DataFrame Merging
pandas 객체에 저장된 데이터는 여러 가지 방법으로 합칠 수 있다.
| 메서드 | 설명 |
|---|---|
| merge | 하나 이상의 키를 기준으로 DataFrame의 로우를 합친다. |
| concat | 하나의 축을 따라 객체를 이어붙인다. |
| combine_first | 두 객체를 포개서 한 객체에서 누락된 데이터를 다른 객체 있는 값으로 채울 수 있도록 한다. |
DB style로 DataFrame 합치기
병합(Merge)연산은 데이터베이스의 핵심적인 연산인데, 하나 이상의 키를 사용해서 데이터 집합의 로우를 합친다. merge 함수를 이용해서 아래와 같은 알고리즘을 데이터에 적용할 수 있다.
df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1': range(7)})
df2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data2': range(3)})
df1
"""
key data1
0 b 0
1 b 1
2 a 2
3 c 3
4 a 4
5 a 5
6 b 6
"""
df2
"""
key data2
0 a 0
1 b 1
2 d 2
"""위 코드를 병합하는 것은 다대일의 경우다.
df1의 데이터는 key 컬럼에 여러 개의 값(a,b,d)를 가지고 있고, df2는 key 컬럼에 유일값(unique)만을 가지고 있다.
이 객체에 대해 merge함수를 호출하면 다음과 같은 결과를 얻는다.
어떤 컬럼을 병합할 것인지는 '중복시킬 컬럼 이름'을 on option에 넘겨주면 된다. 우리는 key column을 기준으로 두 DataFrame을 병합할 것이다.
pd.merge(df1,df2,on='key')
"""
key data1 data2
0 b 0 1
1 b 1 1
2 b 6 1
3 a 2 0
4 a 4 0
5 a 5 0
"""만약 두 객체에 중복된 컬럼 이름이 하나도 없다면 따로 '무엇을 중복된 컬럼으로 설정한 것인지'를 left_on,right_on 인자로 지정해주면 된다.
df3=pd.DataFrame({'lkey':['b','b','a','c','a','a','b'],
'data1':range(7)})
df4 = pd.DataFrame({'rkey': ['a', 'b', 'd'],
'data2': range(3)})
pd.merge(df3,df4,left_on='lkey',right_on='rkey')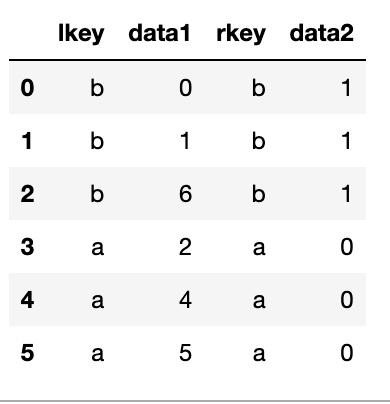
결과를 보면, 'c'와 'd'에 해당하는 값이 빠진 것을 알 수 있다. merge 함수는 기본적으로 '내부조인(inner)'을 수행하여 교집합인 결과를 반환하기 때문이다. how 인자로 'left','right','outer'를 넘겨서 왼쪽, 오른쪽, 외부 조인을 수행할 수도 있다.
pd.merge(df3,df4,left_on='lkey',right_on='rkey',how='outer')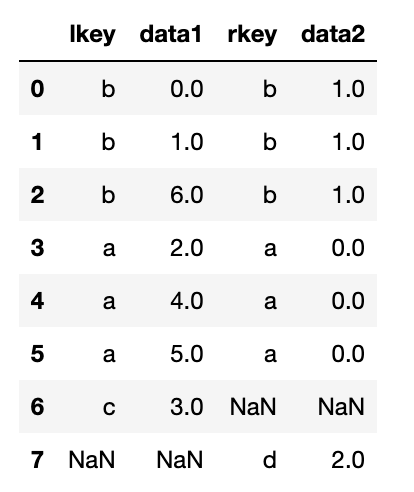
다대다 병합은 비교적 직관적이지 않다.
df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],
'data1': range(6)})
df2 = pd.DataFrame({'key': ['a', 'b', 'a', 'b', 'd'],
'data2': range(5)})
pd.merge(df1, df2, on='key', how='left')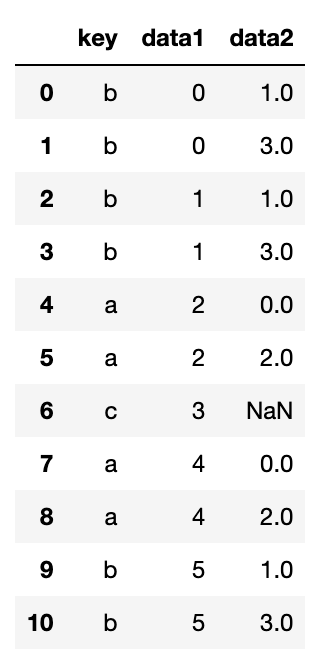
다대다 조인은 두 로우의 데카르트곱을 반환한다.
여러 개의 키를 병합할려면 컬럼이름이 담긴 리스트를 넘기면 된다.
left = pd.DataFrame({'key1': ['foo', 'foo', 'bar'],
'key2': ['one', 'two', 'one'],
'lval': [1, 2, 3]})
# key1 key2 lval
#0 foo one 1
#1 foo two 2
#2 bar one 3
right = pd.DataFrame({'key1': ['foo', 'foo', 'bar', 'bar'],
'key2': ['one', 'one', 'one', 'two'],
'rval': [4, 5, 6, 7]})
# key1 key2 lval
#0 foo one 4
#1 foo one 5
#2 bar one 6
#3 bar two 7
pd.merge(left, right, on=['key1', 'key2'], how='outer')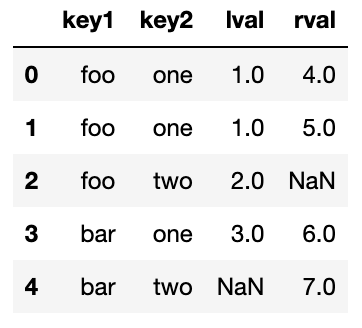
병합 연산에서 고려해야할 마지막 사항은 겹치는 컬럼 이름에 대한 처리이다.
축 이름을 변경해서 수동으로 컬럼 이름이 겹치게 할 수도 있고,merge 함수의 suffixes 인자로 두 DF객체에서 겹치는 컬럼 이름 뒤에 붙일 문자열을 지정해줄 수도 있다.
pd.merge(left,right,on='key1',suffixes=('_left','_right'))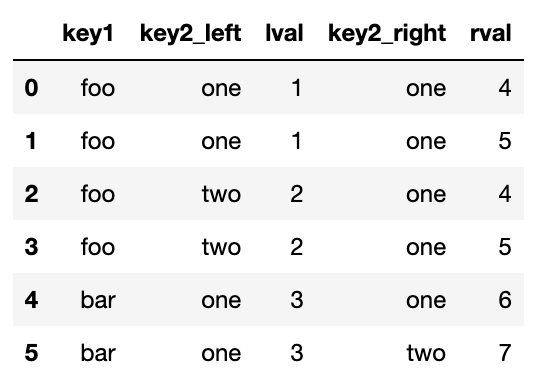
index 병합하기
병합하려는 키가 DataFrame의 index일 경우가 있다. 이런 경우에는 left_index=True 혹은 right_index=True 옵션(혹은 둘다)를 지정해서 해당 색인을 병합키로 사용할 수 있다.
left1=pd.DataFrame({'key':['a','b','a','a','b','c'],
'value':range(6)})
left1
"""
key value
0 a 0
1 b 1
2 a 2
3 a 3
4 b 4
5 c 5
"""
right1=pd.DataFrame({'group_val':[3.5,7]},index=['a','b'])
right1
"""
group_val
a 3.5
b 7.0
"""
pd.merge(left1,right1,left_on='key',right_index=True,how='outer')
"""
key value group_val
0 a 0 3.5
2 a 2 3.5
3 a 3 3.5
1 b 1 7.0
4 b 4 7.0
5 c 5 NaN
"""계층 색인된 데이터는 사실상 여러 키를 병합하는 것이라 더 복잡하다.
lefth=pd.DataFrame({'key1':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'key2':[2000,2001,2002,2001,2002],
'data':np.arange(5.)})
lefth
"""
key1 key2 data
0 Ohio 2000 0.0
1 Ohio 2001 1.0
2 Ohio 2002 2.0
3 Nevada 2001 3.0
4 Nevada 2002 4.0
"""
righth=pd.DataFrame(np.arange(12).reshape((6,2)),index=[['Nevada','Nevada','Ohio','Ohio','Ohio','Ohio'],
[2001,2000,2000,2000,2001,2002]],
columns=['event1','event2'])
righth
"""
event1 event2
Nevada 2001 0 1
2000 2 3
Ohio 2000 4 5
2000 6 7
2001 8 9
2002 10 11
"""계층 색인된 데이터를 병합하려는 키로 사용할 때는, 리스트로 여러 개의 컬럼을 지정해서 병합해야한다.
pd.merge(lefth,righth,left_on=['key1','key2'],right_index=True,
how='outer',)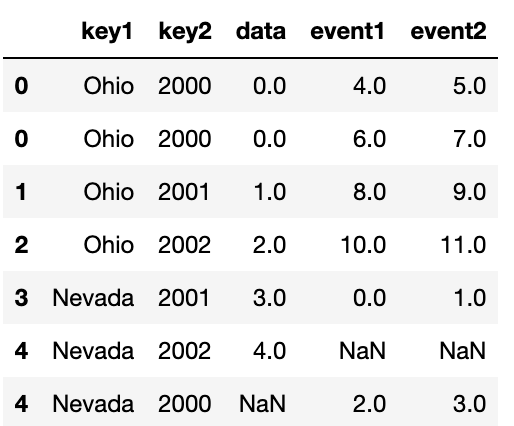
양쪽에 공통적으로 존재하는 index을 병합하는 것도 가능하다.
left2 = pd.DataFrame([[1., 2.], [3., 4.], [5., 6.]],
index=['a', 'c', 'e'],
columns=['Ohio', 'Nevada'])
left2
"""
Ohio Nevada
a 1.0 2.0
c 3.0 4.0
e 5.0 6.0
"""
right2 = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [13, 14]],
index=['b', 'c', 'd', 'e'],
columns=['Missouri', 'Alabama'])
right2
"""
Missouri Alabama
b 7.0 8.0
c 9.0 10.0
d 11.0 12.0
e 13.0 14.0
"""
pd.merge(left2,right2,how='outer',left_index=True,right_index=True)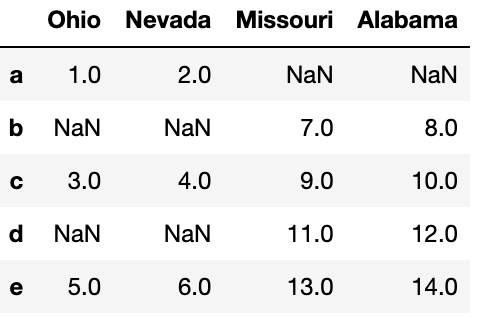
index로 DataFrame을 병합할 때 join 메서드를 사용하면 편리하다. join 메서드는 컬럼이 겹치지 않으며, 완전히 같거나 유사한 구조를 가진 여러 개의 DataFrame 객체를 병합할 때 유용하게 쓰인다.
고로, 아래 코드는 merge를 활용한 윗 코드와 출력값이 같다.
left2.join(right2,how='outer')join 메서드를 호출한 DataFrame의 컬럼 중 하나에 대한 조인을 수행하는 것도 가능하다. 이전에 생성한 DataFrame 객체로 살펴보자.
left1
# key value
#0 a 0
#1 b 1
#2 a 2
#3 a 3
#4 b 4
#5 c 5
right1
# group_val
#a 3.5
#b 7.0
left1.join(right1,on='key')축 따라 이어붙이기(concat)
데이터를 합치는 또 다른 방법으로 이어붙이기가 있다.Numpy는 ndarray를 이어붙이는 concatenate함수를 제공한다.
arr=np.arange(12).reshape((3,4))
arr
#array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
np.concatenate([arr,arr],axis=1)
#array([[ 0, 1, 2, 3, 0, 1, 2, 3],
# [ 4, 5, 6, 7, 4, 5, 6, 7],
# [ 8, 9, 10, 11, 8, 9, 10, 11]])Series나 DataFrame 같은 pandas 객체의 내부에는 축(Index, column)마다 이름이 있어서 배열을 쉽게 이어붙일 수 있도록 되어있다. 그렇다고 막 이어붙이면 안되고, 다음 3가지 사향을 고려해 볼 필요가 있다.
1) 만약 연결하려는 두 객체의 index가 서로 다르면,결과는 그 색인의 교집합으로 할 것인가, 합집합으로 할 것인가.
2) 합쳐진 결과에서 합쳐지기 전 객체의 데이터를 구분할 수 있어야 하는가.
3) 어떤 축으로 연결할 것인지 고려해야 하는가.
pandas의 concat 함수는 위 사항에 대한 답을 제공해준다.
concat 함수의 동작 방식을 다양한 예제로 알아보자.
s1 = pd.Series([0, 1], index=['a', 'b'])
s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e'])
s3 = pd.Series([5, 6], index=['f', 'g'])
pd.concat([s1,s2,s3])
"""
a 0
b 1
c 2
d 3
e 4
f 5
g 6
dtype: int64
"""보다시피 concat 함수는 Index(axis=0)을 기본값으로 하여 새로운 Series객체를 생성한다. 만약 axis=1을 넘긴다면 결과는 DataFrame이 될 것이다.
pd.concat([s1,s2,s3],axis=1)
"""
0 1 2
a 0.0 NaN NaN
b 1.0 NaN NaN
c NaN 2.0 NaN
d NaN 3.0 NaN
e NaN 4.0 NaN
f NaN NaN 5.0
g NaN NaN 6.0
"""겹치는 축이 없기 때문에 outer로 조인된 합집합을 얻었지만, inner를 넘겨서 교집합을 구할 수도 있다.
또, join_axis 인자로 병합하려는 축을 직접 지정해줄 수도 있다.
s4=pd.concat([s1,s3])
s4
"""
a 0
b 1
f 5
g 6
dtype: int64
"""
pd.concat([s1,s4],axis=1,join='inner')
"""
0 1
a 0 0
b 1 1
"""Series를 이어붙이기 이전의 개별 Series를 구분할 수 없는 문제가 생기는데, 이어붙인 축에 대해 계층적 색인을 생성하여 식별이 가능하도록 할 수 있다. 계층적 색인을 생성하려면 keys option을 사용하면 된다.
result=pd.concat([s1,s1,s3])
result
"""
a 0
b 1
a 0
b 1
f 5
g 6
dtype: int64
"""
result=pd.concat([s1,s1,s3],keys=['one','two','three'])
result
"""
one a 0
b 1
two a 0
b 1
three f 5
g 6
dtype: int64
"""
result.unstack()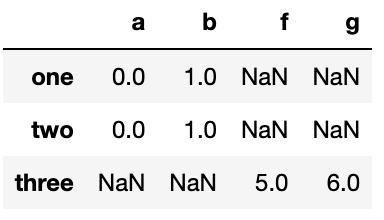
Series를 axis=1로 병합할 경우 keys는 DataFrame의 컬럼 제목이 된다.
result=pd.concat([s1,s2,s3],keys=['one','two','three'],axis=1)
result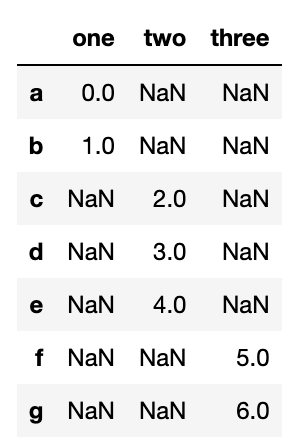
DataFrame 객체에 대해서도 같은 방식으로 동작한다.
df1 = pd.DataFrame(np.arange(6).reshape(3, 2), index=['a', 'b', 'c'],
columns=['one', 'two'])
df1
"""
one two
a 0 1
b 2 3
c 4 5
"""
df2 = pd.DataFrame(5 + np.arange(4).reshape(2, 2), index=['a', 'c'],
columns=['three', 'four'])
df2
"""
three four
a 5 6
c 7 8
"""
pd.concat([df1,df2])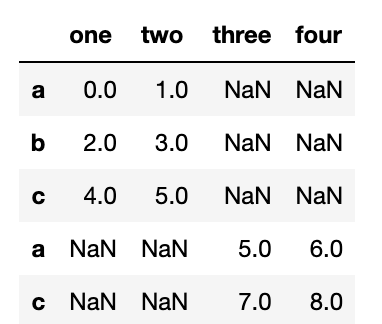
해당 옵션을 추가하면 왜 DataFrame이 이러한 형태를 띄게 되는지 생각해보자.
pd.concat([df1,df2],axis=1,keys=['level 1','level 2'])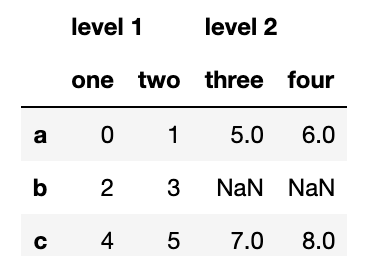
리스트 대신 객체의 사전을 넘기면 사전의 키가 keys 옵션으로 설정된다.
pd.concat({'level1': df1, 'level2': df2}, axis=1)
#출력 결과는 위 DataFrame과 같음계층적 색인을 생성할 때 사용할 수 있는 concat의 몇 가지 추가적인 옵션(names,axis,keys,ignore_index)를 살펴보자.
names argu는 새로 생성된 계층의 이름을 부여할 수 있다
df1 = pd.DataFrame(np.random.randn(3, 4), columns=['a', 'b', 'c', 'd'])
df1
"""
a b c d
0 0.125533 -0.363324 -0.934662 0.258113
1 -1.318268 -0.993006 0.225923 0.859837
2 0.239863 0.288860 -0.955775 0.164556
"""
df2 = pd.DataFrame(np.random.randn(2, 3), columns=['b', 'd', 'a'])
df2
"""
b d a
0 -0.898771 0.046002 0.578060
1 -1.898313 0.840996 -0.369377
"""
pd.concat([df1,df2])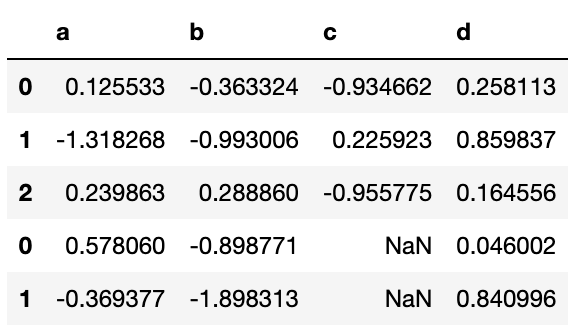
DataFrmae의 로우 색인이 분석에 필요 없는 경우에 ignore_index=True로 설정해주면 된다.
pd.concat([df1,df2],ignore_index=True)ignore_index 옵션을 추가하기 전과 후, DataFrame에 어떠한 차이가 나타나는지 생각해보자.
겹치는 데이터 합치기
두 데이터셋의 index가 일부 겹칠 경우 두 DataFrame을 병합하기 곤란할 수 있다.
이 경우, 벡터화된 if-else 구문을 표현하는 Numpy의 where 함수로 해결할 수 있다.
a = pd.Series([np.nan, 2.5, np.nan, 3.5, 4.5, np.nan],
index=['f', 'e', 'd', 'c', 'b', 'a'])
a
"""
f NaN
e 2.5
d NaN
c 3.5
b 4.5
a NaN
dtype: float64
"""
b = pd.Series(np.arange(len(a), dtype=np.float64),
index=['f', 'e', 'd', 'c', 'b', 'a'])
b[-1] = np.nan
b
"""
f 0.0
e 1.0
d 2.0
c 3.0
b 4.0
a NaN
dtype: float64
"""
np.where(pd.isnull(a),b,a) # a 배열의 값이 null인 경우 b 배열 값을 선택
#array([0. , 2.5, 2. , 3.5, 4.5, nan])Series의 객체의 combine_first 메서드는 위와 동일한 연산을 제공하며 데이터 정렬 기능까지 있다.
b[:2].combine_first(a[2:])
#a NaN
#b 4.5
#c 3.5
#d NaN
#e 1.0
#f 0.0
#dtype: float64DataFrame에서 combine_first 메서드는 컬럼에 대해 똑같이 동작한다.그러므로 '호출하는 객체에서 누락된 데이터'를 '인자로 넘긴 객체에 있는 값'으로 채워 넣을 수 있다.
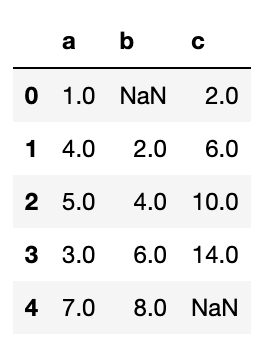
df1 = pd.DataFrame({'a': [1., np.nan, 5., np.nan],
'b': [np.nan, 2., np.nan, 6.],
'c': range(2, 18, 4)})
df1
"""
a b c
0 1.0 NaN 2
1 NaN 2.0 6
2 5.0 NaN 10
3 NaN 6.0 14
"""
df2 = pd.DataFrame({'a': [5., 4., np.nan, 3., 7.],
'b': [np.nan, 3., 4., 6., 8.]})
df2
"""
a b
0 5.0 NaN
1 4.0 3.0
2 NaN 4.0
3 3.0 6.0
4 7.0 8.0
"""
df1.combine_first(df2)