05 트리 알고리즘
05-1 결정트리
- 결정트리: 예/아니오 질문을 이어가며 정답을 찾아가는 알고리즘. 예측 과정이 직관적이며 성능이 좋음.
- 불순도: 최적의 질문을 찾는 기준. 정보이득을 통해 부모 노드와 자식 노드의 불순도 차이를 최대화함.
- 정보이득: 부모 노드와 자식 노드 간의 불순도 차이.
- 가지치기: 결정트리의 과도한 성장을 방지하는 방법.
- 특성 중요도: 각 특성이 결정트리의 불순도를 얼마나 감소시켰는지 나타내는 값.
주요 함수
-
info(): 데이터프레임의 요약 정보를 출력.
-
describe(): 수치형 데이터의 기본 통계량(최소, 최대, 평균 등)을 제공.
-
DecisionTreeClassifier: 결정트리 모델을 생성하는 사이킷런 클래스.
criterion: 불순도 측정 방법 (기본값: 'gini', 'entropy' 선택 가능)max_depth: 트리의 최대 깊이 지정max_features: 분할을 위한 특성 수 지정
트리 시각화
- plot_tree(): 결정트리 모델을 시각화하여 구조를 확인할 수 있음.
예시 코드
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.tree import plot_tree
# 데이터 준비
X, y = load_data() # 데이터 로딩
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 모델 훈련
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# 모델 시각화
plot_tree(clf)-
로지스틱 회귀로 와인분류하기
-
다운로드 주소: http://bit.ly/wine_csv_data

-
각 열의 데이터 타입과 누락된 데이터가 있는지 확인하는데 유용
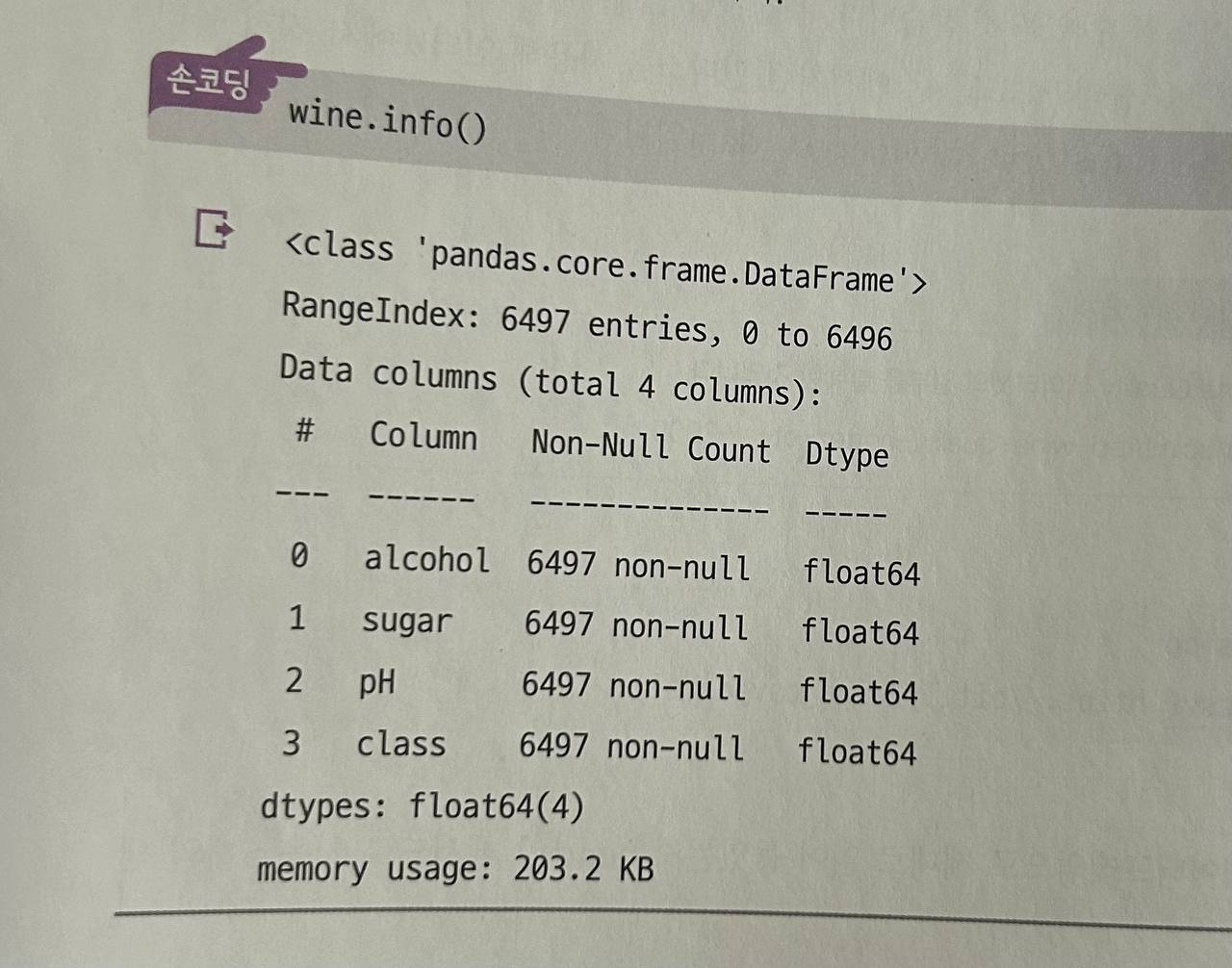
-
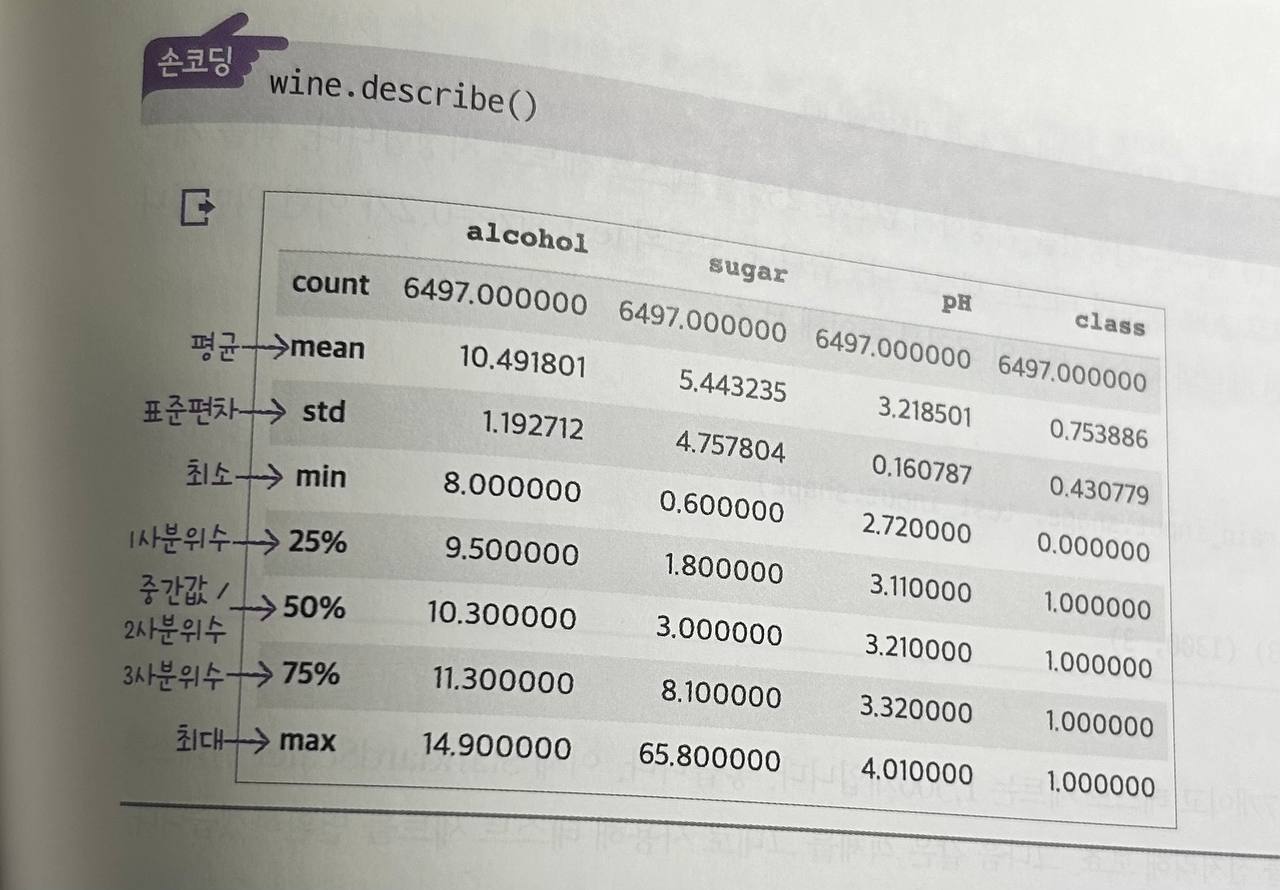
descibe(): 열에 대한 통계를 출력해줌
StandardScaler 클래스를 사용해 훈련세트를 전처리 -> 테스트 세트를 변환

표준점수로 변환된 train_scaled와 test_scaled를 사용해 로지스틱 회귀모델 훈련
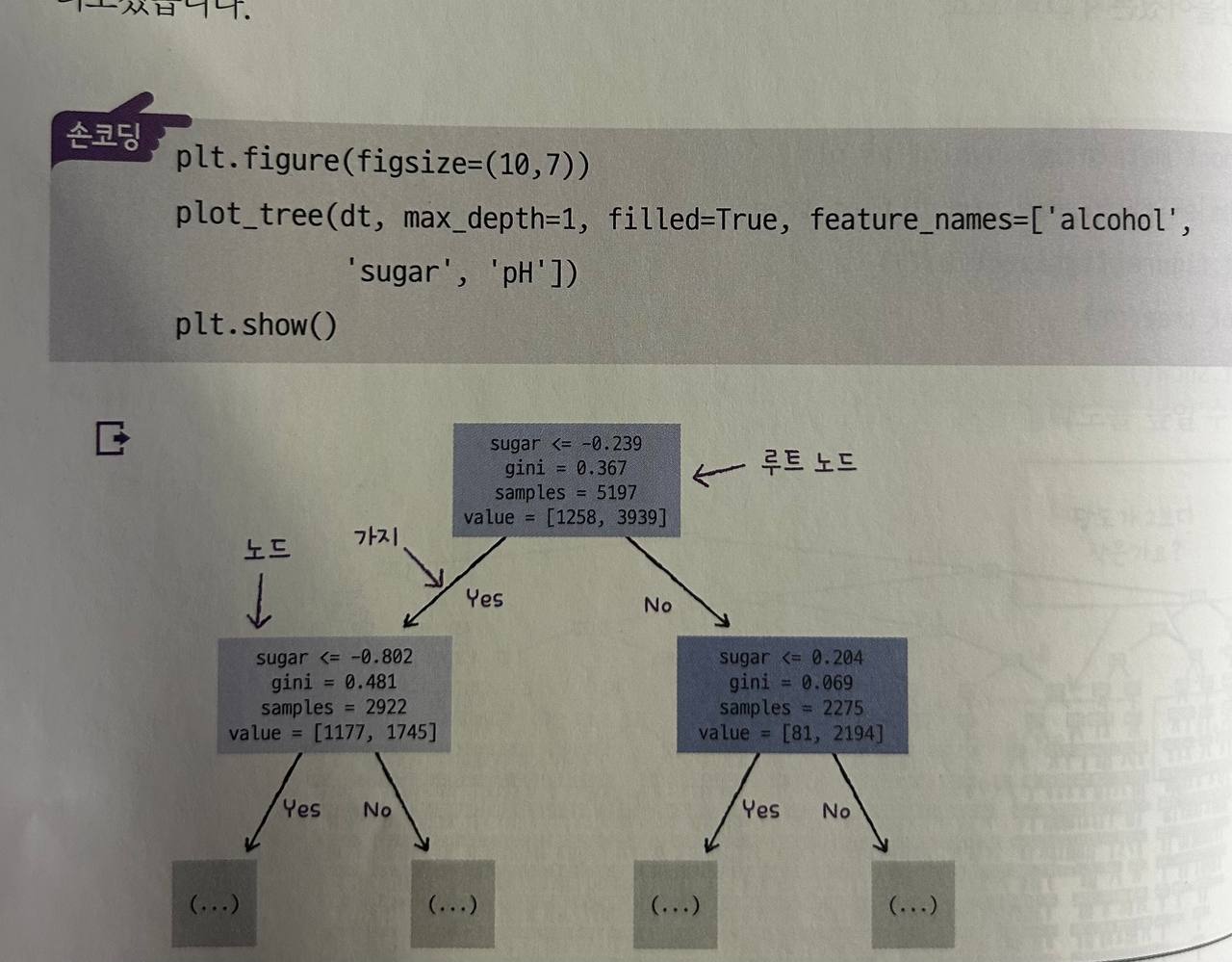
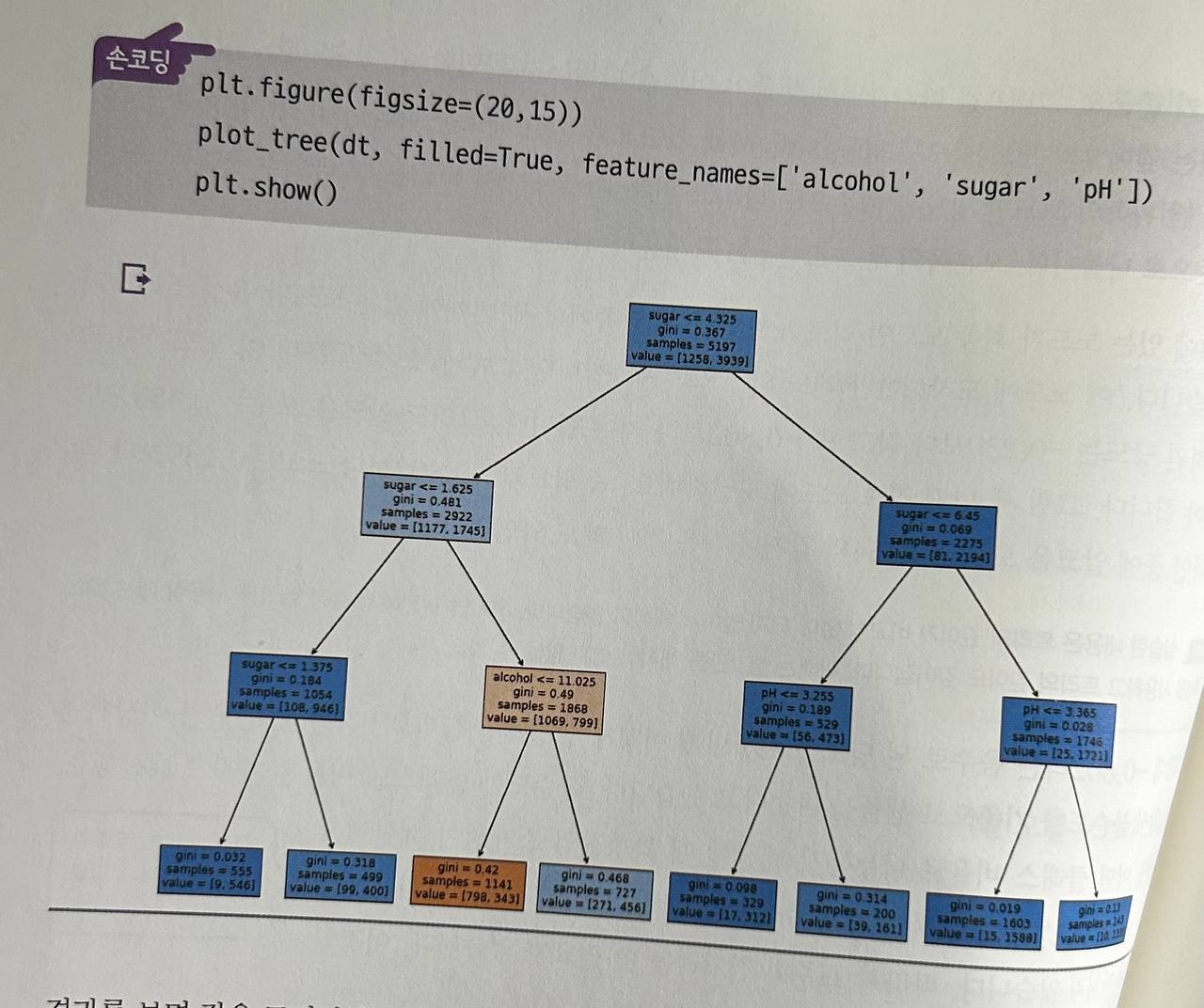
훈련세트(train_input)와 테스트 세트(test_input)로 결정트리 모델을 다시 훈련
05-2 교차 검증과 그리드 서치
-
검증세트: 모델을 평가할 때 테스트 세트를 사용하지 않고, 훈련 세트에서 분리한 데이터.
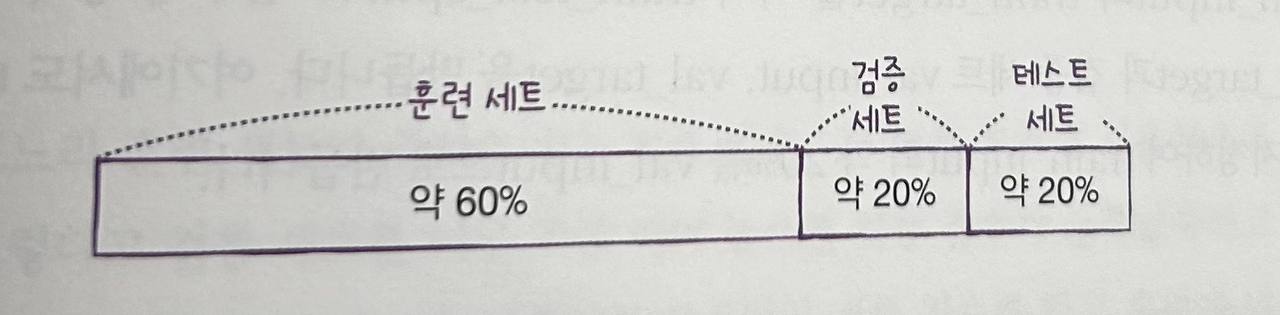
-
판다스로 CSV데이터를 읽음


-
교차 검증: 훈련 세트를 여러 개의 폴드로 나누어 검증하는 방법. 각 폴드가 검증 세트 역할을 함.
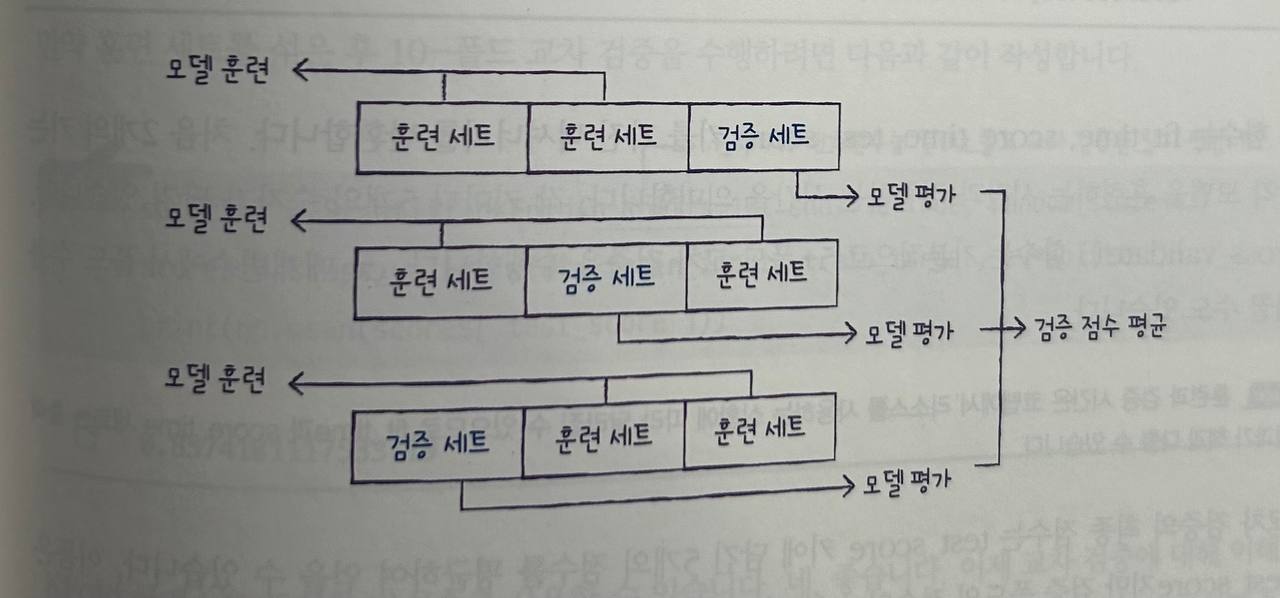
-
그리드 서치: 하이퍼파라미터의 최적값을 자동으로 찾는 방법. 여러 하이퍼파라미터 조합을 시험하여 최적의 모델을 선택.
주요 함수
- cross_validate(): 교차 검증을 수행하는 함수. 평가 지표를 설정하여 검증할 수 있음.
- GridSearchCV(): 그리드 서치를 수행하여 최적의 하이퍼파라미터를 찾는 클래스.
예시 코드
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
# 그리드 서치를 위한 파라미터 설정
param_grid = {'max_depth': [3, 5, 7], 'min_samples_split': [2, 5]}
# 모델 생성
clf = DecisionTreeClassifier()
# 그리드 서치 실행
grid_search = GridSearchCV(clf, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 최적 하이퍼파라미터 확인
print(grid_search.best_params_)- 하이퍼파라미터 튜닝
- 먼저 GridSearchCV클래스를 임포트하고 탐색할 매개변수와 탐색할 값의 리스트를 딕셔너리로 만듦

- GridSearchCV클래스에 탐색 대상 모델과 params 변수를 전달하여 그리드 서치 객체를 만듦

05-3 트리의 앙상블
-
앙상블 학습: 여러 모델을 결합하여 예측 성능을 개선하는 방법.
-
랜덤 포레스트: 여러 결정트리를 훈련시켜 예측 성능을 높이는 방법.
- 부트스트랩 샘플링: 데이터를 랜덤하게 추출하여 트리들을 학습시킴.
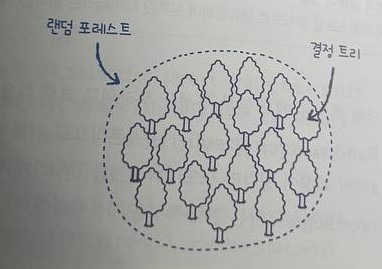
- cross_validate()함수를 사용해 교차검증을 수행

- 부트스트랩 샘플링: 데이터를 랜덤하게 추출하여 트리들을 학습시킴.
-
엑스트라 트리: 랜덤 포레스트와 유사하나, 트리 분할 시 랜덤하게 분할하여 과대적합을 방지.
-
그라디언트 부스팅: 여러 트리를 순차적으로 훈련하여 이전 트리의 오류를 보완하는 방법.
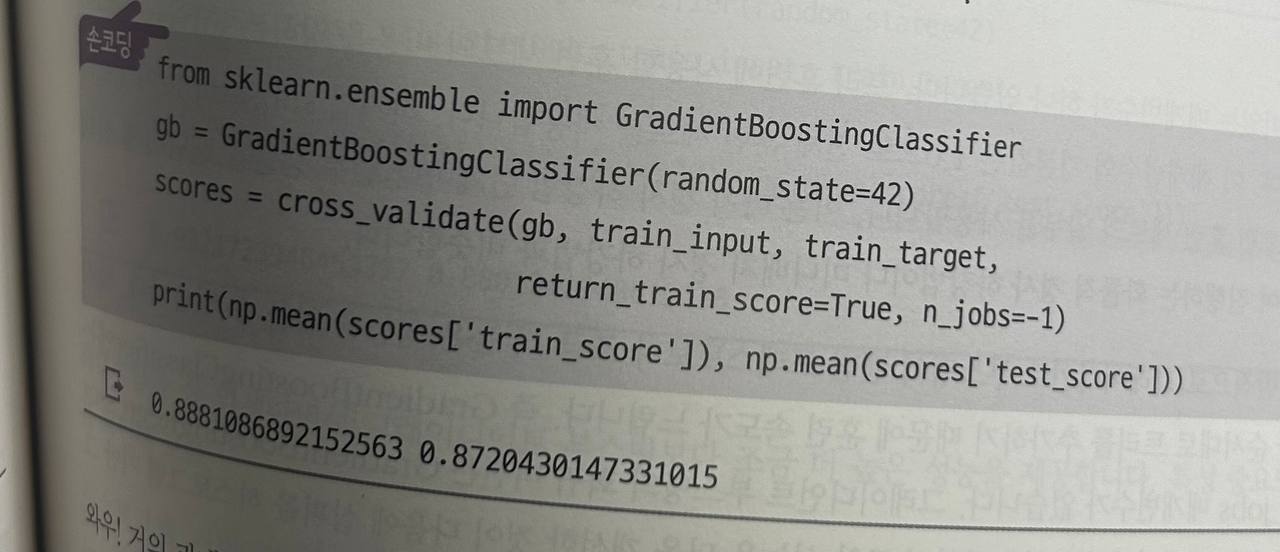
-
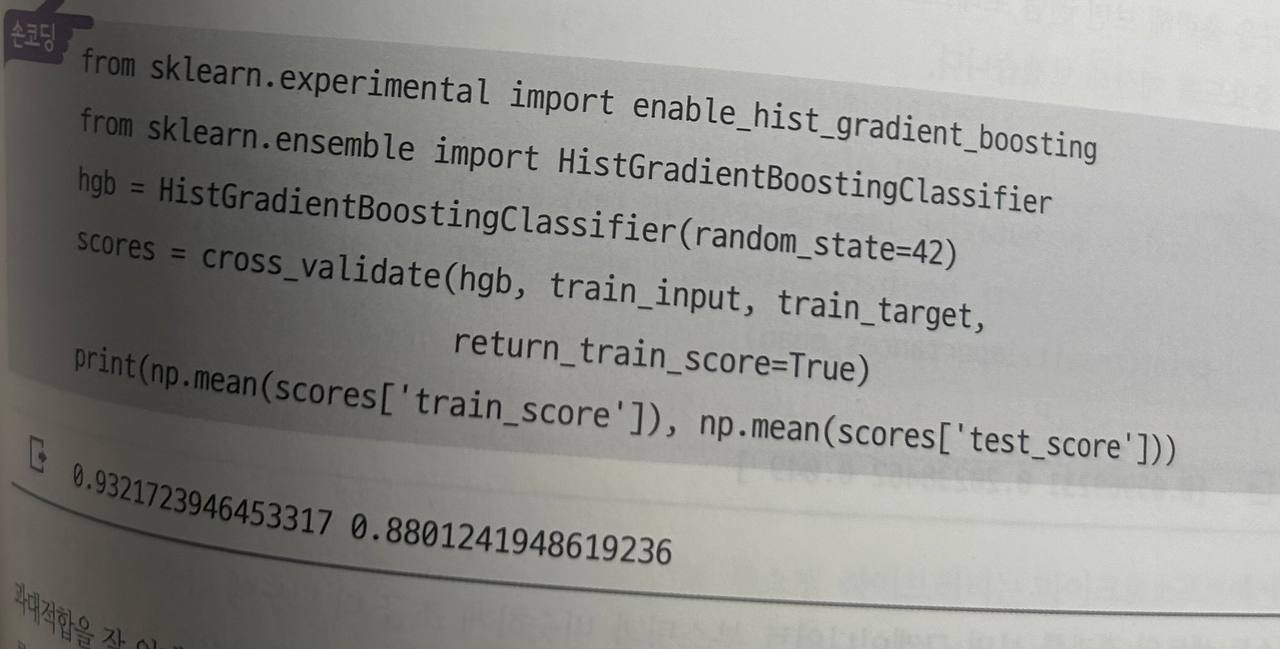
히스토그램 기반 그레이디언트 부스팅 : 그래디언트 부스팅의 속도를 개선한것
주요 클래스
-
RandomForestClassifier: 랜덤 포레스트 분류 모델.
n_estimators: 트리의 개수.bootstrap: 부트스트랩 샘플링 여부.
-
ExtraTreesClassifier: 엑스트라 트리 모델.
bootstrap: 부트스트랩 샘플링 여부.
-
GradientBoostingClassifier: 그라디언트 부스팅 분류 모델.
learning_rate: 학습률.n_estimators: 부스팅 단계를 수행할 트리 수.
-
HistGradientBoostingClassifier: 히스토그램 기반 그라디언트 부스팅 분류 모델.
예시 코드
from sklearn.ensemble import RandomForestClassifier
# 모델 훈련
rf = RandomForestClassifier(n_estimators=100)
rf.fit(X_train, y_train)
# 예측
y_pred = rf.predict(X_test)05-4 히스토그램 기반 그레이디언트 부스팅
-
HistGradientBoostingClassifier: 그라디언트 부스팅의 속도를 개선한 모델로, 큰 데이터셋에서 더 빠르게 동작함.
learning_rate: 학습률.max_iter: 트리 수.max_bins: 데이터 분할을 위한 구간 수.
예시 코드
from sklearn.ensemble import HistGradientBoostingClassifier
# 모델 훈련
hgb = HistGradientBoostingClassifier(max_iter=100)
hgb.fit(X_train, y_train)
# 예측
y_pred = hgb.predict(X_test)