Pivot Table
Pivot Table은 데이터를 하나 이상의 키로 수집해서 어떤 키는 로우에, 어떤 키는 컬럼에 나열해서 데이터를 정렬시킨다.
pandas에서 피벗테이블은 groupby 기능을 사용해서 계층적 색인을 활용한 재형성 연산이 가능하다. 또한, groupby를 위한 편리한 인터페이스를 제공하기 위해 pivot_table은 마진이라고 하는 부분합을 추가하는 기능을 제공한다.
팁 데이터를 이용해서 요일(day)와 흡연자(smoker) 집단에서 평균을 구하기위해
팁 데이터를 불러오자.
tips=pd.read_csv('examples/tips.csv')
tips['tip_pct']=tips['tip']/tips['total_bill']
tips.pivot_table(index=['day','smoker'])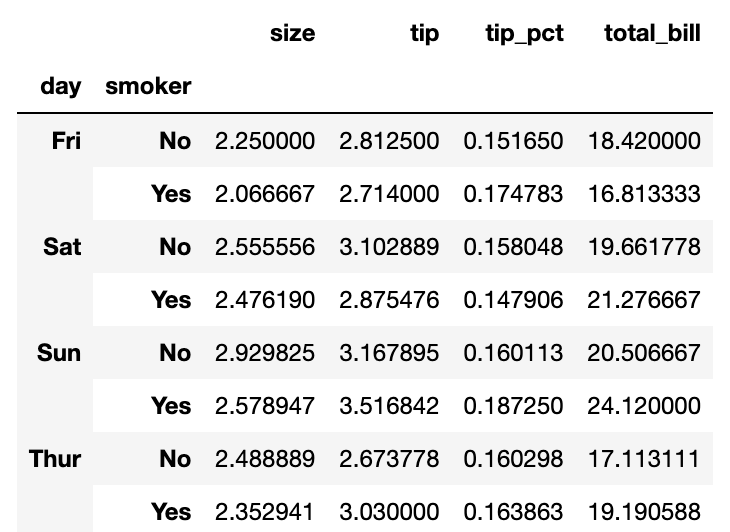
이는 groupby를 사용해서 쉽게 구할 수 있는데, tip_pct와 size에 대해서만 집계를 하고 날짜 별로 그룹 지어보자.
tips.pivot_table(['tip_pct','size'],
index=['time','day'],
columns='smoker')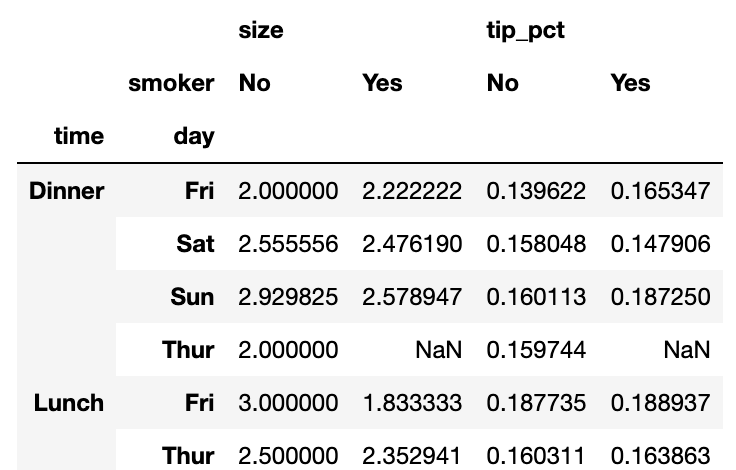
이 테이블은 margins=True를 넘겨서 부분합을 포함하도록 확장할 수 있는데, 그렇게하면 All 컬럼과 로우가 추가되어 단일 줄 안에서 그룹 통계를 얻을 수 있다.
tips.pivot_table(['tip_pct','size'],
index=['time','day'],
columns='smoker',margins=True)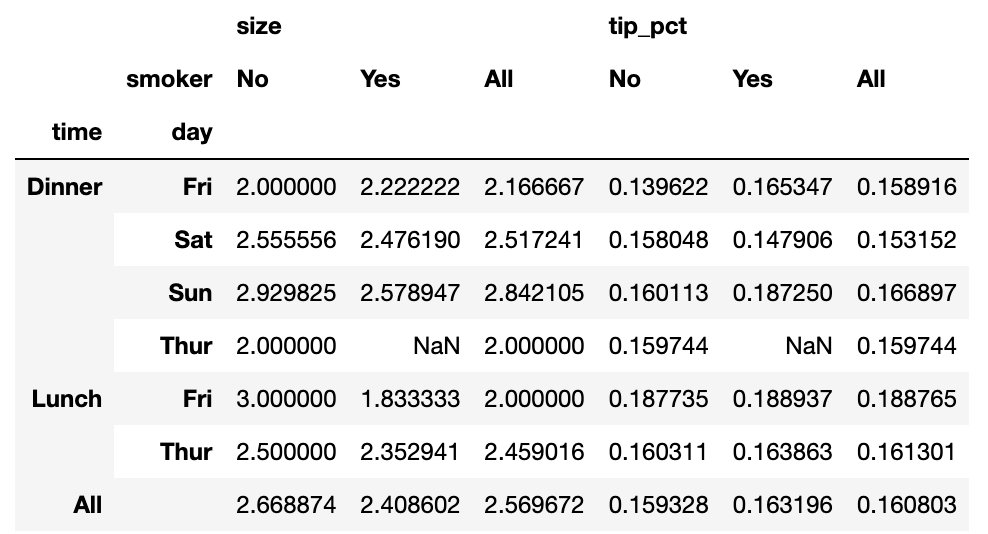
다른 집계함수를 사용하려면 aggfunc로 넘기면 된다.
예를들어, 'count'나 len 함수는 그룹 크기의 교차일람표를 반환한다.
tips.pivot_table('tip_pct',
index=['time','smoker'],
columns='day',
aggfunc=len,
margins=True)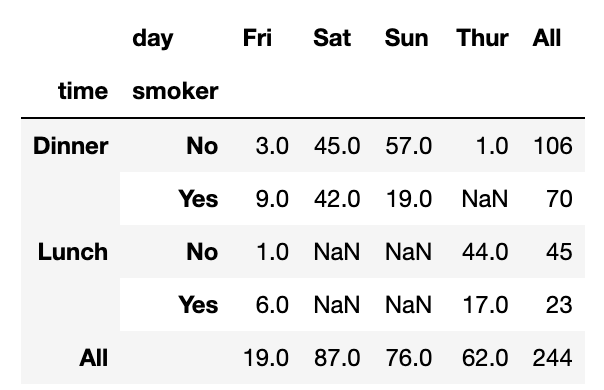
pivot_table에 fill_value 옵션을 넘길 수도 있다.
tips.pivot_table('tip_pct',
index=['time','smoker'],
columns='day',
aggfunc=len,
margins=True,
fill_value=0)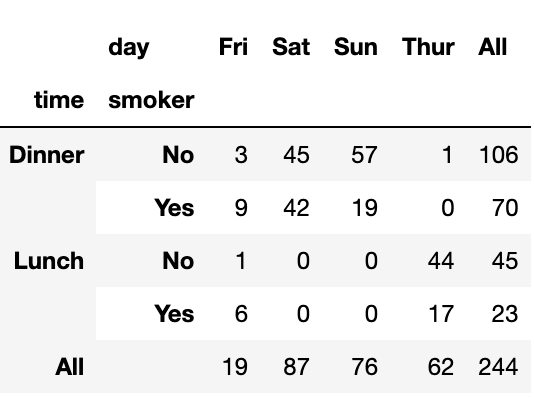
이외에 자주 쓰이는 pivot_table 메서드이자 옵션을 요약해두었다.
| 함수 | 설명 |
|---|---|
| values | 기본적으로 모든 숫자 컬럼을 집계한다. |
| index | 피벗테이블의 로우를 그룹으로 묶을 컬럼 이름이나 그룹 키 |
| columns | 피벗테이블의 컬럼을 그룹으로 묶을 컬럼 이름이나 그룹 키 |
| aggfunc | 집계함수나 함수 리스트를 데이터에 적용하여 반환한다. |
| fill_value | 결과 테이블에서 누락된 값을 대체하기 위한 값 |
| dropna | True인 경우 모든 항목이 Na인 컬럼은 포함하지 않는다 |
| margins | 부분합이나 총계를 담기위한 로우/컬럼을 추가할지 여부 |
Crosstab
교차일람표(Crosstab)는 그룹 빈도를 계산하기 위한 피벗테이블의 특수한 경우다.
다음 간단한 데이터를 바탕으로 생각해보자.
data = """\
Sample Nationality Handedness
1 USA Right-handed
2 Japan Left-handed
3 USA Right-handed
4 Japan Right-handed
5 Japan Left-handed
6 Japan Right-handed
7 USA Right-handed
8 USA Left-handed
9 Japan Right-handed
10 USA Right-handed
"""
data = pd.read_table(data), sep='\s+')
data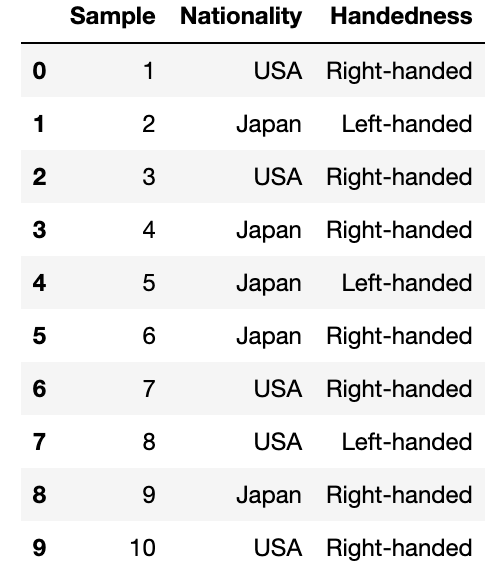 이 데이터를 Nationality와 Handedness에 따라 요약해보자. 이를 위해 pivot_table의 메서드를 활용할 수도 있지만, pandas.crosstab 함수가 훨씬 편리하다.
이 데이터를 Nationality와 Handedness에 따라 요약해보자. 이를 위해 pivot_table의 메서드를 활용할 수도 있지만, pandas.crosstab 함수가 훨씬 편리하다.
pd.crosstab(data.Nationality,data.Handedness,margins=True)
"""
data.pivot_table(index='Nationality',
columns='Handedness',
aggfunc='count',
margins=True)
"""crosstab 함수의 처음 두 인자는 배열이나 Series 혹은 배열의 리스트가 될 수 있다. 팁 데이터에 대해 교차표를 구해보자.
pd.crosstab([tips.time,tips.day],tips.smoker,margins=True)
마치며
pandas의 data grouping 도구를 마스터하면 Data cleansing, modelling 뿐만아니라 통계 분석 작업에도 도움이 될 것이다. 그정도로 매우 유용하면서 동시에 중요한 도구이다. chapter 14에서 실제 데이터에 대한 groupby 적용 사례를 살펴보자. 다음 장에서는 시계열 데이터를 알아보자.
