2023년 국립국어원 인공 지능 언어 능력 평가: 이야기 완성 과제
cloze task - story infilling
이야기 완성 과제는 주어진 문장들을 논리적으로 연결하는 문장을 생성하는 과제입니다. 이를 통해 문장들 사이의 맥락을 파악하고 연결점을 찾는 과정을 통해 기계의 언어 이해 능력을 향상시키는 데 기여할 수 있으며, 연결 문장을 생성함으로써 언어 생성 능력을 측정할 수 있습니다. 이야기 완성 과제는 인공지능 챗봇, 자동 번역, 문서 요약 등 다양한 분야에서 활용될 수 있습니다.
예시

- 첫번째 문장: 존은 아침 일찍 일어났다.
- 세번째 문장: 그는 공원에서 조깅을 하고 싶었다.
- 예측 문장: 그는 운동화를 신고 문을 나서기 시작했다.
이 경우 예측된 문장("그는 운동화를 신고 문을 나서기 시작했다.")은 주어진 두 문장 사이의 간격을 메우고 더 완전하고 일관된 이야기를 형성합니다.
데이터셋 분석
총 데이터 수: 150,175
train, validation, test 데이터로 구성되어 있다.

- train, validation 데이터의 경우 입력 문장 2개와 출력 문장 1개로 구성되어 있다.
- test 데이터의 경우 입력 문장 2개로 구성되어 있다.
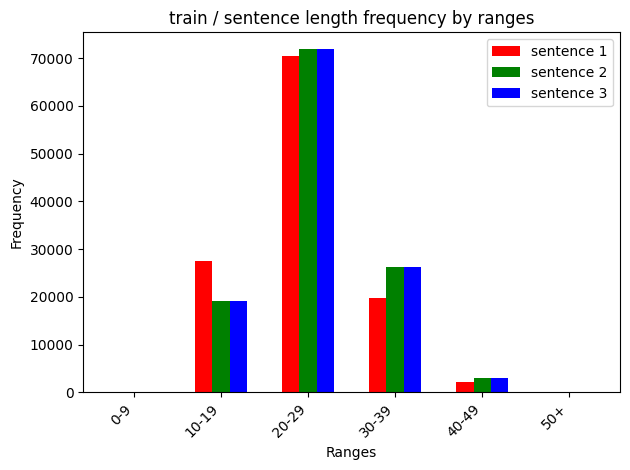
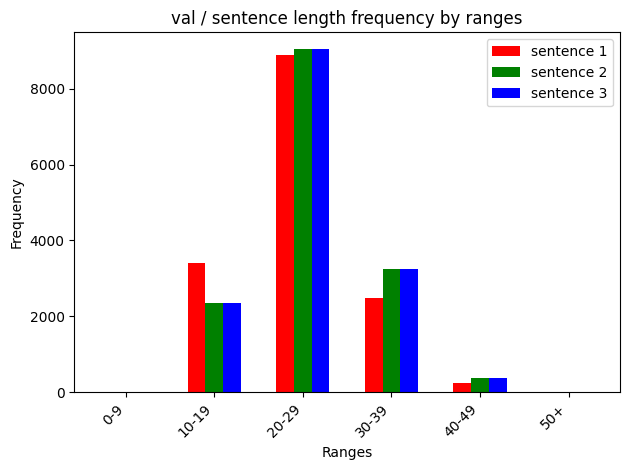
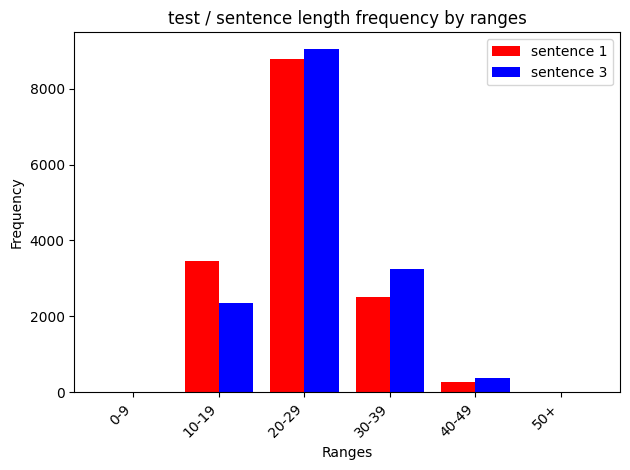
데이터 문장 길이 범위 별 빈도수
train 데이터
validation 데이터
test 데이터
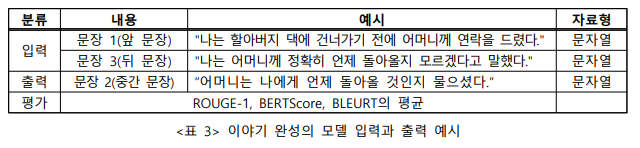
과제 정의
생성된 문장의 품질은 정량적 평가와 정성적 평가를 종합하여 평가됩니다.
평가의 주요 기준은 생성된 문장의 문맥적 및 문법적 정확성, 그리고 논리적 일관성입니다.
-
정량적 평가(50%)
- ROUGE
- BERTScore
- BLEURT -
정성적 평가(50%)
- 다수의 인간 평가자가 순위를 매긴다.

model architecture
huggingface model 중에서 KoBART model을 사용하여 진행하였다.
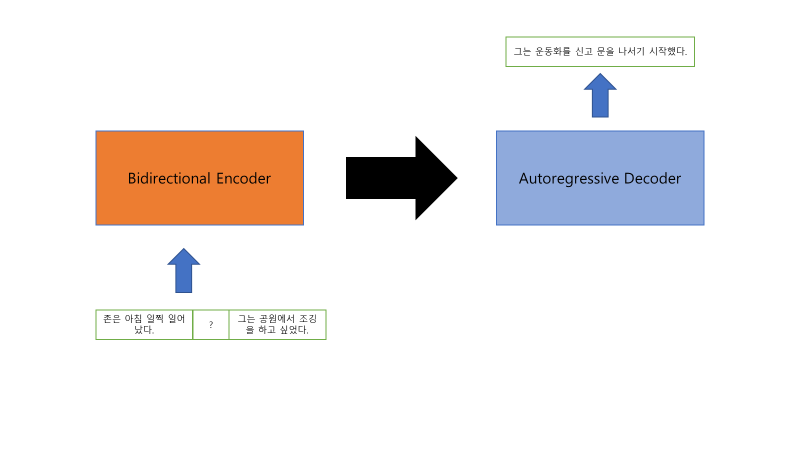
train & eval
문장의 최대 길이를 설정하여 나머지 부분에 대해서는 pad token(숫자 3)을 추가하여 학습을 진행하였습니다.
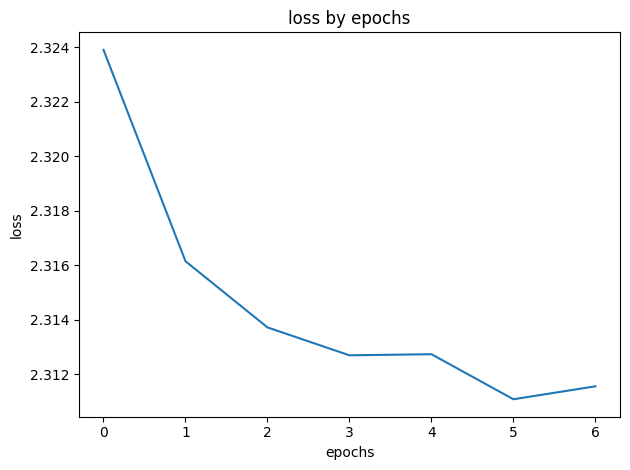
학습 1
train
- epochs: 50
- patience: 3
- lr: 0.001
- batch_size: 16
- input_max_length: 50
- stopped at 8 epochs by earlystopping
- 학습 시간: 7시간 30분
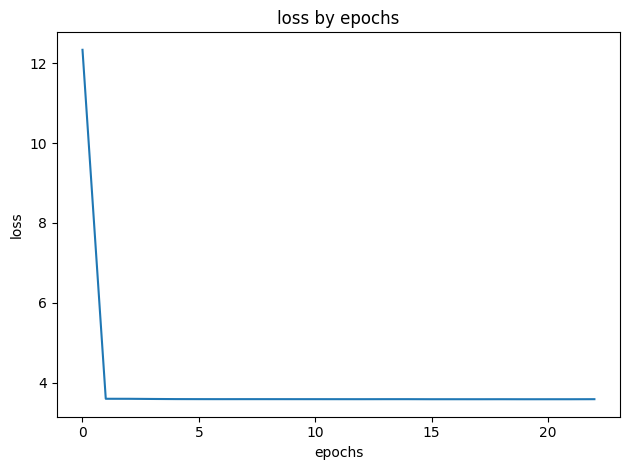
학습 2
train
- epochs: 50
- patience: 3
- lr: 0.001
- batch_size: 16
- input_max_length: 30
- stopped at 23 epochs by earlystopping
- 학습 시간: 20시간 30분
결과
개선해야할 점
loss 값 개선
loss 값이 특정 부분에서 더 이상 개선되지 않고 고정되는 현상이 발생하고 있는데 왜 그런 것인지 파악하여 수정하는 것이 필요하다.
문제에 대한 원인(?)
- batch_size: 16으로만 학습을 진행하였기 때문에 batch_size 값 조정에 따른 변화를 확인할 필요가 있다.
- 모델의 구조: 기본적으로 KoBART는 1개의 문장에 대한 결과값으로 1개의 문장을 출력하는 형식으로 학습이 진행되었기 때문에 2개의 입력 문장에 대한 학습이 모자르기 때문에 이러한 현상이 발생하는 것으로 판단된다.
- encoding: huggingface에서 제공한 BPE tokenizer을 활용하여 tokenization을 진행하였다. wordpiece tokenization을 진행하면 다른 결과가 나올 수도 있다고 생각한다.
모델 직접 구현
최근에 읽은 Unsupervised-Hierarchical-Story-Infilling 논문에 따르면 Vanilla transformer에 살짝 변형을 주어 학습을 시키면 결과가 괜찮다고 주장하고 있다. 해당 논문을 참고하여 직접 모델을 구현하면 좀 더 story infilling 과제에 알맞은 모델을 구축할 수 있을 것 같다.
