Abstract
기존 DNN 모델
- 방대한 양의 데이터 필요
- sequences to sequnces를 mapping하는데 어려움이 있음
- 긴 문장에 대해서 처리가 힘듬
논문에서 제안하는 방식
- 다층 구조의 LSTM으로 입력 시퀀스를 고정 차원 벡터에 mapping하고 다른 LSTM으로 해당 벡터를 decoding
- 입력 시퀀스를 역순으로 변환 -> 학습 난이도를 낮춰 모델의 성능 향상
모델 성능
- WMT'14 English to French translation task dataset 기준
- Statistical Machine Translation(SMT) system BLEU score 33.3
- 논문에서 제안하는 방식 BLEU score 34.8
- SMT system + LSTM BLEU score 36.5
Introduction
전통적인 sequnce model은 입력과 출력의 크기가 같다고 가정한다. 이는 question answering과 같은 문제에 대해서 효과적이지 못하다고 한다.
본 논문에서는 하나의 LSTM을 사용하여 입력 시퀀스를 한 번에 한 번씩 읽고 큰 고정 차원 벡터 를 얻은 다음 다른 LSTM을 사용하여 해당 벡터에서 출력 시퀀스를 추출하는 방식을 제안한다.
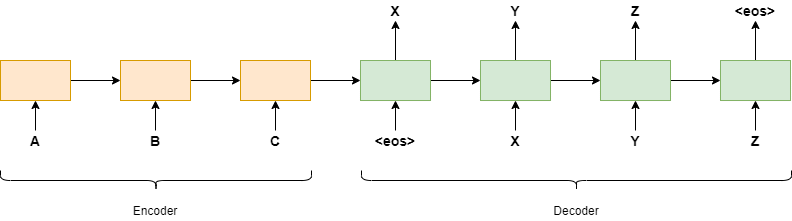
위 예시는 입력 값으로 "ABC"가 주어진다고 가정하면, 이 입력 값을 역순으로 변환하여 "CBA"로 만들고 decoding LSTM을 사용하여 "XYZ"와 같은 시퀀스를 출력하는 과정을 보여줍니다.
The model
RNN은 입력 시퀀스와 출력 시퀀스에 길이가 같다는 전제하에 학습을 진행하는 한계점이 있다.
- 입력 시퀀스: (x_1,...,x_T)
- 출력 시퀀스: (y_1,...,y_T)
위와 같은 문제를 해결하기 위해서 가장 간단한 방법은 하나의 RNN은 입력 시퀀스를 고정된 크기의 벡터로 mapping하고, 그 벡터를 다른 하나의 RNN으로 타겟 시퀀스로 mapping하는 것이다.
- 조건부 확률: p(y_1,...,y_T'|x_1,...,x_T)
- 입력 시퀀스: (x_1,...,x_T)
- 출력 시퀀스: (y_1,...,y_T') *T'의 길이는 T와 다를 수 있음
- 고정된 크기의 context vector: v
- decoder의 출력 값: (y1, . . . , yT)
본 논문에서 제안하는 방식은 위 예시와 다른 점이 3가지 있다.
첫째, 2개의 LSTM을 사용했다. 입력 시퀀스를 위한 LSTM과 출력 시퀀스를 위한 LSTM
둘째, 다층 LSTM이 얕은 LSTM보다 성능이 좋아서 4개의 층으로 구성된 LSTM을 사용했다.
셋째, 입력 문장의 순서를 바꿈으로서 모델의 성능을 향상시켰다. abc -> cba
Experiments
Dataset
- WMT'14 English to French dataset
- 348M 프랑스어 단어와 304M 영어 단어로 구성된 12M 문장
- Out of Vocabulary -> "UNK" token
- 입력 언어: 160,000개의 최빈 단어
- 출력 언어: 80,000개의 최빈 단어
Decoding and Rescoring
- S: 입력 문장
- T: 라벨
- 좌우 beam search decoder를 활용하여 가장 가능성이 높은 번역을 검색한다.
We search for the most likely translation using a simple left-to-right beam search decoder which maintains a small number B of partial hypotheses, where a partial hypothesis is a prefix of some translation.
Reversing the source sentences
소스 문장과 타겟 문장을 concatenate할 때, "minimal time lag"문제가 발생
- 이 문제를 해결하기 위해 문장을 reverse하여 입력 문장의 단어와 대상 문장의 단어 간의 평균 거리를 유지하고 결과적으로 모델 성능을 향상
- minimal time lag: 행동 간의 지연이 발생하는 것을 말한다.
Training details
- LSTM 레이어 4개
- 각 레이어에 1000개의 셀
- 각 word embedding 차원은 1,000
- 입력 vocabulary size는 160,000
- 출력 vocabulary size는 80,000
- uniform distribution between -0.08 and 0.08
- 7.5 epochs
- SGD without momentum with 0.7 학습률, 5 epochs 후 0.5 epoch마다 학습률 절반
- 128 batch size
- 데이터셋의 데이터의 문장의 길이가 다양해서 mini-batch를 하여 학습을 진행할 경우, padding값이 많은 데이터의 경우 학습에 방해가 되기 때문에 문장의 길이를 비슷하게 맞추기 위해서 작업을 진행
parallezation
- 본 논문에서는 4개의 층으로 구성된 LSTM 모델을 사용합니다. 그래서 각 층마다 1개의 GPU는 LSTM 연산을 위해 다른 하나는 softmax에 할당하여 병렬 처리를 통해 연산 속도를 높이는 결과를 보였습니다.
- GPU 한 개가 1,700 단어를 1초에 처리
-> GPU 8개로 병렬 처리하여 6,300개의 단어를 1초에 처리
Results
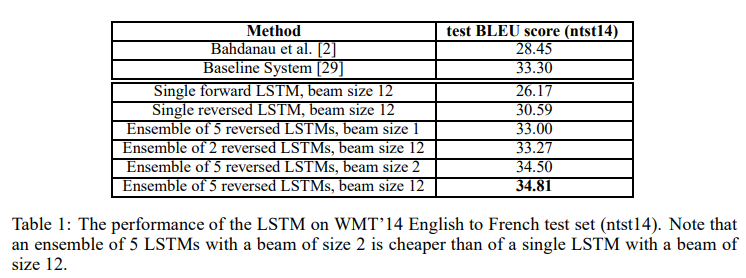
- 전반적으로 reversed LSTM과 ensembled LSTM이 성능이 뛰어난 것으로 보인다.
- 최고 성능은 Ensemble of 5 reversed LSTMs, beam size 12으로 BLEU score 34.81을 기록했다.
Performance on long sentences
- 밑에 예시를 보면, 긴 문장에 대해서도 성능이 나쁘지 않은 것을 볼 수 있다.

Conclusion
본 논문에서는 기존 SMT system에서 탈피하여 encoding과 decoding으로 구간을 여러 개의 LSTM 모델로 구성하는 방법을 제안한다. 이 모델 구성은 입력과 출력의 크기를 같게 해야 한다는 큰 문제점을 극복할 수 있는 방법으로 번역을 할 때 좀 더 정확한 결과를 도출할 수 있다. 또한, 입력 시퀀스를 역순으로 변환 함으로써 학습 난이도를 낮출 뿐 아니라 긴 문장에 대해서도 보다 나은 성능을 보여준다.
다만 아쉬운 점은 논문에서는 RNN이 번역 문제에서도 시퀀스의 역순을 통해 간단하게 학습 가능할 것이라는 추론만 있다는 것이다.
출처
