Abstract
기존의 trasnfromer architecture를 사용하는 방식
- NLP 분야에서 사용
- Vision 분야에서는 attention 기법을 사용해서 convolutional networks와의 결합이나 convolutional networks의 일부를 대체하는 수준에 그침
논문이 제시하는 방식
- Vision 분야에서 사용
- transformer architecture의 제한적인 사용보다 transformer를 이미지 sequence에 직접 적용시킴으로써 이미지 분류 작업에 우수한 성과를 보임
결과
대규모 데이터 pre-trained ViT 모델은 훈련에 적은 리소스를 필요로 하며, 여러 중형 또는 소형 이미지 인식 벤치마크에서 SOTA CNN과 비교하여 뛰어난 결과를 달성
Introduction
NLP 분야에서의 transformer architecture의 성공에 비하여 Vision 분야에서는 CNN이 지배적
- CNN-like architectures with self-attention (Non-local Neural Networks)
- replacing the convolutions entirely (Stand-Alone Self-Attention in Vision Models
논문에서 이미지 처리를 위해 transformer architecture를 활용하는 방식
- 이미지를 패치로 분할하고, 패치의 sequence of linear embeddings를 트랜스포머의 입력으로 제공
- 이미지 패치는 NLP에서의 토큰과 동일한 방식으로 취급
- supervised learning으로 이미지 분류에 대한 모델을 훈련
transformer는 중형 데이터셋에서 비슷한 크기의 ResNet과 큰 차이가 없음
-> transformer는 CNN에 비해 translation equivariance와 locality 같은 특성이 부족하기 때문에 충분하지 않은 양의 데이터로 훈련할 때 일반화가 힘듬
대규모 데이터셋으로 pre-trained하여 데이터의 규모가 작은 task에 활용할 경우, 이미지 인식 벤치마크에서 최고 수준을 달성하거나 뛰어넘는 것으로 나타남
ImageNet-21k dataset과 JFT-300M dataset를 pre-trained 했을 경우
- ImageNet: 88.55%(정확도)
- ImageNet-ReaL: 90.72%(정확도)
- CIFAR-100: 94.55%(정확도)
- VTAB suite of 19 task: 77.63%(정확도)
Related Work
ViT 이전에 transformer를 Vision 분야에서 활용한 사례
- 이미지에 단순한 self-attention를 적용하려면 각 픽셀이 다른 모든 픽셀에 주의를 필요하는 방식은 현실적인 입력 크기로 확장하기 힘듬
- Image Transformer: 전역이 아닌 각 쿼리 픽셀에 대해 로컬 인접에서만 self-attention
- Generating Long Sequences with Sparse Transformers: 글로벌 self-attention에 확장 가능한 근사치 사용
- Scaling Autoregressive Video Models: 극단적인 케이스에만 개별 축을 따라 다양한 크기의 block에 self-attention을 적용
CNN architecture with self-attention
- On the Relationship between Self-Attention and Convolutional Layers: 2x2 패치 사이즈로 인해 낮은 해상도에 유리
- Attention Augmented Convolutional Networks: feature map 추출에 self-attention 활용
Output of CNN with self-attention
- Object detection
-- Relation Networks for Object Detection
-- End-to-End Object Detection with Transformers - Video processing
-- Non-local Neural Networks
-- VideoBERT: A Joint Model for Video and Language Representation Learning - Image classification
-- Visual transformers: Token-based image representation and processing for computer vision - Unsupervised object discovery
-- Object-centric learning with slot attention - Unified text-vision tasks
-- UNITER: UNiversal Image-TExt Representation Learning
-- ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
-- VisualBERT: A Simple and Performant Baseline for Vision and Language - Image GPT
-- Generative pretraining from pixels
Method
Vision Transformer
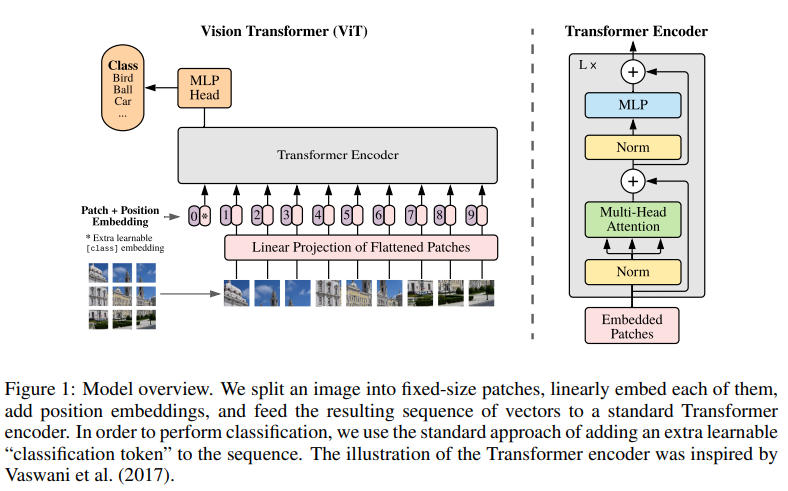
Transformer는 1차원 토큰 임베딩 시퀀스를 입력으로 받음
-> 2D 이미지 처리를 위해 평탄화된 2D 패치 시퀀스로 재구성
- (H,W): (Height, Width)
- C: 채널 수
- (P,P): 이미지 패치 해상도
- : 이미지 패치 수
훈련 가능한 linear projection을 통해 패치를 평탄화하고 D차원으로 매핑
- D: latent vector size
BERT의 [class] 토큰과 유사하게, 임베딩된 패치 시퀀스 앞에 학습 가능한 임베딩을 추가
- : 학습 가능한 임베딩
- : transformer encoder의 출력
- LN: Layernorm
- y: 이미지 representation
- pre-training: 에 classification head는 하나의 hidden layer가 있는 MLP로 구현
- fine-tuning: 에 classification head는 단일 linear layer로 구현
위치 임베딩은 패치 임베딩에 추가되며 1차원 위치 임베딩을 사용
-> 임베딩 벡터 시퀀스는 인코더에 입력으로 사용
Transformer encoder는 MSA(Multiheaded self-attention)와 MLP blocks(2,3)로 구성되어 있음
- (2)
- (3)
- 각 block 이전에 LN(LayerNorm) 적용
- 각 block 이후에 residual connection 수행
Inductive bias
CNN
- 특성에 대해 각 레이어별 지역적 적용
- 국소성(locality): 지역 주변에서만 정보를 처리하는 성질
- 이차원 이웃 구조(two-dimensional neighborhood structure): 이미지에서 주변의 관계와 상호 작용을 나타냄
- 번역 동질성(translation equivariance): 입력과 출력 데이터에 대해 동일한 변환(이동, 회전)을 반영
ViT
- MLP 레이어만 지역적이며 번역 동질성을 가짐
- self-attention 레이어는 전역적
- 이차원 이웃 구조는 제한적으로 사용
-- 이미지를 패치로 자르는 단계에서 사용
-- 위치 임베딩(position embeddings)을 다루는 데 사용
Hybrid Architecture
또 다른 제안 방식 // 하이브리드 모델
- CNN의 특성 맵에서 이미지 패치를 추출
- 추출한 이미지 패치에 패치 임베딩을 투영
- 분류 임베딩 및 위치 임베딩 사용
fine-tuning and high resolution
- 큰 데이터셋에서 ViT 모델을 사전 훈련하고, 다운스트림 작업에 대해 미세 조정하는 방식을 제안
- 사전 훈련된 예측 헤드를 제거하고 다운스트림 클래스 수(K)에 따라 초기화된 FFL(Feedforward layer)를 추가
- 미세 조정할 때 사전 훈련보다 고해상도의 이미지를 사용하며, 패치 크기를 동일하게 유지하여 더 큰 유효한 시퀀스 길이를 확보
- ViT는 메모리 제약을 벗어나지 않는 한 임의의 시퀀스 길이를 처리할 수 있으며 사전 훈련된 위치 임베딩을 원래 이미지 위치에 따라 2차원 interpolation을 통해 조정
Experiments
Setup
Pre-train datasets
- ILSVRC-2012 ImageNet dataset with 1k classes and 1.3M images
- ImageNet-21k with 21k classes and 14M images
- JFT with 18k classes and 303M high-resolution images
- 다운스트림 작업의 테스트 세트를 기준으로 사전 훈련 데이터셋을 중복 제거
Transfer datasets
- 19-task VTAB classification suite
-- Natural: Pets, CIFAR
-- Specialized: medical, satelite imagery
-- Structured: 기하학(Geometric)과 지역적(Localization)인 이해가 필요
Model Variants
Comparison to state of the art
이미지 분류 벤치마크에 대한 state-of-the-art model과의 비교
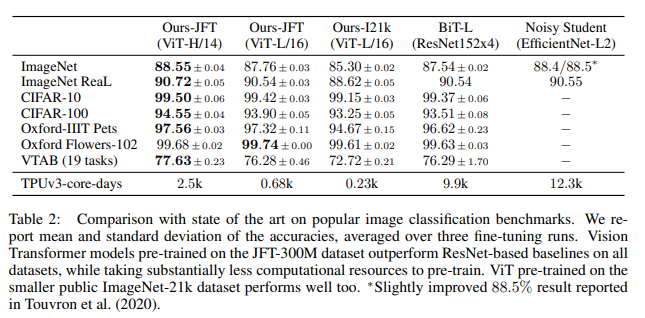 - JFT-300M 데이터셋: ViT > ResNet-based
- ImageNet-21k 데이터셋: ViT > 타 모델
- JFT-300M 데이터셋: ViT > ResNet-based
- ImageNet-21k 데이터셋: ViT > 타 모델
VTAB 작업 그룹 Natural, Specialized 및 Structured 작업에 대한 성능 분석
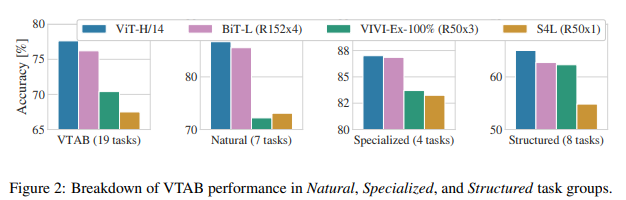 - ViT 모델이 타 모델에 비해 모든 task에 대해 높은 accuracy를 가진 것을 확인할 수 있다
- ViT 모델이 타 모델에 비해 모든 task에 대해 높은 accuracy를 가진 것을 확인할 수 있다
Pre-training data requirements
데이터셋 크기에 따른 모델들의 성능 비교
 - 큰 데이터셋 사전학습의 경우 ViT가 좋음
- 작은 데이터셋 사전학습의 경우 ViT가 좋지 않음
- 큰 데이터셋 사전학습의 경우 ViT가 좋음
- 작은 데이터셋 사전학습의 경우 ViT가 좋지 않음
Inspecting vision transformer
self-attention 결과

Self-supervision
ViT-L/32의 RGB 값의 초기 선형 임베딩 필터
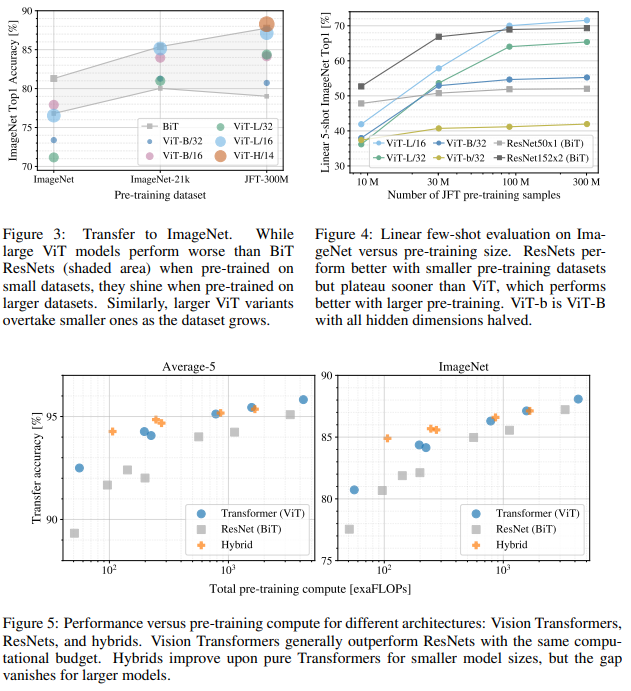
 ViT-L/32의 위치 임베딩의 유사성(cosine similarity)
ViT-L/32의 위치 임베딩의 유사성(cosine similarity)
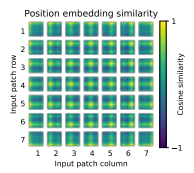 ViT-L/16의 헤드 및 네트워크 깊이에 따른 주목 받는 영역의 크기
ViT-L/16의 헤드 및 네트워크 깊이에 따른 주목 받는 영역의 크기
Conclusion
초기 패치 추출 단계를 제외하고 이미지 특정 inductive bias를 사용 X
- 대규모 데이터셋에서 좋은 성능
- 저렴한 사전학습 비용
Future work
- Detection과 segmentation
- self-supervised learning
마무리
- Transformer의 끝은 어디까지 인가..
- 대규모 데이터셋에 사전 학습된 모델의 경우 좋은 성능을 보인다는 장점이 있지만, 대다수의 경우 대규모 데이터셋은 커녕 대규모 사전학습을 진행할 환경조차 없을 것으로 생각된다. 그래서 직접 학습을 진행하기에는 무리일 것으로 보인다.
출처
