자료구조가 중요한 이유
s: 프로그래밍은 뭐하는 건데?
h: 프로그래밍은 데이터를 다루는 거야
s: 그럼 데이터라는 건 뭔데?
h: 데이터란 수와 문자열로 표현된 정보/자료야.
s: 그렇다면 자료구조라는 건 다른 말로 데이터의 구조라는 거네. 그리고 프로그래밍을 더 잘하려면 이 구조를 숙지해야 하고.
h: 맞아 데이터 조직/구조는 코드 실행 속도에 영향을 미쳐서 매우 중요해.
s: 데이터 구조를 바꿀 수 있는 방법이 있어?
h: 응 배열이라는 자료구조를 기준으로 제어하는 방법은 총 4 가지야.
- 읽기 : 활당된 메모리 (엑)셀의 특정 위치 찾기
- 검색 : 특정 값을 찾기. N개의 셀로 이뤄진 배열은 선형 검색에서 최대 N개의 단계가 필요하다.
- 삽입 : 새로운 값 추가. 최악의 시나리오에서 삽입은 N+1 단계 걸림. 셀 맨 앞에 넣으면 요소를 전부 이동시켜 공간을 만드는 N단계가 걸리고 삽입까지 단계까지 포함해서 +1단계가 필요하다.
- 삭제 : 값 제거
s: 하나씩 구체적으로 알고 싶은데 일단 가장 기본적인 검색에 대해 알려줘.
h: 가장 기초적인 검색은 선형 검색인데
🎚 선형 검색 :
컴퓨터가 한 번에 한 셀씩 확인하는 방법.
- 집합 : 중복 값이 허용되지 않는 자료 구조.
- 집합에서 삽입 : 찾고자 하는 값이 있는지 우선 검색을 통해서 확인한 후 N단계 삽입을 진행시 필요한 N+1 단계가 필요하므로 총 2N+1 단계가 걸림.
알고리즘이 중요한 이유
s: 알고리즘은 뭔데?
h: 알고리즘은 연산 (문제 해결)을/를 풀어나가는 구체적인 절차야
👀 이진 검색 :
정렬된 셀의 중간 지점을 연산하고 찾으려는 값의 크기에 따라서 새로운 상한선 또는 하한선을 구하고 새로운 중간 값을 연산한 후 조건에 따라서 상한선/하한선을 바꾸는 패스스루를 하면서 찾고 있는 값이 나올 때까지 또는 모든 값의 검색이 끝날때 까지 반복한다.
int BinarySearch(int arr[], int size, int target)
{
int first = 0;
int last = n - 1;
int mid;
while(first <= last)
{
mid = (first + last) / 2;
if(target == arr[mid])
return mid;
else if(target < arr[mid])
last = mid-1;
else
first = mid + 1;
}
return -1;
}
Big O 표기법 성능 차이
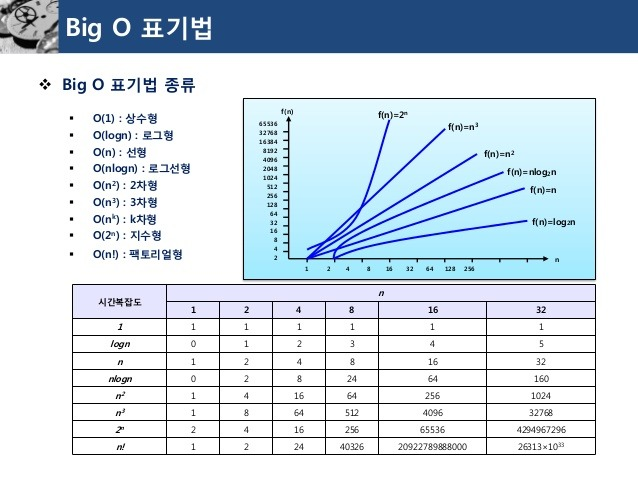
빅 오 표기법
O(N)
- 선형 시간. N 단계가 걸림.
O(log N)
- 로그 시간. 데이터가 두 배로 증가할 때 한 단계씩 늘어남.
O(1)
- 상수 시간. 차수 1. 데이터 크기에 상관 없이 필요한 단계 수가 일정함.
빅 오로 코드 속도 올리기
정렬되지 않은 배열을 오름차순으로 정렬하는 방법.
🎈 버블 정렬: (Bubbling Up Sort)
s: 버블 정렬은 뭐야?
h : 버블 정렬이 실행되는 과정을 설명할게.
배열 내에 연속된 두 항목을 가리켜 비교해서 우측에 더 큰 값이 위치하도록 교환(swap)을 하고 포인터를 우측으로 한 셀씩 이동해. 이렇게 하면 첫번째 항목은 정렬된다. 그다음 정렬되지 않은 다음 항목 (두번째 항목)에서 시작해서 더 이상 교환이 없을 때까지 정렬되지 않은 위치로 돌아와서 반복하면 오름차순으로 배열 안에 있는 모든 숫자가 정렬되는거야.
패스스루 : 위 단계를 한번 실행하는 것.
# 정렬되지 않은 배열 길이
unsorted_until_index = len(list) -1
# 좌측 값이 더 크면 서로 위치 교환
if list[i] > list[i+1]:
list[i], list[i+1] = list[i+1], list[i]s: 시간복잡도 O(n^2) 만큼 시간이 걸린다는 숫자는 대체 어떻게 나온걸까?
h: 우선 n의 차수는 요소의 수 만큼의 단계를 거치는 걸 표현하는데 버블 정렬, 선택 정렬 등에서 패스스루를 한번 끝내고 정렬되지 않은 요소를 갖고 반복해서 패스스루를 실행하는데 10개의 요소를 갖고 있다고 가정하고 수학적으로 표현해보면
10 + 9 + 8 + 7 + 6 + 5 ... + 1
10부터 1까지 더하는 식은 가우스가 초등학교 때 이미 발견한 공식
n * (n + 1) / 2 을 사용하면
10 * (10 + 1) / 2 = 55
를 찾을 수 있어.
하지만 O(n)계산할 때 상수는 무시하기 때문에 단순히 n^2으로 보는 거야. s: 가우스 공식은 뭐야?
h: 가우스 공식도 일종의 알고리즘이니까 간단하게 설명해볼게.
1 ~ 10까지의 수를 각각 역순으로 쓰면
S1 = 10 + 9 + 8 + 7 + 6 + 5 + 4 + 3 + 2 + 1
S2 = 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10
1) 1 + 10 = 11
2) 2 + 9 = 11
3) 3 + 8 = 11
4) 4 + 7 = 11
5) 5 + 6 = 11
6) 6 + 5 = 11
7) 7 + 4 = 11
8) 8 + 3 = 11
9) 9 + 2 = 11
10) 10 + 1 = 11
총 10번을 11로 더하니까
S1 & S2) 10 * 11 = 100
한번 더한 횟수만 찾고 있으니까 100 / 2 하면 55가 정답!
이제 공식으로 바꾸보면
n = 10 의 경우 S = 10 × 11 ÷ 2
n = 100 의 경우 S = 100 × 101 ÷ 2
n = 67 의 경우 S = 67 × 68 ÷ 2
일반화 공식-->
S = (n x (n + 1)) / 2.
빅 오를 사용하거나 사용하지 않는 코드 최적화
🎳 선택 정렬: (Selection of Smallest Sort)
s: 선택 정렬은 뭔데?
h: 선택 정렬의 과정을 간단하게 설명하면...
첫 번째 셀을 임의로 가장 작은 숫자로 정한(선택) 후 좌측에서 우측 방향으로 배열의 각 셀을 첫 번째 셀과 비교하면서 최소값을 찾아. 더 작은 값을 찾으면 해당 값의 위치로 대체하고. 마지막 셀 값까지 비교가 완성되면 가장 작은 값의 인덱스를 보관하고 있게 됨.
해당 인덱스의 값을 패스스루의 시발점에 있는 인덱스의 값과 교환해. 다음 최소값은 정렬되지 않은 나머지 값 (두번째 인덱스)에서 시작해서 동일한 패스스로 과정을 실행하면 오름차순으로 배열이 완벽히 정렬됨.
var lowestNumberIndex = i; // i=0 at first
// 최소값을 찾기 위해서 배열 내에 연속된 두 항목을 가리켜 비교. 최소값이 있는 인덱스 저장.
if(array[i+1) < array[lowestNumberIndex[){
lowestNumberIndex = j;
}
// 배열에서 찾은 최소값과 정렬되지 않은 첫 번째 인덱스에 있는 값 교환
if(lowestNumberIndex != i){
var temp = array[i];
array[i] = array[lowestNumberIndex];
array[lowestNumberIndex] = temp;
}

긍정적인 시나리오 최적화
🎨 삽입 정렬: (Insertion with Temp to Left Sort)
인덱스 1의 값을 임시 변수에 저장한다. 해당 값의 좌측에 있는 값이 임시 변수에 저장된 값보다 크면 좌측의 있던 값을 우측으로 시프트한다. 그럼 임시 변수가 있던 값의 공백은 왼쪽으로 옮겨진다. 옮겨지지 않은 다음 좌측 값과 임시 변수 값하고 비교해서 좌측 값이 더 클 경우에 동일한 방법으로 우측 시프트를 한다.
정렬된 인덱스 1의 값을 제외하고 다음 값에서 시작해서 인덱스를 1씩 올라가면서 완전히 정렬되기 까지 패스스루를 반복한다.
# 인덱스 1의 값을 임시 변수에 저장
position = index # 1
temp_value = array[index]
# 임시 변수에 저장된 값과 좌측 셀에 있는 값 비교해서 좌측 값이 더 크면 교환 (swap).
#다음 좌측값도 같은 임시변수에 있는 값과 비교
while position > 0 and array[position-1] > temp_value:
array[position] = array[position-1]
position = position -1
array[position] = temp_value
해시 테이블(K-Hashed Table)로 빠른 룩업
- 해시 테이블 : 키와 값 쌍으로 이뤄진 값들의 리스트. 평균 룩업 속도 O(1)
- 해싱 : 문자를 가져와 숫자로 변환하는 과정
- 해시 함수 : 글자를 특정 숫자로 변화하는데 사용한 코드. 동일한 문자열로 항상 동일한 숫자로 변환해야 유효함.
- 충돌(collision) : 이미 채워진 셀에 데이터를 추가하는 것
- 분리 연결법 : 충돌이 발생했을 때 셀에 값을 넣는 대신 배열로의 참조를 넣는 방법.
🔑 해시 테이블 삽입
해시 thesaurus["bad"] = "evil"
1 컴퓨터는 키에 해시 함수를 적용한다. BAD = 2 1 4 = 8
2 컴퓨터는 값 "evil" 을 셀 8 에 넣는다. 배열과 유사하게 해시 테이블은 내부적으로 데이터를 한 줄로 이뤄진 셀 묶음에 저장한다.
3 다음 값에도 동일한 패스스루를 한다.
4 "dab" 키를 해싱했는데 동일한 값 즉 8에 추가해야 하면 "evil"이 채워져 있기 때문에 충돌이 발생한다.
5 분리 연결법으로 충돌을 해결한다. 즉 같은 값이 확인되면 컴퓨터는 각 하위 배열의 인덱스 0 을 찾아보고 룩업하는 단어 "dab"을 찾을 때까지 선형 검색을 한다. 값이 없는 위치에 추가한다.
해시 테이블은 충돌이 다수 발생하면 선형 검색이 있어서 성능은 O(N)이 된다
해시 테이블 효율성 결정 요인
- 얼마나 많은 데이터 저장 가능.
- 얼마나 많은 셀 사용 가능
- 어떤 해시 함수를 사용
즉 메모리를 낭비하지 않고 균등하게 분산하면서 충돌을 피해야 한다. 0.7 정도의 부하율 (원소 7개에 / 셀 10 개) 등 이상적인 부하율 설정이 필요하다.
// 중복 찾기 w/out 해시 테이블
function hasDuplicateValue(array){
for(var i=0; i<array.length; i++){
for(var j=0; j<array.length; j++){
if(i !== j && array[i] == array[j]){
return true;
}
}
}
return false;
}
/*
// 중복 찾기 w/ 해시 테이블
테이블에 각 값을 1 지정하는데 1 값이 이미 있으면
중복이므로 return true
*/
function hasDuplicateValue(array){
var existingValues={}; //hash table object
for(var i=0; i<array.length; i++){
if(existingValues[array[i]] == undefined){
existingValues[array[i]] = 1;
} else{
return true;
}
return false;
}스택과 큐로 간결한 코드 생성
스택과 큐는 임시 데이터를 처리할 수 있는 도구이며 제약을 갖는 배열일 뿐이다.
🥫 스택
저장 방법은 배열과 같지만 세 가지 제약 사항이 있다. 데이터는 스택의 끝에만 삽입 가능하고, 끝에서만 읽고 삭제할 수 있다.
재귀를 사용한 재귀적 반복
속도를 높이는 재귀 알고리즘
컴퓨터 언어 중 대다수가 내부적으로 채택한 정렬 알고리즘 = 퀵 정렬.
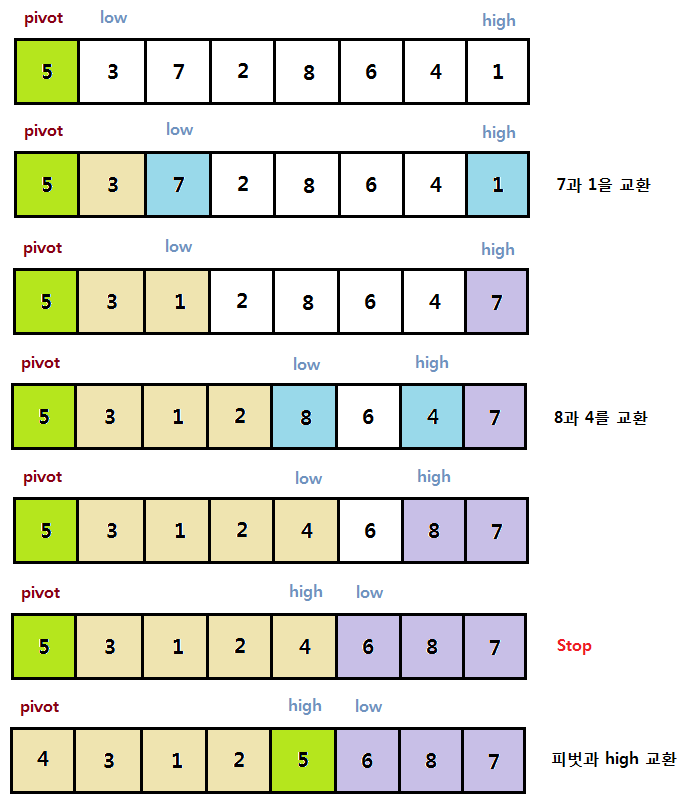
분할
배열 분할 : 임의의 수 (피벗)을 가져와 피벗보다 작은 수는 피벗 좌측 큰 수는 피벗 우측에 두는 것. 우측값 선택, 좌측값 선택 또는 원하는 위치에서 피벗 선택 가능.
class SortableArray
attr_reader :array
def initialize(array)
@array = array
end
def partition!(left_pointer, right_pointer)
# 항상 가장 우측에 있는 값이 피벗
pivot_position = right_pointer
pivot = @array[pivot_position]
# 피벗 바로 좌측에서 우측 포인터를 시작시킨다.
right_pointer -= 1
while true do
while @array[left_pointer] < pivot do
left_pointer +=1
end
while @array[right_pointer] > pivot do
right_pointer -= 1
end
if left_pointer >= right_pointer
break
else
swap(left_pointer , right_pointer)
end
end
# 마지막 단계로 좌측 포인터와 피벗 교환
swap(left_pointer , right_pointer)
# 이어지는 예제에서 나올 quicksort 메서드를 위해 왼쪽 포인터 반환
return left_pointer
end
def swap(pointer_1, pointer_2)
temp_value = @array[pointer_1]
@array[pointer_1] = @array[pointer_2]
@array[pointer_2] = temp_value
end
end
퀵 정렬
퀵 정렬의 효율성
최악의 시나리오
퀵 설렉트
노드 기반 자료 구조
🥨 연결 리스트
연결 리스트 :
- 리스트를 표현하는 자료 구조인데 서로 인접하지 않은 메모리 셀 묶음으뤄 이뤄졌다.
- 컴퓨터 메모리 전체에 걸쳐 여러 셀에 퍼져 있을 수 있는데 이런 각각의 셀을 노드라고 부른다.
- 연결 리스트 내에 다음 노드의 메모리 주소가 저장되어 노드들이 같은 연결 리스트라는 것을 구분한다.
- 셀1에는 데이터 셀2에는 다음 노드의 시작 메모리 주소가 있고 마지막 노드의 링크는 연결리스트가 끝나서 null이 보관된다.
읽기
class LinkedList
attr_accessor :first_node
def initialize(first_node)
@first_node = first_node
end
def read(index)
current_node = @first_node
current_index = 0
while current_index < index do
current_node = current_node.next_node
current_index +=1
return nil unless current_node
end
return current_node.data
end읽기, 검색, 삭제 효율성 - O(N)
삽입 효율성 - O(1)
삽입 및 삭제
원소 맨 앞에 추가하는 경우 O(1)로 나온다, 다음 노드를 가리키는 주소만 바꿔주면 되기 때문이다
단 중간에 삽입할 경우에 주소 변경 요소를 검색해야 해서 동일하게 O(N)이 걸린다. 삭제도 비슷한 이유로 맨 앞에서 O(1) 중간 또는 끝에서는 O(N)이 걸린다.
연결 리스트 다뤄보기
장점 :
리스트를 검사해서 많은 원소 삭제시.
예 :
리스트 삭제
1000개 중 100개의 유효하지 않는 이메일 주소 삭제를 배열로 하면 알고리즘 읽기로
1,000 단계 + 삭제 약 100,000단계 (유효하지 않은 이메일 100개 * N)이 걸린다.
연결 리스트 삭제
그러나 연결 리스트에서는 리스트 전체를 살펴보고 삭제가 필요하면 노드의 링크 주소만 바꾸면 된다.
때문에 삭제마다 1단계만 걸린다. 즉 1000개 중 100개의 유효하지 않는 이메일 주소 삭제를 연결
리스트로 하면 1,000 개의 읽기 단계와 100개의 삭제 단계 = 1,100 단계가 걸린다.
이중 연결 리스트
이중 연결 리스트 :
- 기본 연결 리스트의 단점을 보완, 변형해서 큐에서의 데이터 삽입과 삭제 모두 O(1) 가능.
- 각 노드에 2개의 링크가 있는데 한 링크는 다음 노드를 가르키고 다른 한 링크는 이전 링크를 가리킨다. 즉 처음과 마지막 노드를 모두 기록.
예
class Node
attr_accessor :data, :next_node, :previous_node
def initialize(data)
@data=data
end
end
class DoublyLinkedList
attr_accessor :first_node, :last_node
def initialize(first_node=nil, last_node=nil)
@first_node = first_node
@last_node = last_node
end
def insert_at_end(value)
new_node = Node.new(value)
...
이진 트리 속도 향상
정렬된 배열은 삽입시 다른 항목을 모두 시프트해야 해서 너무 느리고 O(N) 해시 테이블은 검색, 삽입, 삭제 모두 O(1)으로 빠른데 순서 유지가 된다.
배열과 해시 테이블의 단점을 모두 보완하는 자료 구조는 없을까?
바로 이진 트리다 (binary tree) !!!
🌲 이진 트리
이진 트리 규칙 :
- 각 노드의 자식은 0 개나 1개, 2개다
- 한 노드에 자식이 둘이면 한 자식은 부모보다 작은 값, 다른 자식은 부모보다 큰 값을 갖는다.
검색
이진 트리 검색 :
- 찾고 있는 노드의 값을 루트 노트에서 부터 확인
- 찾고 있는 값이 현재 노드보다 작다면 왼쪽 하위 트리 검색
- 찾고 있는 값이 현재 노드보다 크면 오른쪽 하위 트리 검색
각 단계를 수행할 때 마다 값이 들어있을 남은 공간 중 반을 제거하기 때문에 효율성은 O(log N)
삽입
이진 트리 삽입 :
- 이진 트리 검색으로 삽입할 위치를 찾아서 O(log N)
- 좌측 또는 우측 노드에 바로 추가하면된다. 즉 +1
최종 O(log N) + 1 인데 Big O에서는 상수를 무시하기 때문에 O(log N)단계!!!
def insert(value, node):
if value < node.value:
# 왼쪽 자식이 없으면 왼쪽 자식으로 값 삽입
if node.leftChild is None:
node.leftChild = TreeNode(value)
else:
insert(value, node.leftChild)
elif value > node.value:
# 오른쪽 자식이 없으면 오른쪽 자식으로 값 삽입
if node.rightChild is None:
node.rightChild = TreeNode(value)
else:
insert(value, node.rightChild)그래프로 뭐든지 연결
공간 제약 다루기
출처
누구나 자료구조와 알고리즘 - 제이 웬그로우
https://andrew0409.tistory.com/143 [코인하는 프로그래머]
https://program-developer.tistory.com/106
https://www.youtube.com/watch?v=8ZiSzteFRYc&list=PLRx0vPvlEmdDHxCvAQS1_6XV4deOwfVrz&index=2
http://mathcentral.uregina.ca/qq/database/qq.02.06/jo1.html
https://keyzard.org/nb/views/djena5078_222168571838
