들어가며
데이터를 취합해서 하나의 데이터 집합을 준비하고 나면, 그룹통계를 구하거나, 가능하다면 피벗테이블을 구해서 시각화하게 된다.
pandas는 데이터 집합을 핸들링하는 groupby 라는 유연한 방법을 제공한다.
관계형 데이터베이스와 SQL이 인기 있는 이유 중 하나는 데이터를 쉽게 핸들링할 수 있기 때문이다.
하지만, SQL 쿼리문은 그룹 연산에 제약이 있다. 반면, Python과 Pandas를 잘 이용하면 복잡한 그룹연산도 해결할 수 있다.
GroupBy Mechanics
흔히, 그룹 연산을 설명할 때 '분리-적용-결합' 용어를 사용한다.
1) 분리
pandas 객체나 다른 객체에 들어 있는 데이터를 하나 이상의 키를 기준으로 분리한다.
2) 적용
분리된 각 그룹에 함수를 적용시켜 새로운 값을 얻어낸다.
3)결합
함수를 적용한 결과를 하나의 객체로 결합한다.
간단한 그룹 연산들의 예시를 살펴보자. 먼저 다음과 같이 DataFrame으로 표현되는 간단한 표 형식의 데이터가 있다고 하자.
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],
'key2' : ['one', 'two', 'one', 'two', 'one'],
'data1' : np.random.randn(5),
'data2' : np.random.randn(5)})
df
"""
key1 key2 data1 data2
0 a one -0.204708 1.393406
1 a two 0.478943 0.092908
2 b one -0.519439 0.281746
3 b two -0.555730 0.769023
4 a one 1.965781 1.246435
"""이 데이터를 groupby메서드로 key1 컬럼을 넘겨, 각 그룹에서 data1의 평균을 구해보자.
grouped=df['data1'].groupby(df['key1'])
grouped
#<pandas.core.groupby.generic.SeriesGroupBy object at ..이 'grouped' 변수는 GroupBy 객체이다. 이 객체는 그룹 연산을 위해 필요한 모든 정보를 가지고 있어서 각 그룹에 어떤 연산이든 적용할 수 있다. 평균을 구하기 위해 mean 메서드를 사용해보자.
grouped.mean()
"""
key1
a 0.746672
b -0.537585
Name: data1, dtype: float64
"""이 예제에서 중요한 점은 데이터가 column 값에 따라 Group으로 수집되고, Key1 column에 있는 유일한 값으로 색인되는 새로운 Series 객체가 생성된다는 것이다.
여러 개의 배열을 리스트로 넘겼다면 다른 결과를 얻게 된다.
means = df['data1'].groupby([df['key1'], df['key2']]).mean()
means
"""
key1 key2
a one 0.880536
two 0.478943
b one -0.519439
two -0.555730
Name: data1, dtype: float64
"""데이터를 두 개의 column으로 묶었고, 그 결과 계층적 색인을 가지는 Series를 얻을 수 있는데,
이 데이터에 unstack 메서드를 사용하게 되면, DataFrame으로 객체를 받을 수 있다.
means.unstack()
"""
key2 one two
key1
a 0.880536 0.478943
b -0.519439 -0.555730
"""한 그룹으로 묶을 정보는 주로 같은 DataFrame 안에서 찾게 되는데, 이 경우 컬럼 이름을 넘겨서 그룹의 색인으로 사용할 수 있다.
"""
data1 data2
key1
a 0.746672 0.910916
b -0.537585 0.525384
"""
df.groupby(['key1', 'key2']).mean()
"""
data1 data2
key1 key2
a one 0.880536 1.319920
two 0.478943 0.092908
b one -0.519439 0.281746
two -0.555730 0.769023
"""위에서 df.groupby('key1').mean() 코드를 보면 key2 컬럼이 결과에서 빠져 있는 것을 확인할 수 있다. 그 이유는 df['key2']는 숫자 데이터가 아니기 때문인데, 이런 컬럼은 nuisance column이라 불리며 결과에서 제외시킨다.
그룹 간 순회하기
GroupBy 객체는 이터레이션을 지원하는데, 그룹 이름과 그에 따른 데이터 묶음을 튜플로 반환한다.
for name, group in df.groupby('key1'):
print(name)
print(group)
"""
a
key1 key2 data1 data2
0 a one -0.204708 1.393406
1 a two 0.478943 0.092908
4 a one 1.965781 1.246435
b
key1 key2 data1 data2
2 b one -0.519439 0.281746
3 b two -0.555730 0.769023
"""이처럼 column이 여럿 존재하는 경우 튜플의 첫 번째 원소가 색인 값이 된다.
for (k1, k2), group in df.groupby(['key1', 'key2']):
print((k1, k2))
print(group)
"""
('a', 'one')
key1 key2 data1 data2
0 a one -0.204708 1.393406
4 a one 1.965781 1.246435
('a', 'two')
key1 key2 data1 data2
1 a two 0.478943 0.092908
('b', 'one')
key1 key2 data1 data2
2 b one -0.519439 0.281746
('b', 'two')
key1 key2 data1 data2
3 b two -0.55573 0.769023
"""당연히 이 안에서 원하는 데이터만 골라낼 수 있다.
pieces = dict(list(df.groupby('key1')))
pieces['b']
"""
key1 key2 data1 data2
2 b one -0.519439 0.281746
3 b two -0.555730 0.769023
"""groupby 메서드는 기본적으로 axis=0에 대해 그룹을 만드는데, 다른 축으로 그룹을 만드는 것도 가능하다. 예로 df의 컬럼을 dtype에 따라 그룹으로 묶을 수도 있다.
df.dtypes
"""
key1 object
key2 object
data1 float64
data2 float64
dtype: object
"""컬럼이나 컬럼의 일부만 선택하기
DataFrame에서 만든 GroupBy 객체를 컬럼 이름이나 그 배열로 색인하면 수집을 위해 해당 컬럼을 선택하게 된다.
대용량 데이터를 다룰 경우 소수의 컬럼만 집계하고 싶을 때가 종종 있는데, 예를 들어 위 데이터에서 data2 컬럼에 대해서만 평균을 구하고 결과를 dataframe으로 받고 싶다면 아래와 같이 작성한다.
df.groupby(['key1', 'key2'])[['data2']].mean()
""" data2
key1key2
a one 1.319920
two 0.092908
b one 0.281746
two 0.769023
"""색인으로 얻은 객체는 groupby 메서드에 리스트나 배열을 넘겼을 경우 DataFrameGroupBy 객체가 되고, 단일 값으로 하나의 컬럼 이름만 넘겼을 경우 SeriesGroupBy 객체가 된다.
s_grouped = df.groupby(['key1', 'key2'])['data2']
s_grouped
s_grouped.mean()
#a one 1.319920
# two 0.092908
#b one 0.281746
# two 0.769023
#Name: data2, dtype: float64사전과 Series에서 Grouping하기
그룹 정보는 배열이 아닌 형태로 존재하기도 한다. 다른 DataFrame 예제를 살펴보자.
people = pd.DataFrame(np.random.randn(5, 5),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])
people.iloc[2:3, [1, 2]] = np.nan # Add a few NA values
people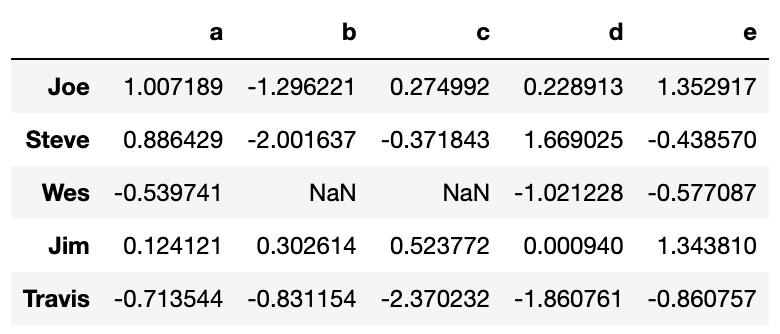
이 데이터의 각 컬럼을 나타낼 그룹 목록이 있고, 그룹별로 컬럼의 값을 모두 더해보자.
mapping = {'a': 'red', 'b': 'red', 'c': 'blue',
'd': 'blue', 'e': 'red', 'f' : 'orange'}이 사전에서 groupby 메서드로 넘길 배열을 뽑을 수 있지만 그냥 이 사전을 groupby 메서드로 넘기자.
by_column = people.groupby(mapping, axis=1)
by_column.sum()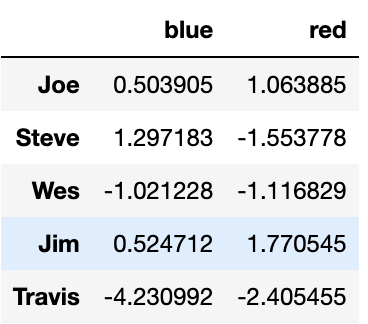
Series에 대해서도 같은 기능을 수행할 수 있는데, 고정된 크기의 맵이라고 보면 된다.
map_series = pd.Series(mapping)
map_series
"""
a red
b red
c blue
d blue
e red
f orange
dtype: object
"""
people.groupby(map_series, axis=1).count()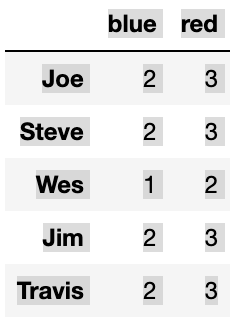
함수로 Grouping
파이썬 함수를 사용하는 것은 사전이나 Series를 사용해서 그룹을 매핑하는 것보다 더 일반적이다.
방금 살펴본 예제에서 people DataFrame은 사람의 이름을 색인값으로 사용했다. 만약 이름의 길이별로 그룹을 묶고 싶다면 이름의 길이가 담긴 배열 대신 len 함수를 넘기면 되는 것이다.
people.groupby(len).sum()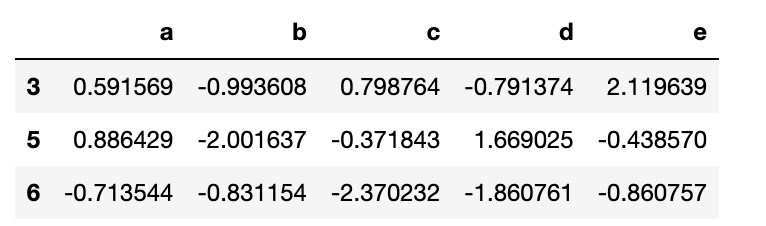 내부적으로는 모두 배열로 변환되므로,
함수를 배열, 사전, Seires 와 섞어쓰더라도 문제가 되지 않는다.
내부적으로는 모두 배열로 변환되므로,
함수를 배열, 사전, Seires 와 섞어쓰더라도 문제가 되지 않는다.
key_list = ['one', 'one', 'one', 'two', 'two']
people.groupby([len, key_list]).min()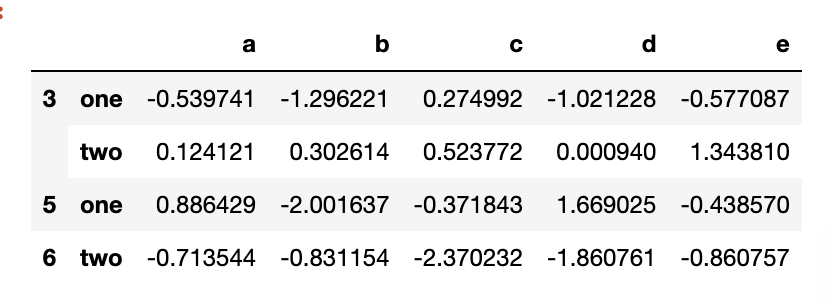
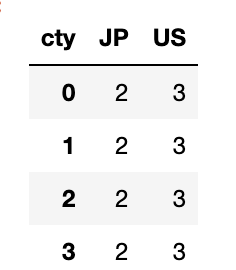
색인 단계로 Grouping
계층적 색인된 데이터는 축 색인의 단계 중 하나를 사용해서 편리하게 집계할 수 있다.
columns = pd.MultiIndex.from_arrays([['US', 'US', 'US', 'JP', 'JP'],
[1, 3, 5, 1, 3]],
names=['cty', 'tenor'])
hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)
hier_df이 기능을 사용하려면 level 예약어를 사용해서 레벨 번호나 이름을 넘기면 된다.
hier_df.groupby(level='cty', axis=1).count()