데이터 집계(Data Aggregation)는 배열로부터 스칼라값을 만들어내는 모든 데이터 변환 작업을 말한다.
일반적인 데이터 집계 method는 데이터 묶음에 통계를 계산해내는 최적화된 구현을 가지고 있다. 이때, 모든 함수에서 NA값은 무시한다.
| METOD | EXPLANATION |
|---|---|
| count | 그룹에서 값의 수를 반환한다. |
| sum | 값들의 합을 구한다. |
| mean | 값들의 평균을 구한다. |
| median | 값들의 산술 중간값을 구한다. |
| std,var | 편항되지 않은 (n-1을 분모로 하는) 표준편차와 분산 |
| min,max | 값들 중 최솟값과 최댓값 |
| prod | 값들의 곱 |
| first,last | 값들 중 첫째 값과 마지막 값 |
하지만, 이 메서드만 사용해야 하는 건 아니다.
직접 고안한 집계 함수를 사용하고 추가적으로 그룹 객체에 이미 정의된 메서드를 연결해서 사용하는 것도 가능하다.
예를들어, quantile 메서드가 Series나 DataFrame의 column의 변위치를 계산한다는 점을 생각해보자. quantile 메서드는 GroupBy를 위해 구현된 것이 아닌 Series 메서드이지만, 여기서 사용할 수 있다.
df
"""
key1 key2 data1 data2
0 a one -0.204708 1.393406
1 a two 0.478943 0.092908
2 b one -0.519439 0.281746
3 b two -0.555730 0.769023
4 a one 1.965781 1.246435
"""
grouped=df.groupby('key1')
grouped['data1'].quantile(0.9)
"""
key1
a 1.668413
b -0.523068
Name: data1, dtype: float64
"""자신만의 데이터 집계함수를 사용하려면 배열의 aggregate나 agg에 해당 함수를 넘기면 된다.
def peak_to_peak(arr):
return arr.max() - arr.min()
grouped.agg(peak_to_peak)
"""
data1 data2
key1
a 2.170488 1.300498
b 0.036292 0.487276
"""단, 사용자 정의 집계함수는 GroupBy 객체를 위한 집계함수들 보다 무척 느리게 동작하므로 주의하자.
describe 같은 메서드도 데이터를 집계하지 않는데도 잘 작동한다.
column에 여러 가지 함수 적용하기
예시를 위해 팁 데이터를 read_csv 함수로 불러온 다음, 팁의 비율을 담기 위한 컬럼이 tip_pct를 추가했다.
tips=pd.read_csv('examples/tips.csv')
tips['tip_pct']=tips['tip']/tips['total_bill']
tips.head()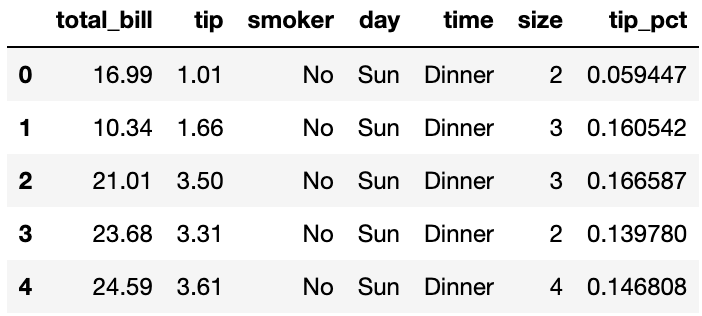
Series나 DataFrame의 모든 column을 aggregation하는 것은 mean이나 std 같은 메서드를 호출하거나 원하는 함수에 aggregate를 사용하는 것이다.
하지만, 컬럼에 따라 다른 함수를 사용해서 집계를 수행하거나, 여러개의 함수를 한 번에 적용하는 것도 가능하다. tips DataFrame을 살펴보며 확인해보자.
grouped=tips.groupby(['day','smoker'])
grouped_pct=grouped['tip_pct']
grouped_pct.agg('mean')
#grouped_pct.mean()
"""
day smoker
Fri No 0.151650
Yes 0.174783
Sat No 0.158048
Yes 0.147906
Sun No 0.160113
Yes 0.187250
Thur No 0.160298
Yes 0.163863
Name: tip_pct, dtype: float64
#계층적 색인이 사용된 Series 객체
"""만일 함수 목록이나 함수 이름을 넘기면, 함수 이름을 컬럼 이름으로 하는 DataFrame을 얻게된다.
그렇다고 해서 GroupBy 객체에서 자동으로 지정하는 컬럼 이름을 그대로 쓰지 않아도 된다. 컬럼 이름을 따로 지정해주고 싶으면, (name,function) 튜플의 리스트를 넘기면 된다.
grouped_pct.agg(['mean','std',peak_to_peak])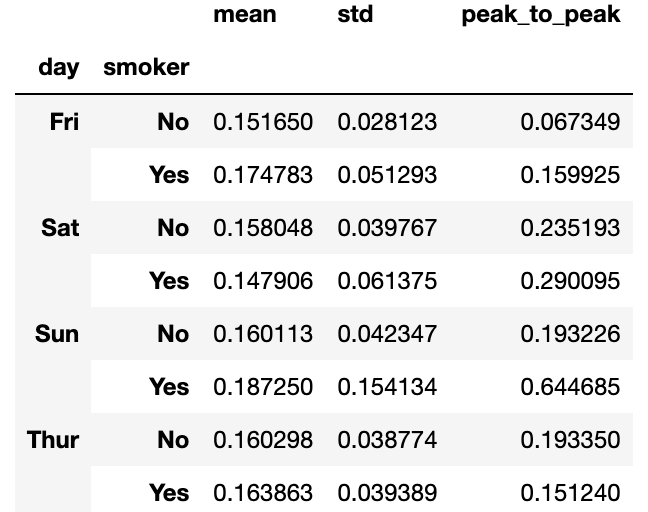
여기서는 데이터 그룹에 대해 독립적으로 적용하기 위해 agg에 집계함수들의 리스트를 넘겼다.
grouped_pct.agg([('foo', 'mean'), ('bar', np.std)])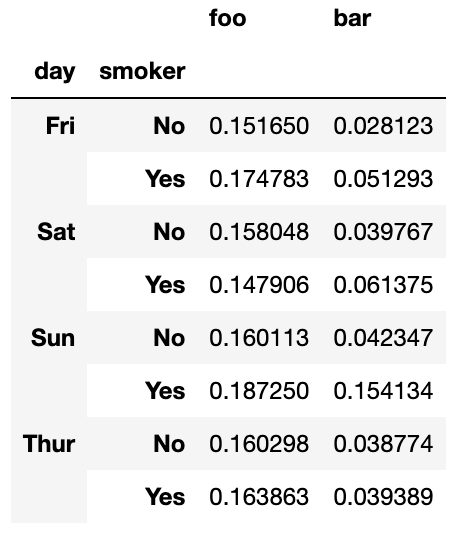
DataFrame은 컬럼마다 다른 함수를 적용하거나 여러 개의 함수를 모든 컬럼에 적용할 수 있다.
#tip_pct와 total_bill 컬럼에 대해 동일한 세 가지 통계를 계산해보자.
func=['count','mean','max']
result=grouped['tip_pct','total_bill'].agg(func)
result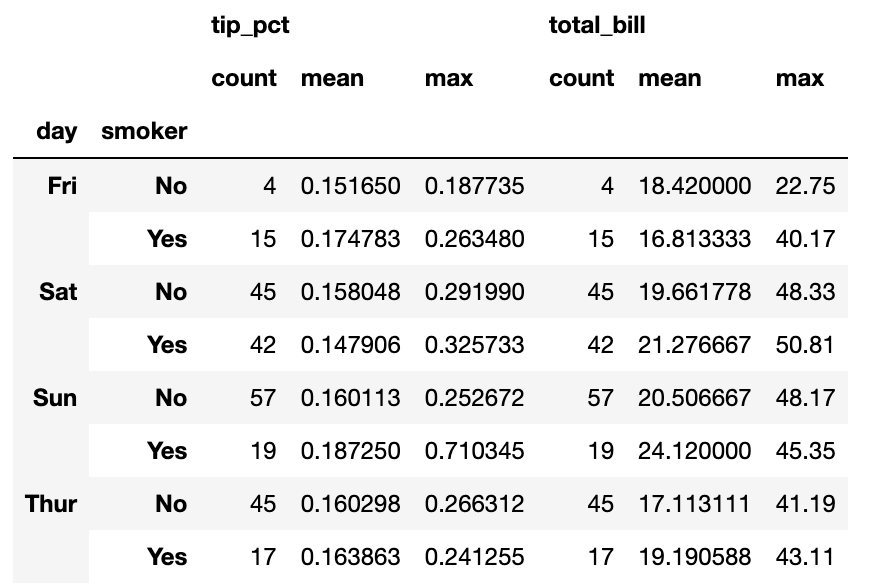
이 경우 반환된 DataFrame은 계층적 색인을 가지고 있다. 특정 컬럼에만 함수를 적용시키는 경우도, 튜플의 리스트를 이용하여 컬럼 이름을 지정해줄 수 있다.
ftuples = [('Durchschnitt', 'mean'), ('Abweichung', np.var)]
grouped['tip_pct', 'total_bill'].agg(ftuples)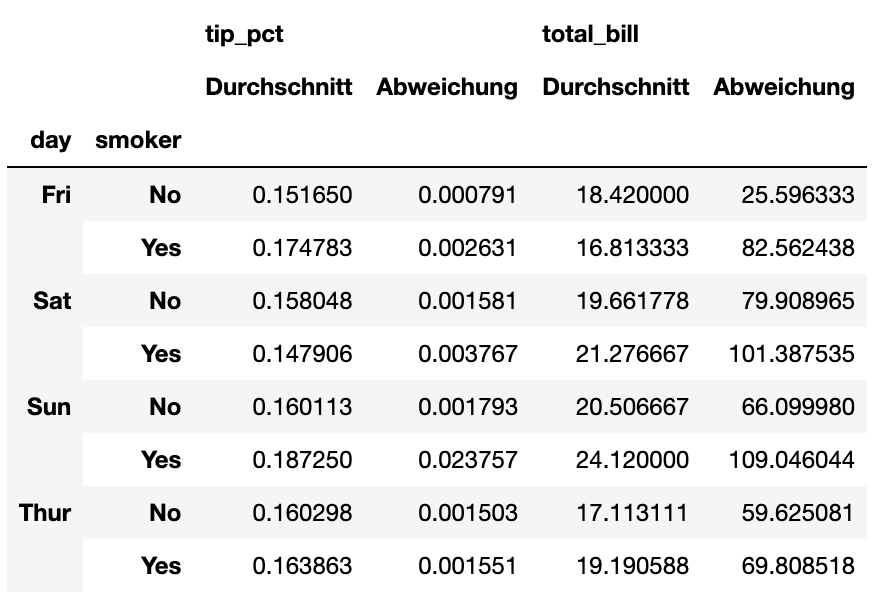
컬럼마다 다른 함수를 적용하고 싶다면 agg 메서드에 컬럼 이름에 대응하는 함수가 들어있는 사전을 넘기면 된다.
grouped.agg({'tip' : np.max, 'size' : 'sum'})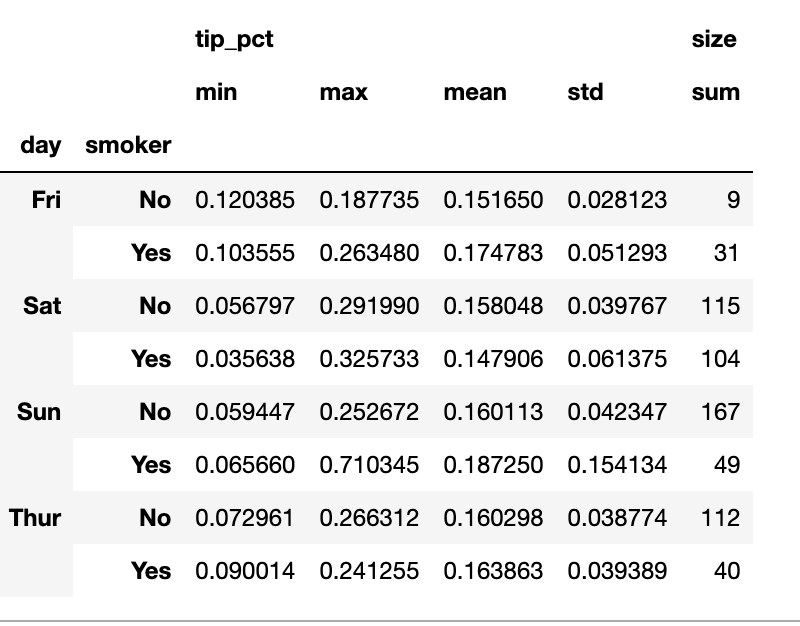 단 하나의 컬럼에라도 여러 개의 함수가 적용되었다면 DataFrame은 계층적인 컬럼을 가직게됨을 기억하자.
단 하나의 컬럼에라도 여러 개의 함수가 적용되었다면 DataFrame은 계층적인 컬럼을 가직게됨을 기억하자.
색인되지 않은 형태로 집계된 데이터 반환하기
여태껏 살펴본 예제에서 집계된 데이터는 유일한 그룹키 조합으로 색인되어 반환되었다. 하지만, 이를 원하지 않는 경우 as_index 옵션을 False 로 설정해주면 된다.
tips.groupby(['day', 'smoker'], as_index=False).mean()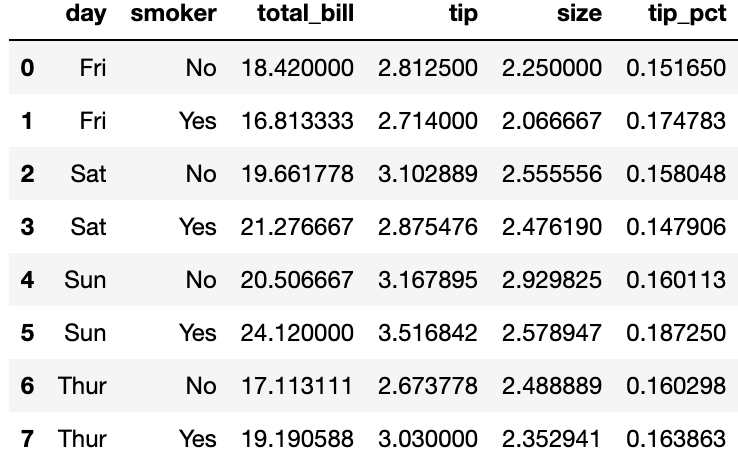
Apply: 일반적인 분리-적용-병합
가장 일반적인 GroupBy 메서드의 목적은 apply이다. apply 메서드는 객체를 여러 조각으로 나누고, 전달된 함수를 각 조각에 적용한 후 이를 다시 합치는 방식으로 동작한다.
팁 데이터에서 그룹별 상위 5개의 tip_pct 값을 골라보자. 우선 특정 컬럼에서 가장 큰 값을 가지는 로우를 선택하는 함수를 작성해보자.
def top(df,n=5,column='tip_pct'):
return df.sort_values(by=column)[-n:]
top(tips,n=6)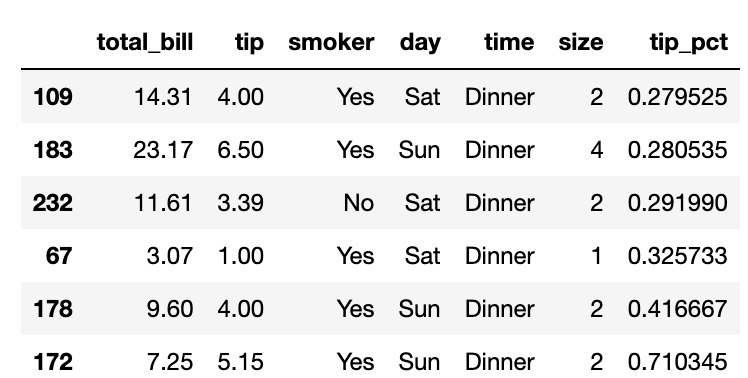
이제 smoker 그룹에 대해 이 top 함수를 apply 하면 다음과 같은 결과를 얻을 수 있다.
tips.groupby('smoker').apply(top)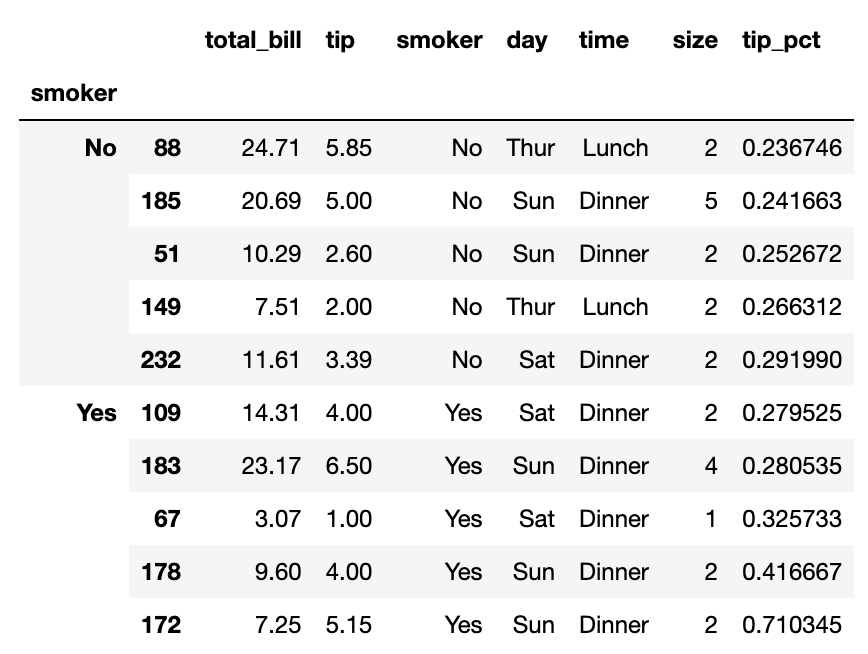
결과를 보면 top함수가 나뉘어진 DataFrame의 각 부분에 적용이 되었고, pandas.concat을 이용해서 하나로 합쳐진 그룹 이름표가 붙었다. 그리하여 결과는 계층적 색인을 가지게 되고 내부 색인은 원본 DataFrame의 색인값을 가지게 된다.
만일 apply 메서드로 넘길 함수가 추가적인 인자를 받는다면 함수 이름 뒤에 붙여서 넘겨주면 된다.
tips.groupby(['smoker', 'day']).apply(top, n=1, column='total_bill')그룹 색인 생략하기
살펴본 예제들에서 반환된 객체는 원본 객체의 각 조각에 대한 색인과 그룹 키가 계층적으로 색인으로 사용됨을 볼 수 있었다. 이런 결과는 groupby 메서드에 group_key=False로 막을 수 있다
tips.groupby('smoker', group_keys=False).apply(top)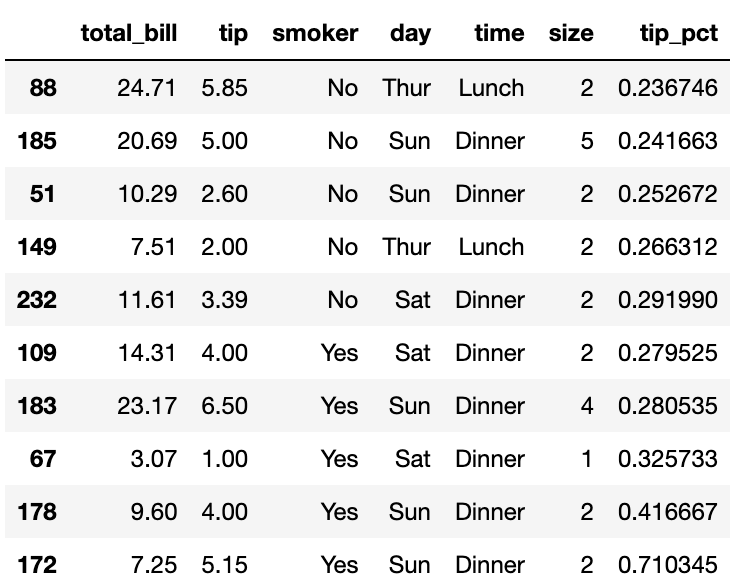
변위치 분석과 버킷 분석
7장에서 본 내용을 떠올려보면 pandas의 cut과 qcut 메서드를 사용해서 선택한 크기만큼, 혹은 표본 변위치에 따라 데이터를 나눌 수 있었다.
이 함수들을 groupby와 조합하면 데이터 묶음에 대해 변위치 분석과 버킷 분석을 매우 쉽게 수행할 수 있다.
임의의 데이터 묶음을 cut을 이용해서 등간격 구간으로 나누어보자.
import pandas as pd
import numpy as np
frame=pd.DataFrame({'data1':np.random.randn(1000),
'data2':np.random.randn(1000)})
quartiles = pd.cut(frame.data1,4)cut에서 반환된 Categorical 객체를 groupby로 넘길 수 있는데,
이러한 방식으로 컬럼에 대한 몇 가지 통계를 다음과 같이 계산할 수 있다.
def get_stats(group):
return {'min':group.min(), 'max':group.max(),
'count':group.count(),'mean':group.mean()}
grouped=frame.data2.groupby(quartiles)
grouped.apply(get_stats).unstack()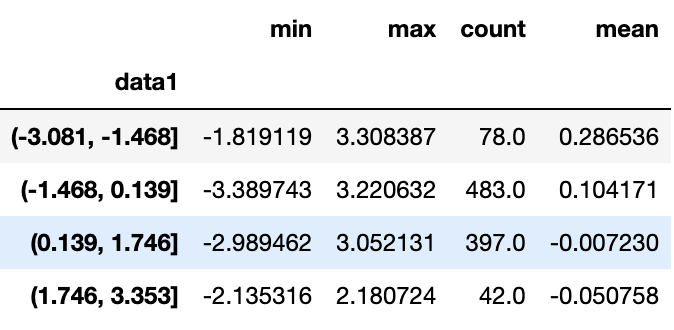 이는 cut 함수를 이용한 것이기에 등간격 버킷이었고, 표본 변위치에 기반하여 크기가 같은 버킷을 계산하려면 qcut을 사용하면된다.
이는 cut 함수를 이용한 것이기에 등간격 버킷이었고, 표본 변위치에 기반하여 크기가 같은 버킷을 계산하려면 qcut을 사용하면된다.
grouping=pd.qcut(frame.data1,4,labels=False)
grouped= frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()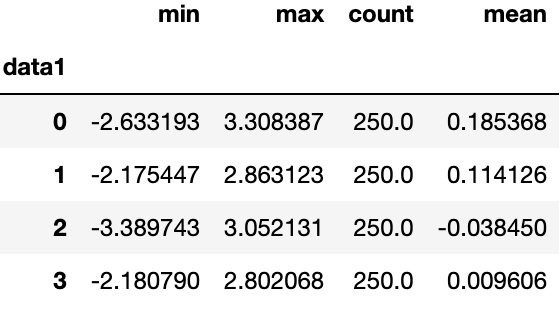 pandas의 Categorical 자료형은 12장에서 더 자세히 살펴보자
pandas의 Categorical 자료형은 12장에서 더 자세히 살펴보자