pandas에서 seaborn으로 그래프 그리기
지난 로그의 matplotlib을 내부적으로 사용하는 seaborn 라이브러리를 이용하여 그래프를 그려보자.
seaborn 라이브러리는 import 하면 더 나은 가독성을 위해 matplotlib의 기본 스타일을 변경한다. 그래서 일부는 seaborn API를 사용하지 않더라도, matplotlib의 그래프 스타일을 개선하기 위해서 seaborn을 import 하기도 한다.
선그래프
Series와 DataFrame은 둘 다 plot 메서드를 이용해 다양한 형태의 그래프를 생성할 수 있다. plot 메서드는 기본적으로 선그래프를 생성한다.
pandas의 DataFrame과 Series 객체는 plot 메서드를 통해 그래프로 출력이 가능한데, 이는 .plot method가 내부적으로 matplotlib을 import 하기 때문이다.
s=pd.Series(np.random.randn(10).cumsum(),
index=np.arange(0,100,10))
s.plot()
이 plot 메서드는 다양한 인자를 포함한다.
Series.plot 메서드의 인자를 살펴보자
| 인자 | 설명 |
|---|---|
| label | 그래프의 범례 이름 |
| ax | 그래프를 그릴 matplotlib의 서브플롯 객체 지정 |
| style | matplotlib에 전달할 'ko--'같은 스타일 문자열 |
| alpha | 그래프 투명도 (0~1) |
| kind | 그래프 종류 지정.'area','bar','barh','hist','line','pie' 등. 기본은 'line' |
| logy | y축에 대한 로그 스케일링 |
| use_index | 객체의 색인을 눈금 이름으로 사용할지 여부 |
| rot | 눈금 이름을 로테이션 (0~360) |
| xticks | x축으로 사용할 값 |
| yticks | y축으로 사용할 값 |
| xlim | x축 한계 |
| ylim | y축 한계 |
| gird | 축의 grid를 표시할지 여부 (기본값은 on) |
DataFrame에는 추가적으로 컬럼을 쉽게 다루기 위한 몇가지 옵션이 있다.
| 인자 | 설명 |
|---|---|
| subplots | 각 DataFrame의 컬럼을 독립된 서브플롯에 그린다. |
| sharex, sharey | subplots=True인 경우 같은 x,y축을 공유하고 눈금과 한계를 연결한다. |
| figsize | 생성될 그래프의 크기를 튜플로 지정한다. |
| title | 그래프의 제목을 문자열로 지정한다. |
| legend | 서브플롯의 범례를 추가한다. 기본값은 True이다. |
| sort_columns | 칼럼을 알파벳 순서로 그린다. |
하나의 DataFrame을 바탕으로 plot메서드의 기본형과 다양한 옵션을 추가한 후의 그래플 비교해보자.
df=pd.DataFrame(np.random.randn(10,4).cumsum(0),
columns=['A','B','C','D'],
index=np.arange(0,100,10))
df.plot()
df.plot(xlim=(0,60),ylim=(-2,2),
grid=True,figsize=(10,2),title='test')
다양한 옵션을 추가하여 그래프를 나타내 보았지만, 이전 그래프와 비교하여 가독성이 늘거나 하진 않았다. 이렇게 옵션을 사용하면 안되고, 자신의 데이터 분석에 용이하도록 옵션을 지정하여 사용하면 유용하게 사용할 수 있다.
9.2.2 막대그래프
plot.bar()와 plot.barh()는 각각 수직막대그래프와 수평막대그래프를 그린다.
Series 객체를 막대그래프로 표현해보자.
data=pd.Series(np.random.randn(16),index=list('abcdefghijklmnop'))
"""
a -0.961626
b 0.269290
c 1.679404
d -0.513121
e -1.058771
f 0.133130
g -0.010449
h 0.727957
i -0.325265
j -0.081361
k -0.241110
l 1.090500
m 0.995299
n -0.430170
o 0.165046
p 0.769203
dtype: float64
"""fig, axes=plt.subplots(2,1) #subplot를 생성할 때 figure가 없으면 생성하여 반환
data.plot.bar(ax=axes[0],color='k',alpha=0.7)
data.plot.barh(ax=axes[1],color='k',alpha=0.7)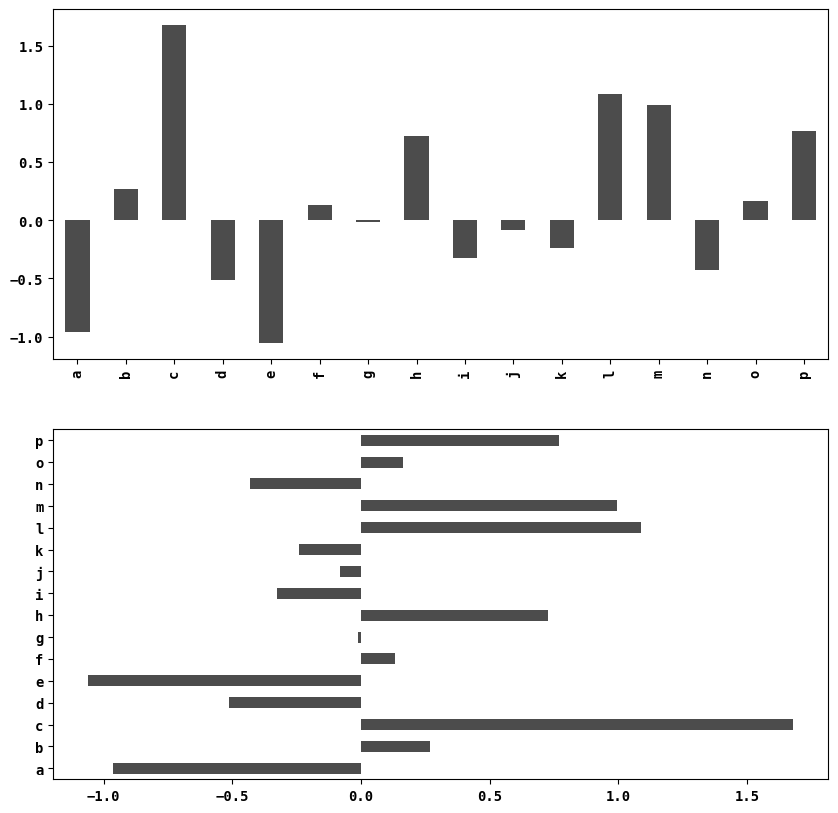
color='k' => 색지정, alpha => 투명도 지정, ax=>표현할 subplot 지정
DataFrame에서 막대그래프는 각 로우의 값을 함께 묶어서 하나의 그룹마다 각각의 막대를 보여준다.
df=pd.DataFrame(np.random.rand(6,4),
index=['one','two','three','four','five','six'],
columns=pd.Index(['A',"B","C","D"],name='Genus'))
df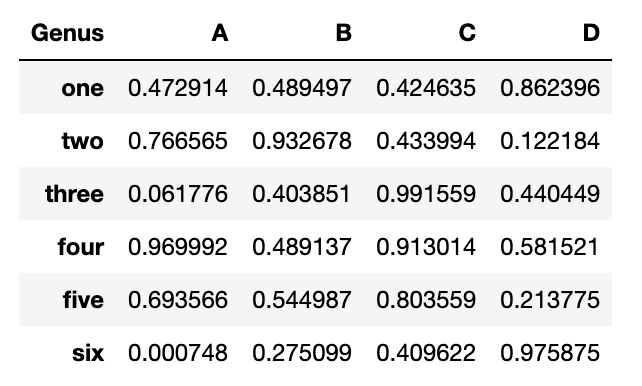
df.plot.bar()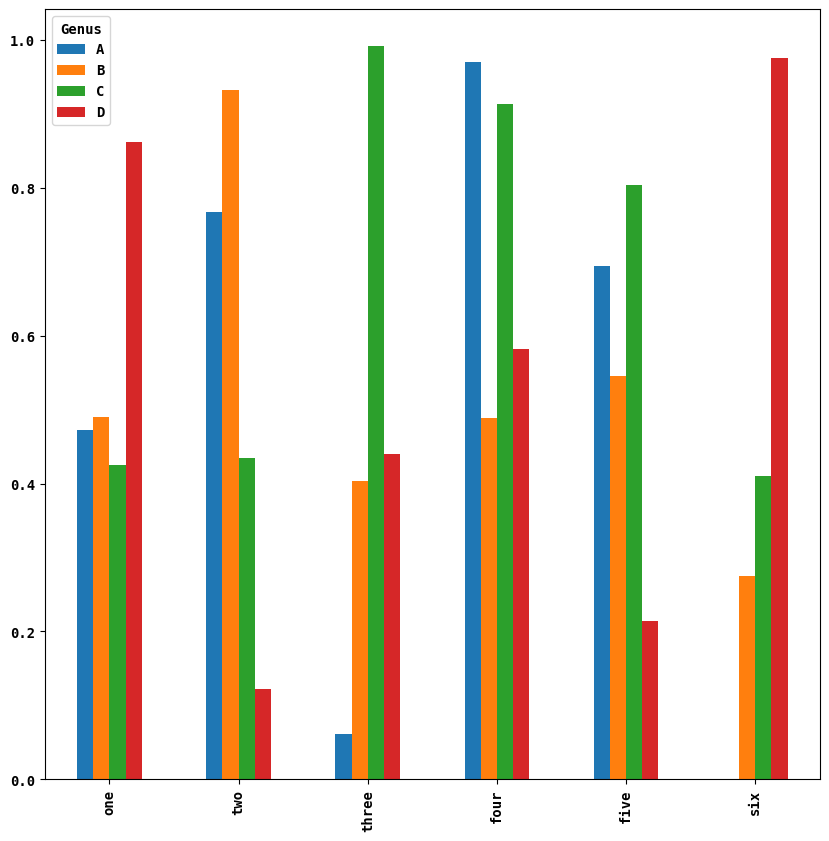
각 element 별로 그래프가 나타내는 게 아닌 누적막대그레프를 보고싶다면 stacked=True 옵션을 사용하여 활성화할 수 있다.
df.plot.barh(stacked=True,alpha=0.5)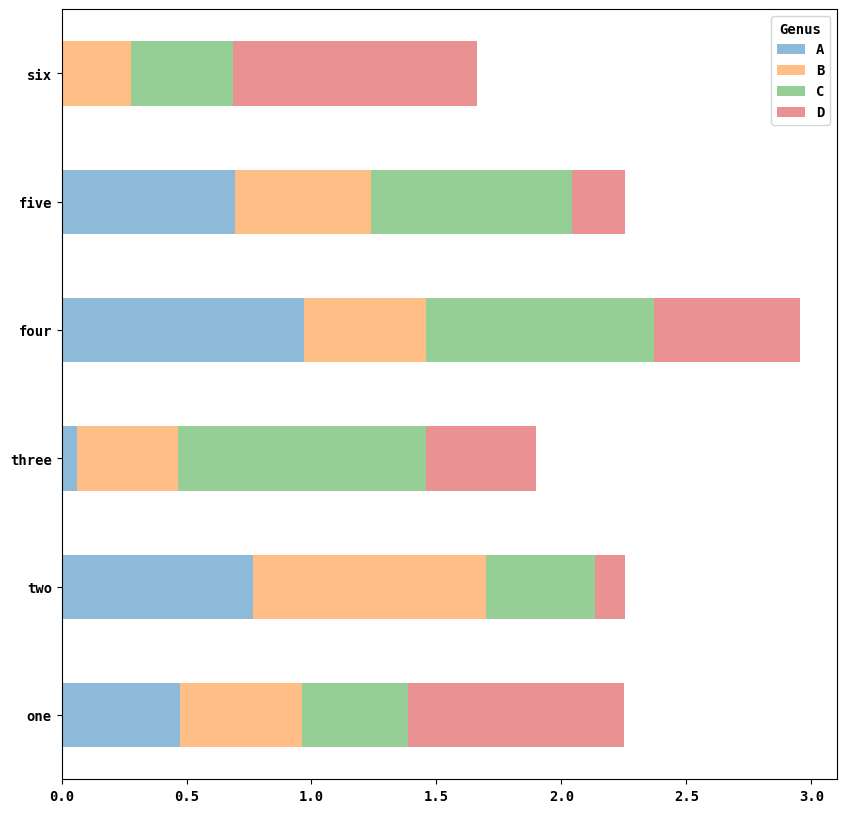
실습
팁 데이터를 살펴보며, 이 데이터에서 요일별 파티 숫자를 뽑고, 파티 숫자 대비 팁 비율을 보여주는 막대그래플 그려보자.
이를 위해, 우선 read_csv 메서드를 사용해서 데이터를 불러오고 요일과 파티 숫자에 따라 교차 테이블을 생성해보자
tips=pd.read_csv('examples/tips.csv')
party_counts=pd.crosstab(tips['day'],tips['size'])
party_counts
"""
size 1 2 3 4 5 6
day
Fri 1 16 1 1 0 0
Sat 2 53 18 13 1 0
Sun 0 39 15 18 3 1
Thur 1 48 4 5 1 3
"""데이터가 충분치 않은 1인과 6인의 파티를 제외하고, 각 로우의 합이 1이 되도록 정규화하여 그래프를 그려보자
party_counts=party_counts.loc[:,2:5]
party_pcts=party_counts.div(party_counts.sum(1),axis=0)
party_pcts.plot.bar()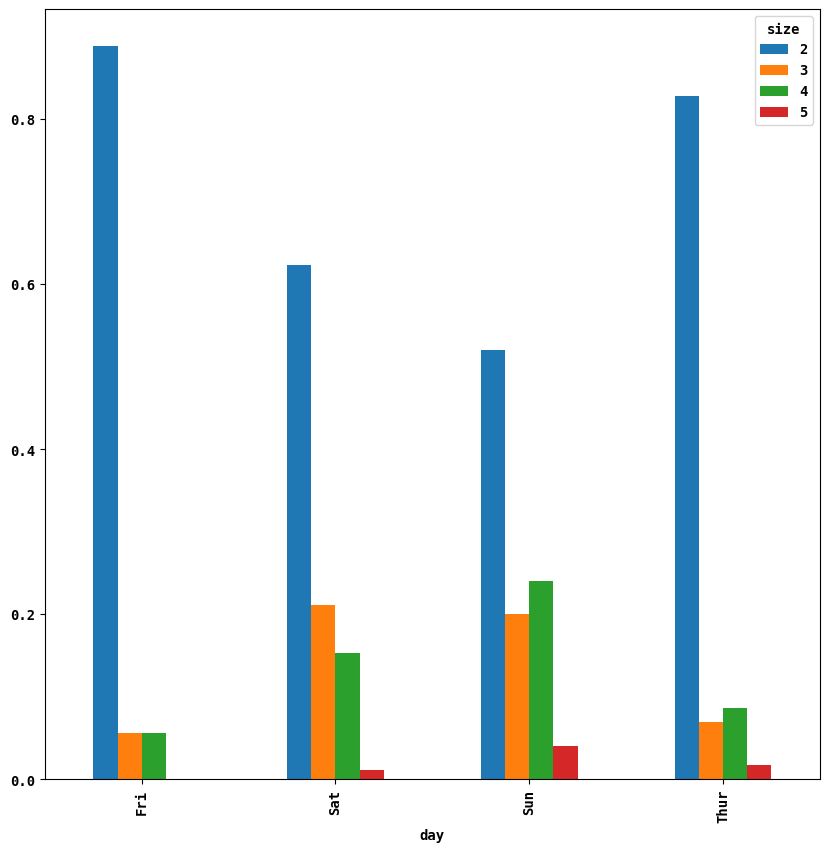
데이터를 통해 파티의 규모가 주말에 커지는 경향이 있음을 알 수 있다.
그래프를 그리기 전에 요약을 해야 하는 데이터는 seaborn 패키지를 이용하면 간단하게 처리할 수 있다.
seaborn 패키지로 팁 데이터를 다시 그려보자.
import seaborn as sns
tips['tip_pct'] = tips['tip'] / (tips['total_bill'] - tips['tip'])
tips.head()
"""
total_bill tip smoker day time size tip_pct
0 16.99 1.01 No Sun Dinner 2 0.063204
1 10.34 1.66 No Sun Dinner 3 0.191244
2 21.01 3.50 No Sun Dinner 3 0.199886
3 23.68 3.31 No Sun Dinner 2 0.162494
4 24.59 3.61 No Sun Dinner 4 0.172069
"""
sns.barplot(x='tip_pct', y='day', data=tips, orient='h')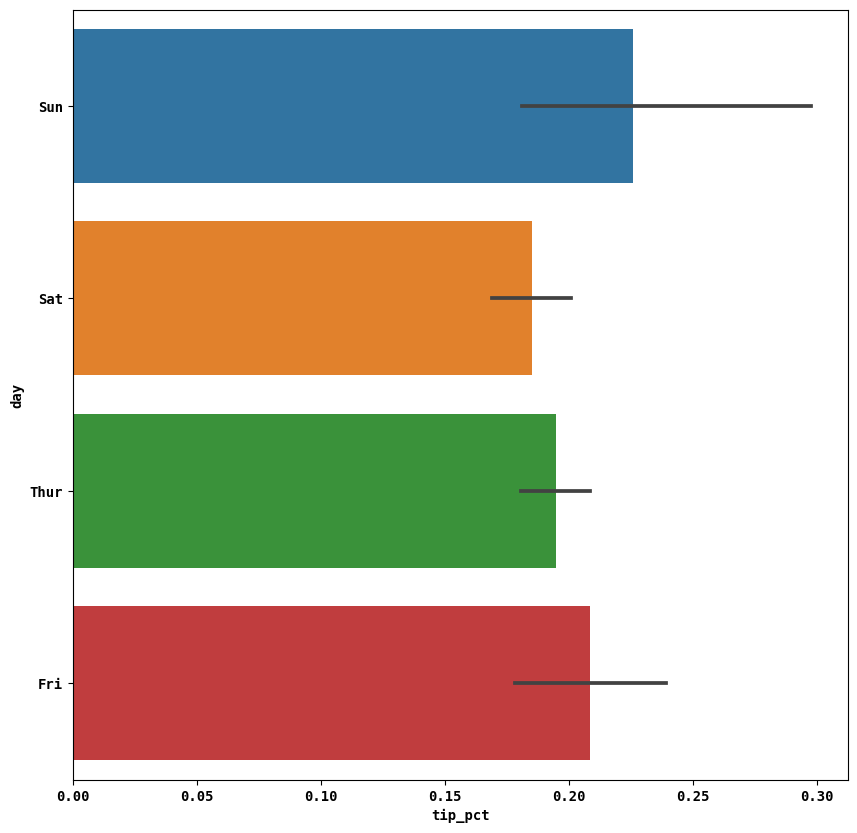
seaborn 플로팅 함수의 data 인자는 pandas의 DataFrame을 받는다.
day 컬럼의 각 값에 대한 데이터는 여럿 존재하므로 tip_pct의 평균값으로 그래프를 그렸다. 이때, 막대그래프에 덧 그려진 선은 95%의 신뢰구간을 나타낸다.
(hue 옵션을 이용하면 추가 분류에 따라 나눠 그릴 수도 있다.)
sns.barplot(x='tip_pct', y='day', hue='time',
data=tips, orient='h')
sns.set(style='whitegrid')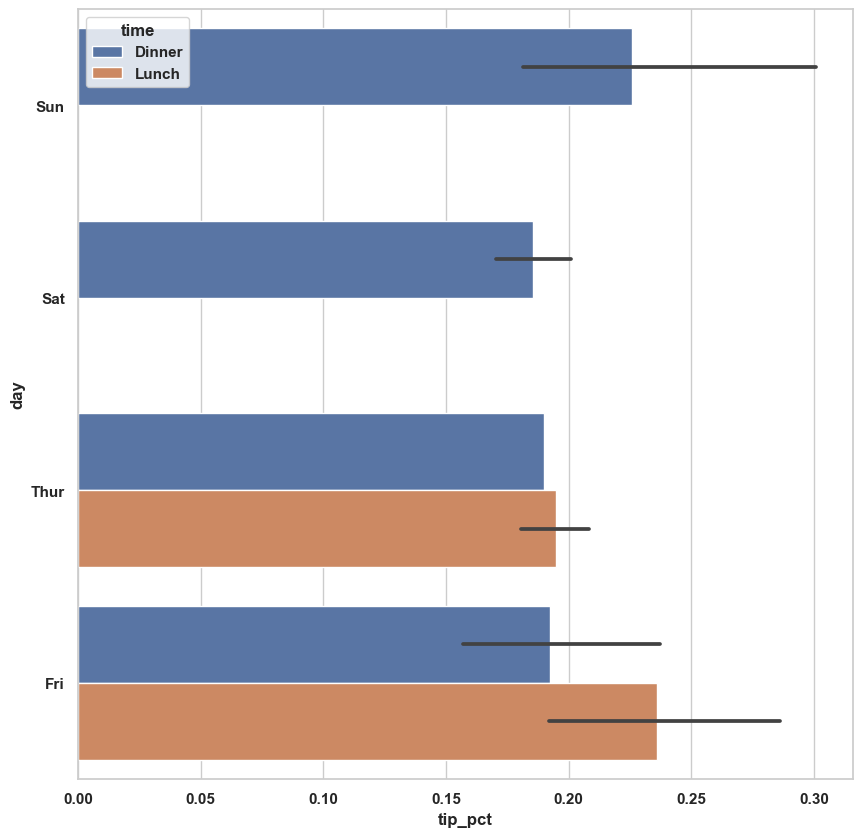
9.2.3 히스토그램과 밀도 그래프
히스토그램은 막대 그래프의 한 종류로, 값들의 빈도를 분리해서 보여준다.앞에서 살펴본 팁 데이터를 사용해서 전체 결제 금액 대비 팁 비율을 Series의 plot.hist() 메서드를 사용해서 만들어 보자.
tips['tip_pct'].plot.hist(bins=50) # bins옵션은 x축을 몇개의 그룹으로 나타낼 지 나타낸다.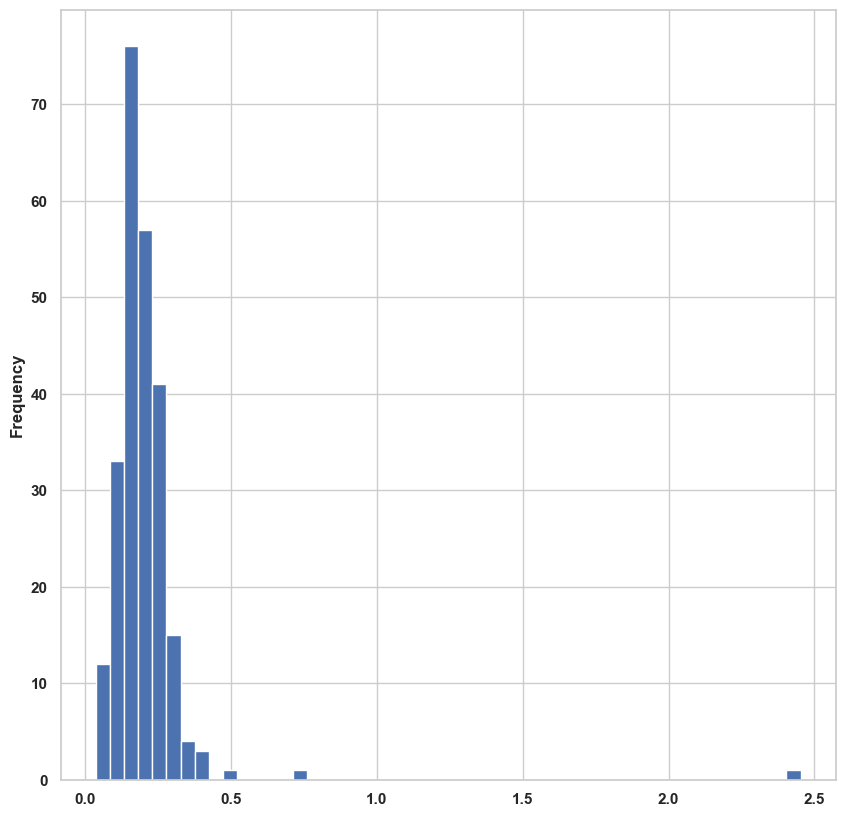
이와 관련 있는 다른 그래프로 밀도 그래프가 있다. 밀도 그래프는 관찰값을 사용해서 연속된 확률 분포를 그려준다.
tips['tip_pct'].plot.density()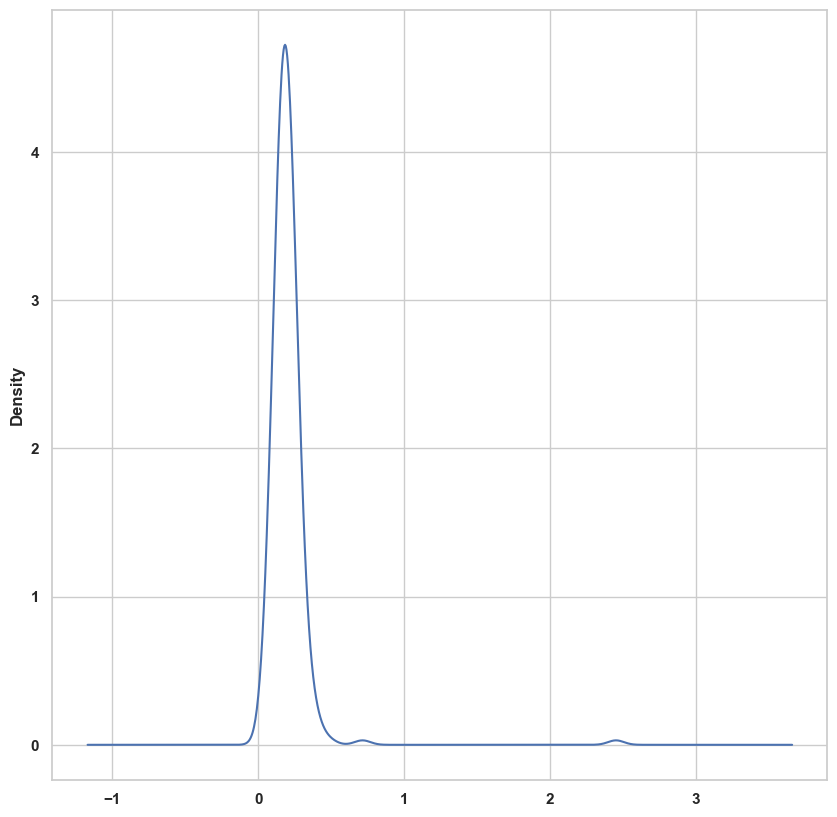
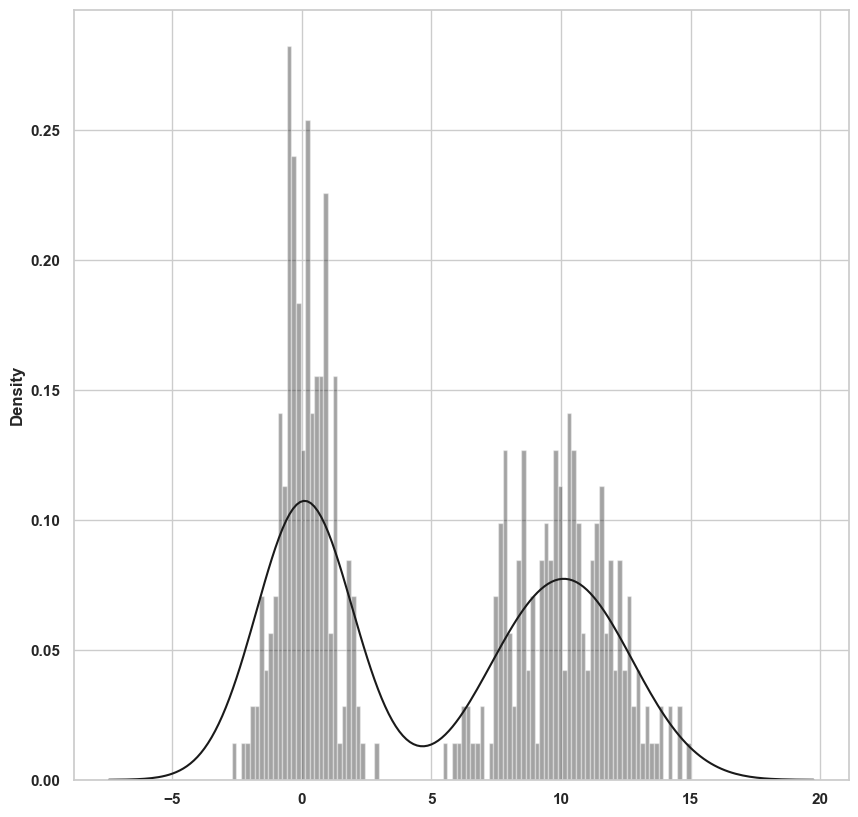
seaborn 라이브러리의 distplot 메서드를 이용해서 히스토그램과 밀도 그래프를 한 번에 쉽게 그릴 수 있다. 예를 들어 두 개의 다른 표준정규분포로 이루어진 양봉분포를 생각해보자.
comp1=np.random.normal(0,1,size=200)
comp2=np.random.normal(10,2,size=200)
values=pd.Series(np.concatenate([comp1,comp2]))
sns.distplot(values,bins=100,color='k')Numpy의 concatenate함수는 두 배열을 하나로 합쳐주는 함수이다.
9.2.4 산포도
산포도는 두 개의 1차원 데이터 묶음 간의 관계를 나타내고자 할 때 유용한 그래프이다.
macrodata 데이터 묶음을 불러온 다음 몇 가지 변수를 선택하고 로그차를 구해보자.
macro = pd.read_csv('examples/macrodata.csv')
data = macro[['cpi', 'm1', 'tbilrate', 'unemp']]
trans_data = np.log(data).diff().dropna()
trans_data[-5:]
"""
cpi m1 tbilrate unemp
198 -0.007904 0.045361 -0.396881 0.105361
199 -0.021979 0.066753 -2.277267 0.139762
200 0.002340 0.010286 0.606136 0.160343
201 0.008419 0.037461 -0.200671 0.127339
202 0.008894 0.012202 -0.405465 0.042560
"""seaborn 라이브러리의 regplot 메서드를 이용하면 산포도와 선형회귀곡선을 함께 그릴 수 있다.
plt.figure()
sns.regplot(x='m1',y= 'unemp', data=trans_data)
plt.title("changes in log")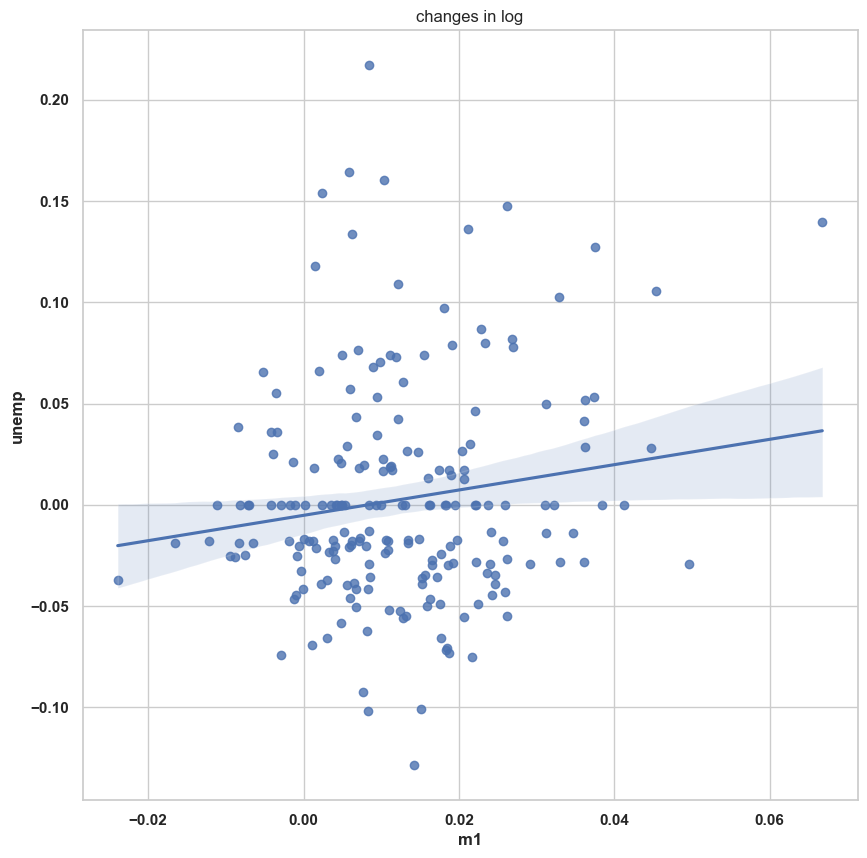
탐색 데이터 분석에서는 변수 그룹 간의 모든 산포도를 살펴보는 일이 잦은데, 이를 산포도 행렬이라고 부른다. 이런 그래프를 직접 그리는 과정은 다소 복잡한데,
seaborn에서는 pairplot 함수를 제공하여 대각선을 따라 각 변수에 대한 히스토그램이나 밀도 그래프도 생성할 수 있다.
sns.pairplot(trans_data,diag_kind='kde',plot_kws={'alpha':0.2})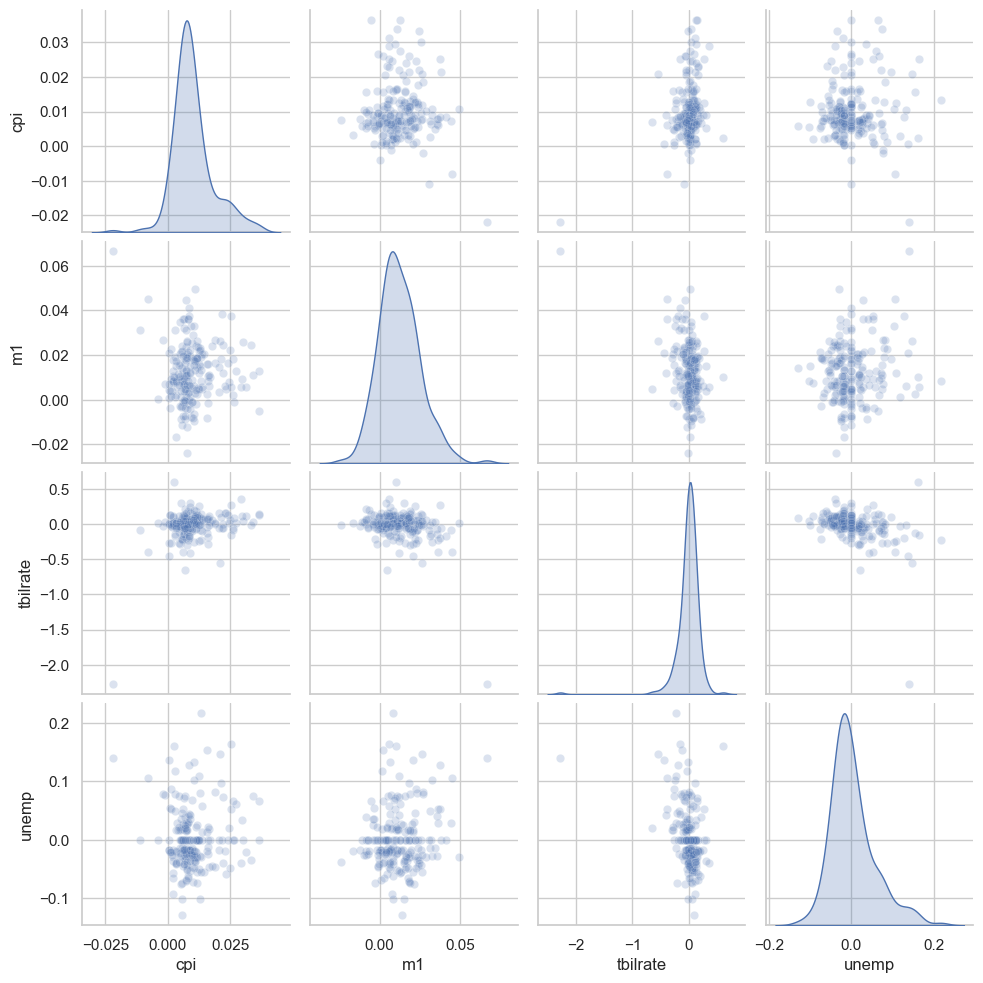 plot_kws 인자는 각각의 그래프에 전달할 개별 설정값을 지정한다.
plot_kws 인자는 각각의 그래프에 전달할 개별 설정값을 지정한다.
9.2.5 패싯 그리드와 범주형 데이터
다양한 범주형 값을 가지는 데이터를 시각화하는 한 가지 방법은 패싯 그리드를 이용하는 것이다.
seaborn은 catplot라는 내장 함수를 제공하여 다양한 면을 나타내는 그래프를 쉽게 그릴 수 있게 도와준다.
catplot의 함수명은 factorplot였으나 변경되었으니 사용에 주의하자.
sns.catplot(x='day', y='tip_pct', hue='time', col='smoker',
kind='bar', data=tips[tips.tip_pct < 1])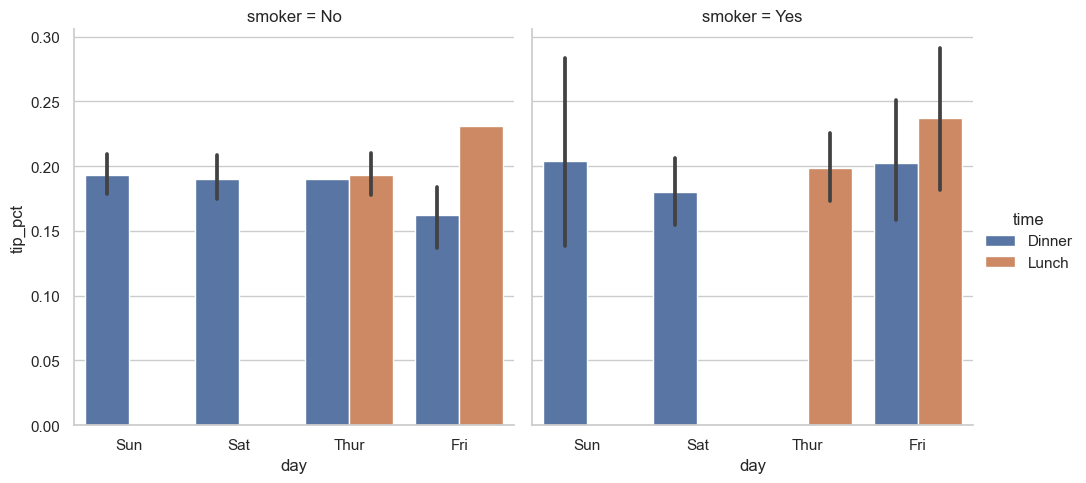
'time'으로 그룹을 만드는 대신 패싯 안에서 막대그래프의 색상을 달리해서 보여줄 수 있다.또한, time 값에 따른 그래프를 추가할 수도 있다.
sns.catplot(x='day',y='tip_pct',row='time',
col='smoker',kind='bar',data=tips[tips.tip_pct<1])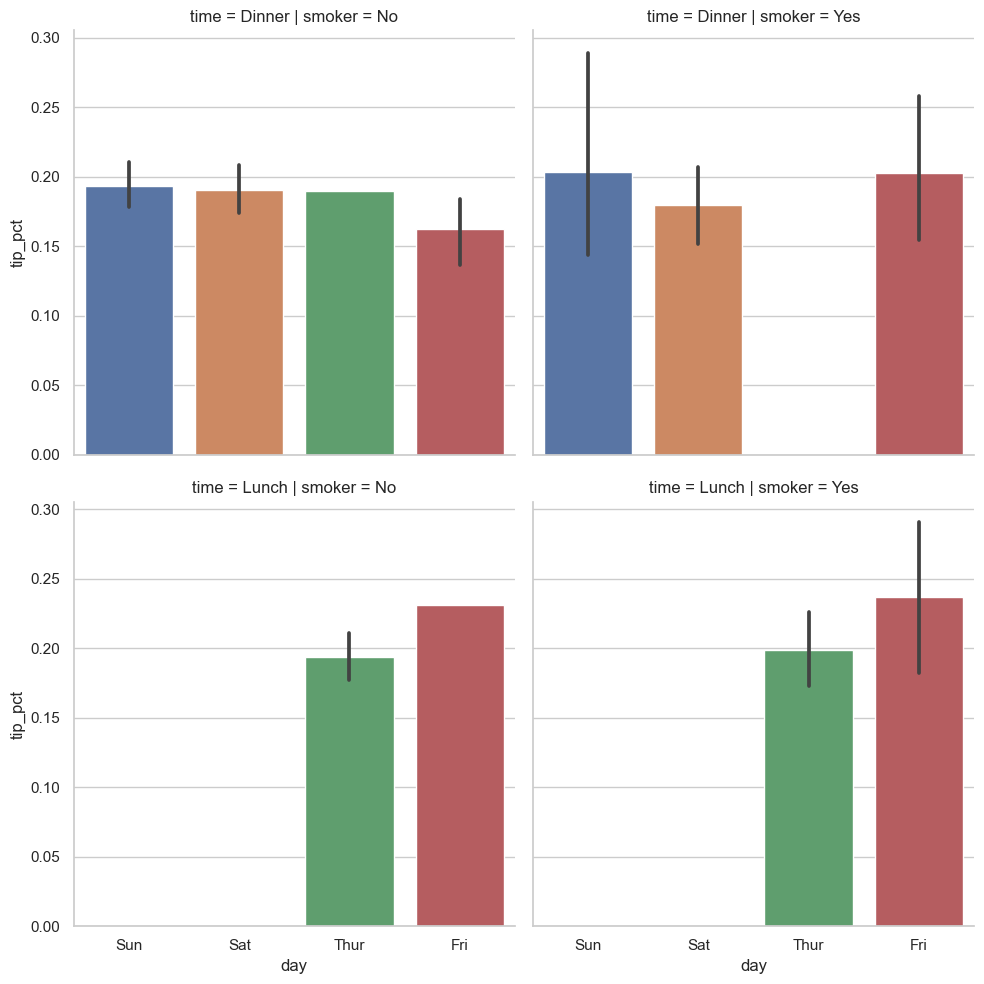)
catplot은 보여주고자 하는 목적에 어울리는 다른 종류의 그래프도 함께 지원한다.
sns.catplot(x='tip_pct',y='day',kind='box',
data=tips[tips.tip_pct<0.5])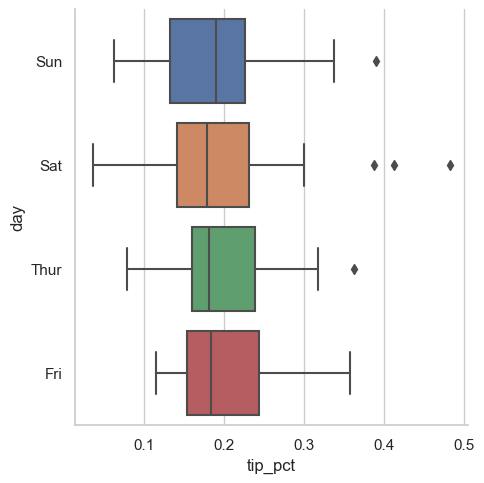
다른 파이썬 시각화 도구
여타 오픈소스와 마찬가지로 파이썬에서 그래프를 그릴 수 있는 라이브러리는 매우 많다.하지만, 이번에는 데이터분석에 있어서 가장 범용적으로 사용되고 있는 Seaborn과 Matplotlib을 살펴보았다.
마치며
이 장의 목적은 pandas, matplotlib, seaborn을 이용한 기본적인 데이터 시각화에 발을 담구는 수준이었다. 데이터 분석 결과를 시각적으로 공유해야하는 것이 중요한 업무(데이터 애널리스트)라면 자료를 더 많이 찾아보기를 권한다.
