
배경
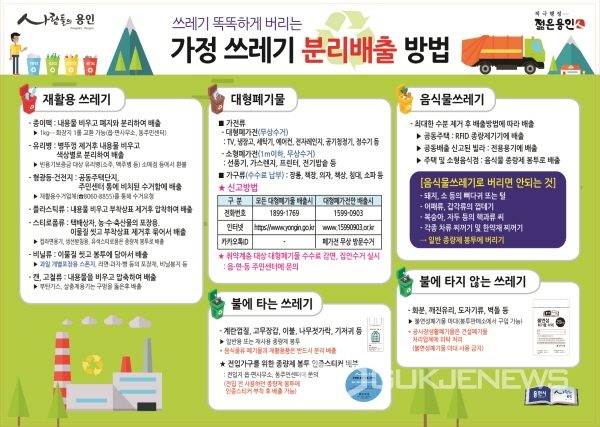 출처: https://www.gukjenews.com/news/articleView.html?idxno=927504
출처: https://www.gukjenews.com/news/articleView.html?idxno=927504
재활용품 분리배출을 실천하기 가장 힘든 이유는 분리배출 방법이 다양하고 많기 때문에 정확하게 알아보기 귀찮다는 것이 가장 큰 이유다.
프로젝트 개요
사용자들이 다양하고 복잡한 쓰레기 분리배출 방법을 보다 편리하게 이해하고 실천할 수 있도록 도와주는 모바일 어플리케이션을 개발하는 것을 목표로 한다.
담당
데이터 전처리 및 모델 학습
데이터셋
클래스 선정 이유
- 환경통계연감에서 발생량 상위 5개 + 플라스틱
- 비닐, 종이, 유리, PET, 플라스틱, 캔
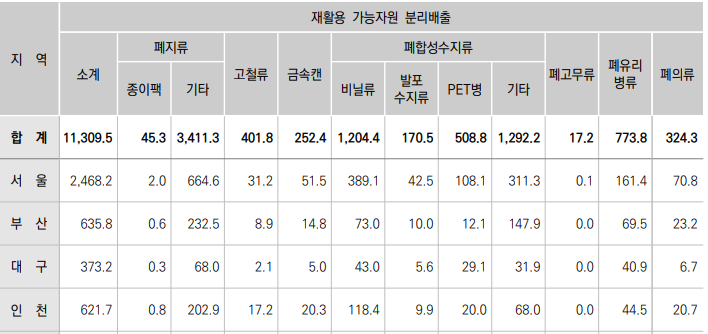 출처: 환경통계연감
출처: 환경통계연감
데이터 분석
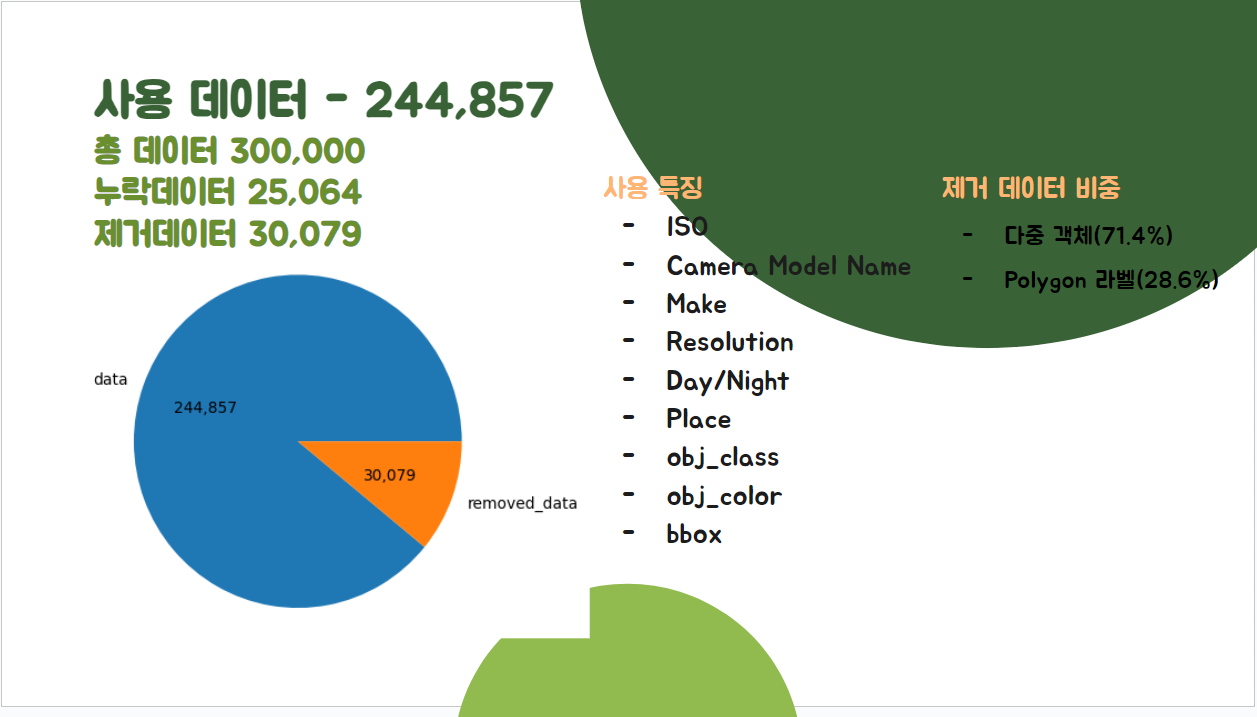
데이터 수
- 전체 데이터 300,000개에서 244,857개 사용
- 추출 특징은 아래와 같습니다
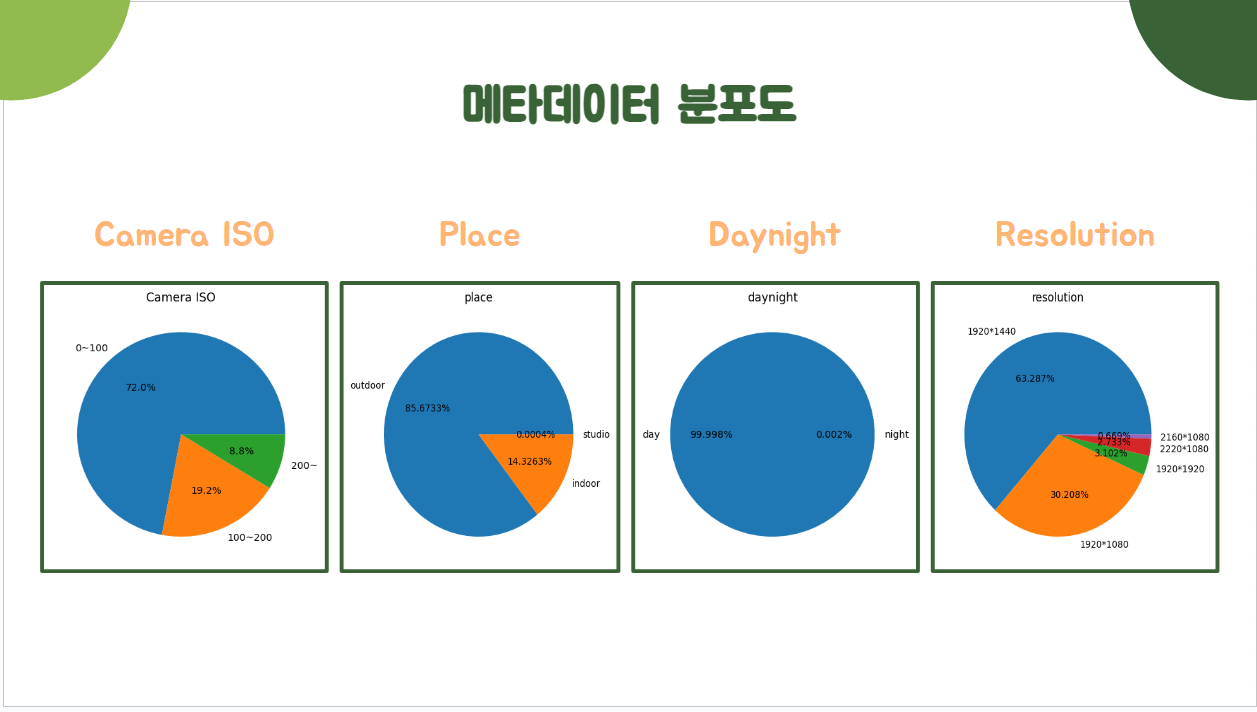
메타데이터별 분포도
- 저녁에 촬영된 데이터가 거의 없어서 추후 필요시 그레이스케일(데이터 증강) 필요
- 데이터의 사이즈가 다양하기 때문에 데이터의 사이즈를 동일한 크기로 변경할 필요가 있음
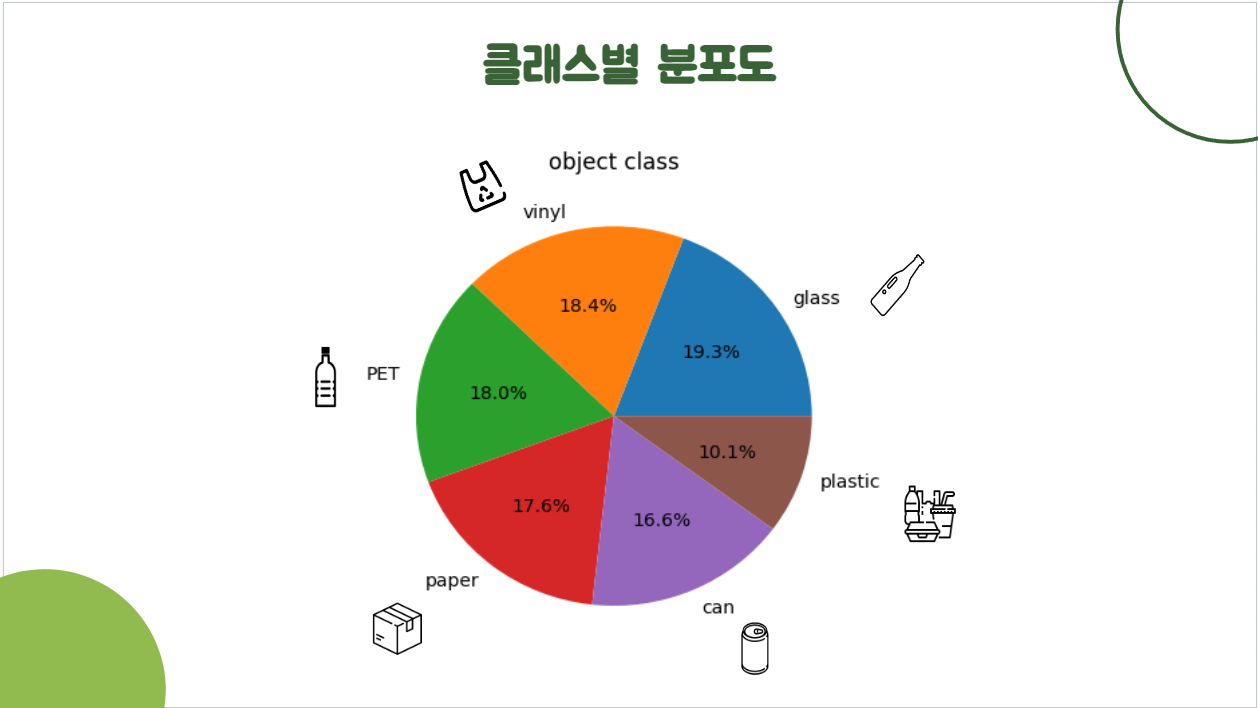
클래스별 분포도
- 플라스틱에 대한 비중이 다른 클래스에 비해 적으므로 추후 데이터를 추가한다면 플라스틱 데이터를 추가할 필요가 있음
데이터 전처리
이미지 데이터 전처리
- img_size: 640 * 640 으로 일괄 조정
라벨 데이터 전처리
- 이미지 데이터 사이즈 변경 시 바운딩 박스 값 재계산
# 이미지의 resize 비율만큼 bbox값 계산
def resize_bbox(image, resized_image, json_file):
with open(json_file, 'r', encoding='utf-8') as j_f:
data = json.load(j_f)
x1 = int(data['Bounding'][0]['x1'])
y1 = int(data['Bounding'][0]['y1'])
x2 = int(data['Bounding'][0]['x2'])
y2 = int(data['Bounding'][0]['y2'])
y_ratio = resized_image.shape[0] / image.shape[0]
x_ratio = resized_image.shape[1] / image.shape[1]
bbox_resized = list(map(round, [x1*x_ratio, x2*x_ratio, y1*y_ratio, y2*y_ratio]))
return bbox_resized- 제공된 바운딩 박스 값을 yolo format으로 변환
- json: [x1,y1,x2,y2] -> txt: object_class x_center y_center img_width img_height
# bbox value를 YOLO format으로 변환
def cvt2YOLO(img_size, bbox):
dw = 1./img_size[0]
dh = 1./img_size[1]
x = (bbox[0] + bbox[1])/2.0
y = (bbox[2] + bbox[3])/2.0
w = bbox[1] - bbox[0]
h = bbox[3] - bbox[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)데이터 분배
- train:val:test // 8:1:1로 나누어 저장
- train_test_split를 사용한 이유는 stratify를 분배에 적용하기 위함
# 데이터 분배 (8:1:1)
def distribute_files(path, exts):
from sklearn.model_selection import train_test_split
images = [x for x in os.listdir(path) if x.split('.')[-1] in exts['image_ext']]
labels = [x.split('_')[0] for x in images]
train_input, test_input, train_target, test_target = train_test_split(images, labels, test_size=0.1, random_state=42, shuffle=True, stratify=labels)
train_input, val_input, train_target, val_target = train_test_split(train_input, train_target, test_size=0.1, random_state=42, shuffle=True, stratify=train_target)
all_files = {'train': train_input, 'val': val_input, 'test': test_input}
for dir, file_list in tqdm(all_files.items(), desc='데이터 분배'):
move_by_dirs(path, dir, file_list)모델 학습
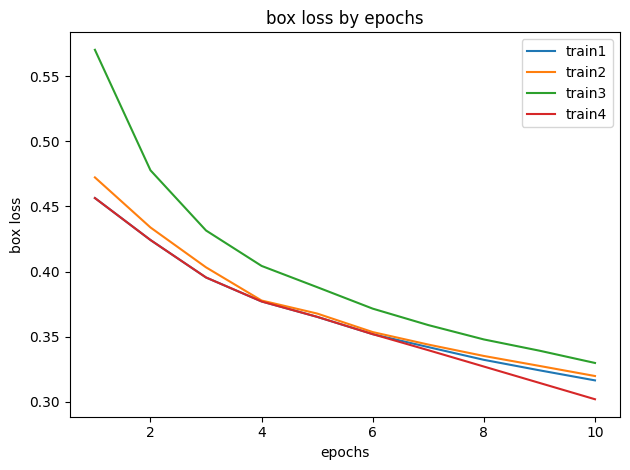
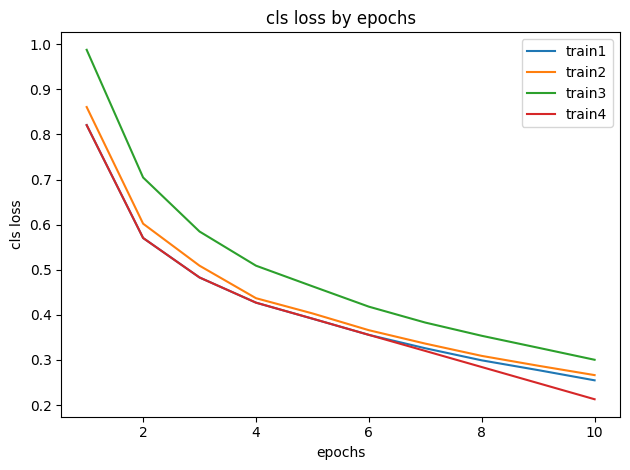
학습 결과
| train1 | train2 | train3 | train4 | |
|---|---|---|---|---|
| epochs | 10 | 10 | 10 | 10 |
| patience | 5 | 5 | 5 | 5 |
| batch_size | 16 | 16 | 32 | 32 |
| optimizer | AdamW | AdamW | AdamW | AdamW |
| learning_rate | 0.01 | 0.001 | 0.01 | 0.001 |
| box loss | 0.31641 | 0.31976 | 0.32979 | 0.31192 |
| cls loss | 0.25473 | 0.2663 | 0.3003 | 0.25236 |
| 학습시간 | 93h | 95h | 93h | 95h |
box_loss
cls_loss
깃허브

개발 초보자
안녕하세요! 올려주신 글 너무 잘 읽었습니다. 한 가지 여쭤보고 싶은 것이 있습니다. AI hub에서 데이터셋을 다운받으려고 하는데 용량이 너무 커서 로컬 환경에 다운이 받아지지 않습니다. 혹시 어떻게 하셨는지 여쭙고 싶습니다.