About 시계열
시계열 데이터는 다양한 분야에서 사용되는 매우 중요한 데이터다. 시간 상의 여러 지점을 관측하거나 측정할 수 있는 모든 것이 시계열 데이터이다.
대부분의 시계열은 고정 빈도로 표현되는데 데이터가 존재하는 지점이 특정 규칙에 따라 고정 간격을 가지게된다.
이와 다르게, 시계열은 고정된 단위나 간격 간에 존재하지 않고, 불규칙적인 형태로 표현될 수도 있다.
어떻게 시계열 데이터를 표시하고 참조할지는 애플리케이션에 의존적이며 크게 3가지 유형이 있다.
1) 시간 내에서 특정 순간의 타임스탬프(timestamp)
2) 2007년 1월 or 2010년 전체 같은 고정된 기간(period)
3) 시작과 끝 타임스탬프로 표시되는 시간의 간격(timedelta)
이 세가지는 pandas의 시계열 class이기도 하다.
python의 시계열 클래스
파이썬 표준 라이브러리는 날짜(datetime)와 시간(time)을 위한 자료형과 달력(calendar) 관련 기능을 제공하는 자료형이 존재한다. 이 각 모듈은 처음 시계열을 공부하기에 좋다.
from datetime import datetime
now=datetime.now()
now
#datetime.datetime(2023, 9, 25, 14, 57, 22, 756063)
now.year,now.month,now.day
(2017,9,25)datetime은 날짜와 시간을 모두 저장하며 마이크로초까지 지원한다. datetime.timedelta는 두 datetime 객체 간의 시간 차이를 표현할 수 있다.
delta=datetime(2011,1,7)-datetime(2008,6,24,8,15)
delta
#datetime.timedelta(days=926, seconds=56700)timedelta 함수를 통해 기존 datetime 객체에 더하거나 빼면 그만큼의 시간이 datetime 객체에 적용되어 새로운 객체를 만들 수 있다.
from datetime import timedelta
start=datetime(2011,1,7)
start+timedelta(12)
#Out:datetime.datetime(2011, 1, 19, 0, 0)이번 시계열 part에서는 주로 pandas의 자료형과 고수준의 시계열을 주로 다룬다. 하지만 실제 파이썬을 사용하면,
다양한 곳에 datetime 기반의 자료형을 마주할 것이므로 기억해두자.
| 자료형 | 설명 |
|---|---|
| date | 달력을 사용해서 날짜(년,월,일)를 저장한다. |
| time | 하루의 시간(시,분,초)을 저장한다. |
| datetime | date+time |
| timedelta | 두 datetime 값 간의 차이를 표현한다. |
| tzinfo | 지역시간대를 저장하기 위한 기본 자료형 |
문자열을 datetime으로 변환하기
datetime 객체와 나중에 소개할 pandas의 Timestamp 객체는 str 메서드나 strftime 메서드에 포맷 규칙을 넘겨서 문자열로 변환하여 나타낼 수 있다.
stamp=datetime(2011,1,3)
str(stamp)
#Out:'2011-01-03 00:00:00'
stamp.strftime('%Y-%m-%d')
#Out:'2011-01-03'Datetime 포맷 규칙
| 포맷 | 설명 |
|---|---|
| %Y | 4자리 연도 |
| %y | 2자리 연도 |
| %m | 2자리 월 |
| %d | 2자리 일 |
| %H | 시간 (24시간 형식) |
| %I | 시간 (12시간형식) |
| %M | 2자리 분 |
| %S | 초 |
| %w | 정수로 나타낸 요일 |
| %U | 연중 주차(일요일 기준) |
| %W | 연중 주차(월요일 기준) |
| %z | UTC 시간대 오프셋을 +HHMM or -HHMM으로 표현한다. |
| %F | %Y-%m-%d 형식에 대한 축약(2012-4-18) |
| %D | %m/%d/%y 형식에 대한 축약(04/18/12) |
이 포맷 코드는 datetime.strptime을 사용해서 문자열을 날짜로 변환할 때 사용할 수 있다.
value='2011-01-03'
datetime.strptime(value,'%Y-%m-%d')
#Out: datetime.datetime(2011, 1, 3, 0, 0)
datestrs=['7/6/2011','8/6/2011']
[datetime.strptime(x,'%m/%d/%Y') for x in datestrs]
#Out:[datetime.datetime(2011, 7, 6, 0, 0),datetime.datetime(2011, 8, 6, 0, 0)]datetime.strptime은 알려진 형식의 날짜를 파싱하는 최적의 방법이다. 하지만 매번 포맷 규칙을 써야하는건 귀찮다. 이 경우에는 서드파티 패키지인 dateutil에 포함된 parser.parse 메서드를 사용하면 된다.
from dateutil.parser import parse
parse('2011-01-03')
#Out:datetime.datetime(2011, 1, 3, 0, 0)dateutil은 거의 대부분의 사람이 인지하는 날짜 표현 방식을 파싱할 수 있다. 개사긴데?
dateutil.parset는 매우 유용하지만 완벽한 도구는 아님을 기억하자. 날짜로 인식하지 않길 바라는 문자열을 날짜로 인식하기도 한다.
parse('Jan 31, 1997 10:45 PM')
Out:datetime.datetime(1997, 1, 31, 22, 45)국제 로케일의 경우 날짜가 월 앞에 오는 경우가 흔하다.이런 경우에는 dayfirst=True 옵션을 넘겨주면 된다.
parse('6/12/2011', dayfirst=True)
#Out:datetime.datetime(2011, 12, 6, 0, 0)pandas는 일반적으로 DataFrame의 컬럼이나 축 색인으로 날짜가 담긴 배열을 사용한다. to_datetime 메서드는 많은 종류의 날짜 표현을 처리한다. 물론 ISO 8601 같은 표준 날짜 형식에서 더 빠른 처리 속도를 가진다.
datestrs=['2011-07-06 12:00:00','2011-08-06 00:00:00']
import pandas as pd
pd.to_datetime(datestrs)
#Out:DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00'], #dtype='datetime64[ns]', freq=None)또한 누락된 값(None)으로 간주되어야 할 값도 처리해준다.
idx=pd.to_datetime([None])
idx
#Out:DatetimeIndex(['NaT'], dtype='datetime64[ns]', freq=None)NaT(not a time)은 pandas에서 누락된 타임스탬프 데이터를 나타낸다.
pandas's time series
pandas는 표준 시계열 도구와 데이터 알고리즘을 제공한다. 이를 통해 대량의 시계열 데이터를 효과적으로 다룰 수 있으며 쉽게 나누고, 집계하고, 불규칙적이며 고정된 빈도를 갖는 시계열도 리샘플링 할 수 있다.
pandas 시계열 기초
pandas에서 찾아볼 수 있는 가장 기본적인 시계열 객체의 종류는 파이썬 문자열이나 datetime 객체로 표현되는 타임스탬프로 색인된 Series이다.
import numpy as np
from datetime import datetime
dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),
datetime(2011, 1, 7), datetime(2011, 1, 8),
datetime(2011, 1, 10), datetime(2011, 1, 12)]
ts = pd.Series(np.random.randn(6), index=dates)
ts
"""
2011-01-02 -0.870522
2011-01-05 0.137757
2011-01-07 -0.380881
2011-01-08 -0.736112
2011-01-10 -1.044128
2011-01-12 -0.722277
dtype: float64
"""내부적으로 보면 datetime 객체는 DatetimeIndex에 들어 있으며 ts 변수의 타입은 TimeSeries다.
ts.index
"""
DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08',
'2011-01-10', '2011-01-12'],
dtype='datetime64[ns]', freq=None)
"""Timestamp는 datetime 객체를 사용하는 어떤 곳에도 대체 사용이 가능하다. 게다가 빈도에 관한 정보도 저장하며 시간대 변환을 하는 방법도 포함하고 있다.
색인, 선택, 부분 선택
시계열은 라벨에 기반해서 데이터를 선택하고 인덱싱할 때 pandas.Series와 동일하게 동작한다.
그냥 단순히 해석할 수 있는 날짜를 문자열로 넘겨서 편리하게 사용할 수 있다.
ts
"""
2011-01-02 -0.870522
2011-01-05 0.137757
2011-01-07 -0.380881
2011-01-08 -0.736112
2011-01-10 -1.044128
2011-01-12 -0.722277
dtype: float64
"""
stamp=ts.index[2]
stamp
#Out:Timestamp('2011-01-07 00:00:00')
ts[stamp]
#Out:-0.3808810630180572
ts['20110110']
#Out:-1.0441282960899896긴 시계열에서는 연을 넘기거나 연, 월만 넘겨서 데이터의 일부 구간만 선택할 수도 있다.
longer_ts = pd.Series(np.random.randn(1000),
index=pd.date_range('1/1/2000',
periods=1000))
longer_ts
"""
2000-01-01 -0.271054
2000-01-02 -1.785178
2000-01-03 -1.457016
...
2002-09-24 -1.257953
2002-09-25 -0.706740
2002-09-26 -1.409609
Freq: D, Length: 1000, dtype: float64
"""
longer_ts['2001']
"""
2001-01-01 0.897226
2001-01-02 -1.631074
2001-01-03 0.573275
...
"""
여기서 문자열 '2001'은 연도로 해석되어 해당 기간의 데이터를 선택한다 월에 대해서도 마찬가지로 선택할 수 있다.
longer_ts['2001-05']
"""
2001-05-01 -2.085558
2001-05-02 -2.721805
2001-05-03 0.227889
...
"""대부분의 시계열 데이터는 연대순으로 정렬되기 때문에 범위를 지정하기 위해 타임스태프를 이용해서 Series를 나눌 수 있다.
ts
"""
2011-01-02 -0.870522
2011-01-05 0.137757
2011-01-07 -0.380881
2011-01-08 -0.736112
2011-01-10 -1.044128
2011-01-12 -0.722277
dtype: float64
"""
ts['1/6/2011':'1/11/2011']
"""
2011-01-07 -0.380881
2011-01-08 -0.736112
2011-01-10 -1.044128
dtype: float64
"""이런 방식으로 데이터를 나누면 원본 시계열에 대한 뷰를 생성한다. 즉, 데이터 복사가 발생하지 않고 슬라이스에 대한 변경이 원본 데이터에도 반영된다.
이와 동일한 인스턴스 메서드로 truncate가 있는데, 이 메서드는 TimeSeries를 두 개의 날짜로 나눈다.
ts.truncate(after='1/9/2011')
"""
2011-01-02 -0.870522
2011-01-05 0.137757
2011-01-07 -0.380881
2011-01-08 -0.736112
dtype: float64
"""위 방식은 DataFrame에서도 동일하게 적용되며 로우에 인덱싱된다.
dates = pd.date_range('1/1/2000', periods=100, freq='W-WED')
long_df = pd.DataFrame(np.random.randn(100, 4),
index=dates,
columns=['Colorado', 'Texas',
'New York', 'Ohio'])
long_df.loc['5-2001']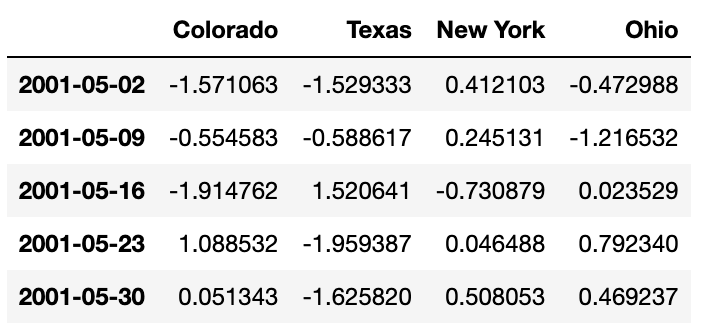
중복된 색인을 갖는 시계열
어떤 애플리케이션에서는 여러 데이터가 특정 타임스탬프에 몰려 있는 경우도 있다. 이럴 때 is_unique 속성을 통해 확인해보면 색인이 유일하지 않음을 알 수 있다.
dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000',
'1/2/2000', '1/3/2000'])
dup_ts = pd.Series(np.arange(5), index=dates)
dup_ts.index.is_unique
#Out:False이 시계열 데이터를 인덱싱하면 타임스탬프의 중복 여부에 따라 스칼라 값이나 슬라이스가 생성된다.
dup_ts['1/3/2000'] # not duplicated
#Out: 4
dup_ts['1/2/2000'] # duplicated
"""
2000-01-02 1
2000-01-02 2
2000-01-02 3
dtype: int64
"""groupby를 이용하여 유일하지 않은 타임스탬프를 가지는 데이터를 집계할 수도 있다.
grouped = dup_ts.groupby(level=0)
grouped.count()
"""
2000-01-01 1
2000-01-02 3
2000-01-03 1
dtype: int64
"""마치며
시계열 데이터를 활용하여 의미있는 출력값을 얻기 위한 방법을 배우기 위해, 이번 로그와 다음 로그까지는 시계열에 대한 기초를 다질 것이다.
