 1.518837
b 1 1.102585
3 0.045920
c 1 -1.307465
2 -0.340841
d 2 0.094178
3 0.834373
dtype: float64
"""지금 생성한 객체가 MultiIndex를 색인으로 하는 Series인데, 색인의 계층을 보여주고 있다. 바로 위 단계의 색인을 이용해서 하위 계층을 직접 접근할 수 있다.
data.index
"""
MultiIndex([('a', 1),
('a', 2),
('a', 3),
('b', 1),
('b', 3),
('c', 1),
('c', 2),
('d', 2),
('d', 3)],)
"""계층적으로 색인된 객체는 데이터의 부분집합을 부분적 색인으로 접근 하는 것이 가능하다. 하위 계층의 객체를 선택하는 것도 물론 가능하다.
data['b']
#1 1.102585
#3 0.045920
#dtype: float64
data['b':'c']
#b 1 1.102585
# 3 0.045920
#c 1 -1.307465
# 2 -0.340841
#dtype: float64
data.loc[['b','d']]
#b 1 1.102585
# 3 0.045920
#d 2 0.094178
# 3 0.834373
#dtype: float64
data.loc[:,2]
#a -0.286479
#c -0.340841
#d 0.094178
#dtype: float64계층적 색인은 데이터를 재형성하고 피벗테이블 생성 같은 그룹 기반의 작업을 할 때 중요하게 사용된다.
위에서 만든 DataFrame 객체에 unstack 메서드를 사용해서 데이터를 새롭게 배열할 수도 있다.
DataFrame에서는 두 축(index,columns) 모두 계층적 색인을 가질 수 있다. 동시에 계층적 색인의 각 단계는 이름을 가질 수 있고, 만약 이름을 가진다면 출력 시 함께 나타난다.
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
columns=[['Ohio', 'Ohio', 'Colorado'],
['Green', 'Red', 'Green']])
frame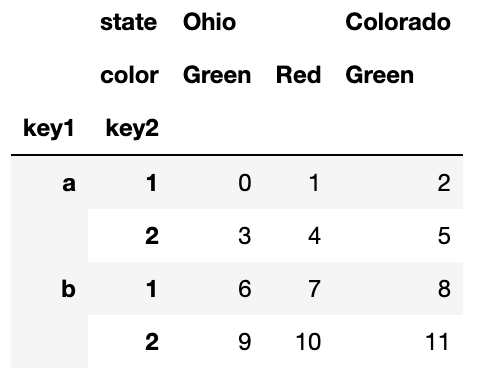
계층의 순서를 바꾸고 정렬하기
계층적 색인에서 계층의 순서를 바꾸거나 원하는 계층에 따라 데이터를 정렬해야 하는 경우가 있을 수 있다.
swaplevel Method를 넘겨받은 두 개의 계층이 뒤바뀐 새로운 객체(뷰)를 반환한다.
frame.swaplevel('key1','key2')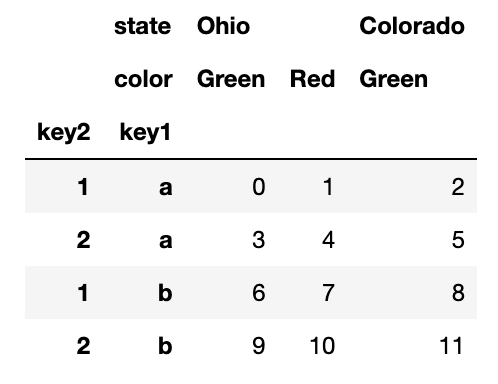 위 DataFrame은 계층을 바꾸는 것에 성공했지만, 오히려 더 정리되지 않은 느낌이 들 것이다.
이런 경우 sort_index( ) 를 사용하여 결과가 사전적으로 정렬되도록 만드는 것도 한 가지 방법이다.
위 DataFrame은 계층을 바꾸는 것에 성공했지만, 오히려 더 정리되지 않은 느낌이 들 것이다.
이런 경우 sort_index( ) 를 사용하여 결과가 사전적으로 정렬되도록 만드는 것도 한 가지 방법이다.
frame.swaplevel(0,1).sort_index(level=0)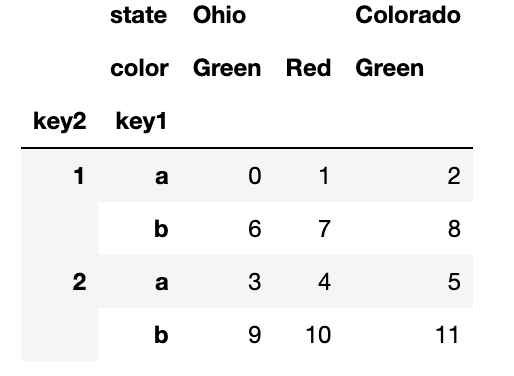
계층별 요약 통계
DataFrame와 Series는 level 옵션을 가지고 있는데. level은 '단계를 지정할 수 있는 옵션'이다. 이를 이용하여 앞에서 살펴본 DataFrame에서 로우나 컬럼을 아래처럼 계층별로 합할 수 있다.
frame.sum(level='key2') 컬럼으로도 물론 가능한데 axis 값을 지정해주어야 한다.
컬럼으로도 물론 가능한데 axis 값을 지정해주어야 한다.
frame.sum(level='color',axis=1)
이는 내부적으로 pandas의 groupby기능을 이용해서 구현했는데, 관련해서는 해당 링크에서 다루었다.
DataFrame의 컬럼 사용하기
DataFrame에서 index를 선택하기 위한 색인으로 하나 이상의 컬럼을 사용하거나, row의 색인을 DataFrame의 컬럼으로 옮기고 싶을 때는 어떻게 해야할까?
frame = pd.DataFrame({'a': range(7), 'b': range(7, 0, -1),
'c': ['one', 'one', 'one', 'two', 'two',
'two', 'two'],
'd': [0, 1, 2, 0, 1, 2, 3]})
frame
# a b c d
#0 0 7 one 0
#1 1 6 one 1
#2 2 5 one 2
#3 3 4 two 0
#4 4 3 two 1
#5 5 2 two 2
#6 6 1 two 3DataFrame의 set_index 함수는 하나 이상의 컬럼을 색인으로 하는 새로운 DataFrame을 생성한다.
drop옵션에 False 값을 넘겨주지 않으면, 옮겨진 색인은 컬럼에서 삭제된다.
frame.set_index(['c','d'],drop=False,,inplace=True)
reset_index는 set_index와 반대되는 개념으로 계층적 색인이 컬럼으로 다시 이동한다.
frame2=frame.set_index(['c','d'])
frame2.reset_index()
마치며
이번 로그에서 계층적 색인에 대해서 알아보았다. 다음 로그에서는 데이터를 변형 시키는법을 배워보는 시간을 가져보겠다.
