Abstract
Story infilling은 내용에서 빠진 부분에 들어갈 단어를 예측하는 것을 의미합니다.
기존 조건부 언어 모델
- story infilling task에서 언어의 유창성과 일관성을 새로움과 다양성과 균형있게 유지하는데 어려움이 있음
논문에서 제시하는 방식
- 계층적 언어 모델
- 문장 생성 과정을 2개의 과정(모델)으로 분리
- 희귀한 단어들을 선택
- 첫번째 과정의 결과물을 기반으로 텍스트를 생성 - 희귀한 단어를 고르는 high entropy 작업을 단어 샘플링 모델로 강등시킴으로써, 그러한 단어에 조건을 맞춘 2단계 모델은 다양성을 희생하지 않고 가능한 문장을 검색함으로써 높은 유창성과 일관성을 달성
Introduction
Text infilling은 cloze task의 한 형태로, 텍스트에서 일련의 단어 또는 구절을 제거하고 대체할 내용을 요청하는 작업을 포함합니다. 그리고 생성된 텍스트에서 살펴봐야할 사항은 다음과 같습니다.
- 텍스트 유창성
- 전체 이야기와의 일관성
- 일반적이거나 명백하지 않은 텍스트 => 창의성
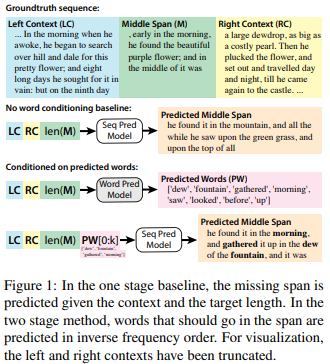
논문에서는 생성작업을 두 단계로 나누어 진행합니다.
- 첫 번째 단계: 랜덤 샘플링
- 첫 번째 모델은 텍스트에서 예측하기 희귀한 단어를 무작위로 선택
- 이렇게 선택된 단어는 텍스트에 다양성과 특이성을 부여 - 두 번째 단계: 텍스트 생성
- 두 번째 모델은 첫 번째 단계에서 선택한 단어를 beam search를 사용해 텍스트를 생성
- beam search는 여러 문장 중 가장 적절한 문장을 찾아내는데 도움을 줌
이렇게 두 번의 단계를 통해 텍스트를 생성함으로써, 흥미로운 내용과 품질 높은 텍스트를 만들어냅니다. 랜덤 샘플링은 텍스트에 색다른 내용을 도입하고, beam search를 사용하여 생성된 텍스트가 자연스럽고 일관성 있게 유지됩니다.
Related work
계층적 신경망 방법은 개별 단어보다 높은 수준의 정보를 고려할 수 있으며, 텍스트 생성 과정을 조건화하기 위한 구조화된 표현이 텍스트 생성에 영향을 미치는 두 수준의 계층을 고려합니다.
Method
논문에서 제시하는 방식은 고정 길이의 양쪽 context에서 가변 길이 텍스트 범위를 예측합니다.
모델은 self-attentive transformer를 사용하며 인코더는 context를 입력으로 받고 디코더는 span(빈칸)을 예측합니다.
word prediction
- 입력: context
- 출력: rare words(low frequency words)
개념적으로, 정보-이론적인 의미에서 rare words는 더 밀도 있는 정보 내용을 가지고 있다.Conceptually, rare words have a denser information content in an information-theoretic sense (Sparck Jones, 1972; Shannon, 1948)
word-conditioned
- 모델: transformer
- 입력: 양쪽 context, 출력 길이, word prediction의 출력 값
- 출력: 가운데 context
훈련 시 대상 텍스트의 길이의 반 이하까지 균일하게 샘플링된 "k"개의 단어 목록을 span에서 선택하여 모델을 조건화합니다. 그리고 추론 시에는 이 모델은 앞서 설명한 단어 생성 모델에서 제공된 조건화 단어를 사용합니다.
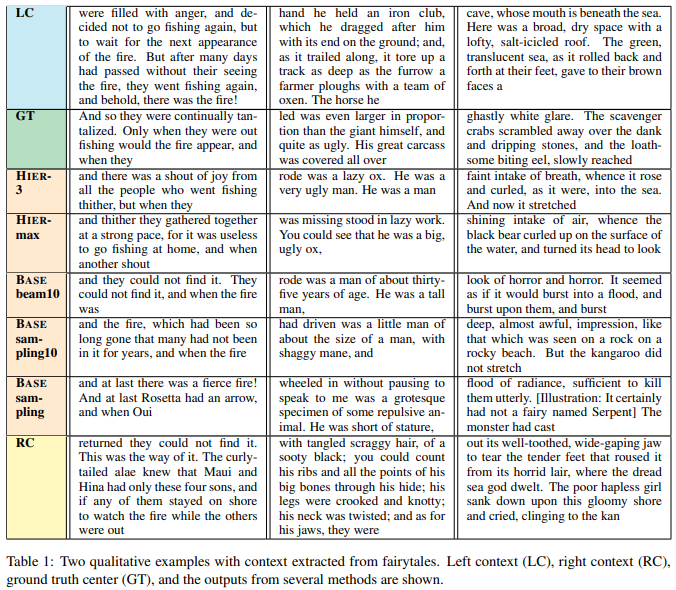
기존 모델
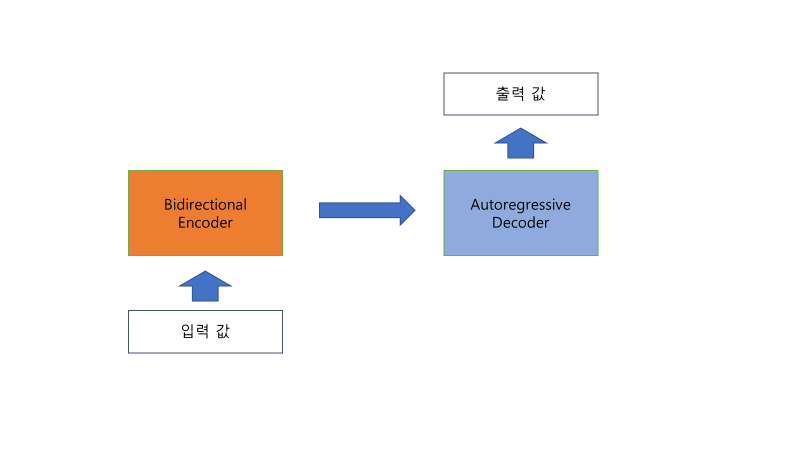
모델에서 제시하는 방식
Experiments and Results
Experimental Setup
- Toronto Book Corpus(TBC), 1.2B words
- 모든 책 중 5%를 검증 및 테스트용으로 사용
- training 예제는 각각 양쪽에 50개의 토큰 context가 있는 5에서 50 토큰 길이의 대상 시퀀스로 구성
- 언어적 경계가 없음 => context가 단어 중간에서 시작하거나 끝날 수 있음
Model parameter
model architecture: "Attention is all you need" 논문 구조를 그대로 사용
parameter
- attention_dropout: 0.1
- batch_size: 4096
- dropout: 0.2
- ffn_layer: dense_relu_dense
- filter_size: 2048
- hidden_size: 512
- kernel_height: 3
- kernel_width: 1
- label_smoothing: 0.0
- learning_rate: 0.2
- learning_rate_constant: 2.0
- learning_rate_decay_rate: 1.0
- learning_rate_decay_scheme: "noam"
- learning_rate_decay_steps: 5000,
- learning_rate_warmup_steps: 8000,
- num_heads: 8
- num_hidden_layers: 6
- optimizer: "Adam"
- optimizer_adam_beta1: 0.9
- optimizer_adam_beta2: 0.997
- optimizer_adam_epsilon: 1e-09
- pos: "emb"
- self_attention_type: dot_product
- train_steps: 1,000,000
Evaluation
평가는 automatic evaluation과 human evaluation을 진행합니다.
Automatic evaluation
- 검증 데이터셋
- 10,000 spans of 길이 15-30
- 3가지 지표를 통해 평가
- sub-token perplexity: 언어 모델이 sub-token을 얼마나 정확하게 예측하는 측정하는 지표
- generation diversity: 생성된 텍스트가 얼마나 다양한지를 측정한 지표
- dist-k:
Human evaluation
- 50~130 subword 길이를 가진 문단을 사용하며, 문단 내 어디에서든 15~30 subword 길이의 일부 영역을 무작위로 대체
- 각 문단의 두 가지 instance를 제시, 선택된 span을 제외하고는 내용이 동일
- 수정된 span은 각 문단에서 강조되었으며, 문맥을 고려할 때 어떤 강조된 부분이 더 나은지 평가

Results
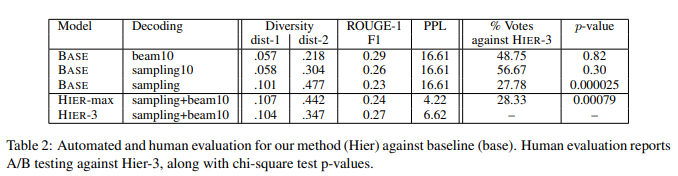
- 다양성은 BASE기준으로 beam search < sampling10 < sampling 순으로 높다
- human evaluation에서 sampling10과 beam이 Hier-3 방법을 능가하지만, 다양성이 낮다
- human evaluation에서 Hier-3이 Hier-max에 비해 좋은 평가를 받았다
- Hier-3은 Base/sampling10과 human evaluation에서 유사하지만 높은 다양성을 가지고 있습니다
Conclusions and Future Work
결론적으로, story infilling에 대한 계층적 접근이 유창하고 일관성 있는 생성 텍스트와 다양성 및 흥미로움을 균형잡는 효과적인 전략임을 보여줍니다. 향후 연구는 삽입 기반 아키텍처와 독립적인 하위 단어 대신 n-그램 구문을 조건으로 사용하는 방법 등을 탐구할 수 있을 것입니다.
개인적으로 생각했을 때 성능이 그렇게 뛰어난 것 같지는 않아서 모델을 필드에서 직접 사용하는 것은 고려를 해봐야 할 것 같다. 또한, 논문에 대한 코드를 제공하지 않고, word prediction의 transformer model 학습 데이터셋의 구조도 명확하게 제공하지 않아서 모델이 제시하는 방식이 정말로 효과가 있는지 의문이 든다. 앞으로는 code를 제공하는 논문을 위주로 읽어서 논문이 제시하는 방식을 좀 더 명확하게 공부하고 싶다.
출처
- https://www.seas.upenn.edu/~ccb/publications/story-infilling.pdf
- https://arxiv.org/abs/1706.03762
- Karen Sparck Jones. 1972. A statistical interpretation of term specificity and its application in retrieval. Journal of documentation, 28(1):11–21.
