SQL
JOIN
실습
지난 주의 연습문제 이어서
-- 문제 7. EMPLOYEES 테이블과 DEPARTMENTS 테이블의 부서번호를 조인하고 SA_MAN 사원만의 사원번호, 이름, 급여, 부서명, 근무지를 출력하세요. (Alias를 사용)
SELECT e.employee_id, e.first_name, e.salary, d.department_name, loc.city FROM employees e INNER JOIN departments d ON e.department_id = d.department_id INNER JOIN locations loc ON d.location_id = loc.location_id WHERE e.job_id = 'SA_MAN';
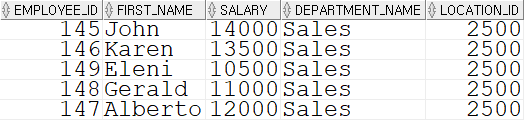
-- 문제 8. EMPLOYEES, JOBS 테이블을 조인 지정하고 job_title이 'Stock Manager', 'Stock Clerk' 인 직원 정보만 찾아 출력하세요.
SELECT e.employee_id, e.first_name, j.job_title FROM employees e INNER JOIN jobs j ON e.job_id = j.job_id WHERE job_title IN('Stock Manager', 'Stock Clerk');

OR 조건으로 묶어서 해결하려고 했었는데, IN() 함수를 사용하는 것이 더 좋다는 의견을 받아 변경.
-- 문제 9. DEPARTMENTS 테이블에서 직원이 없는 부서를 찾아 출력하세요. (LEFT OUTER JOIN 사용)
SELECT d.department_name FROM departments d LEFT OUTER JOIN employees e ON d.department_id = e.department_id WHERE e.employee_id IS NULL;

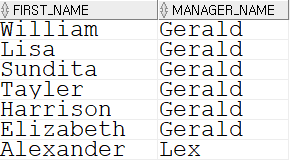
-- 문제 10. JOIN을 이용해서 사원의 이름과 그 사원의 매니저 이름을 출력하세요. 힌트) EMPLOYEES 테이블과 EMPLOYEES 테이블을 조인하세요.
SELECT e.first_name, es.first_name AS manager_name FROM employees e INNER JOIN employees es ON e.manager_id = es.employee_id;
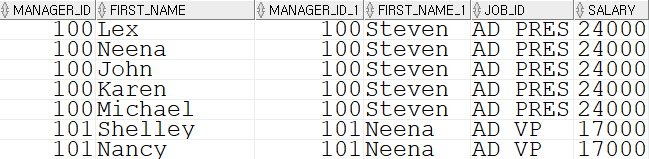
-- 문제 11. EMPLOYEES 테이블에서 LEFT JOIN 하여 관리자(매니저)와, 매니저의 이름, 매니저의 급여까지 출력하세요. 매니저 아이디가 없는 사람은 배제하고 급여는 역순으로 출력하세요.
SELECT e.manager_id, e.first_name, e.manager_id, es.first_name, es.job_id, es.salary FROM employees e LEFT JOIN employees es ON e.manager_id = es.employee_id WHERE e.manager_id IS NOT NULL ORDER BY e.salary DESC;
서브쿼리
A사원보다 급여를 많이 받는 사람은?
이라는 질의를 하려고 한다고 치자. 이 상황에서 우리는 두 개의 질의를 요한다. 하나는 A 사원의 급여 에 대한 것이고, 또 하나는 A 보다 더 많은 급여를 받는 사원 을 찾는 데 필요한 질의이다. 하나의 질의를 다른 질의의 내부에 두는 방식으로 두 개의 질의를 조합 하여 문제를 해결할 수 있다.
단일 행 서브쿼리
Nancy 라는 사원의 급여보다 더 많은 급여를 받는 사람을 찾기 위해 쿼리를 작성해보자.
-- 괄호부분이 최우선 해석되고 외부 부분이 그 다음으로 해석됨. SELECT * FROM employees WHERE salary > (SELECT salary FROM employees WHERE first_name = 'Nancy');

한번 더 연습을 위해, 아래와 같은 조건을 갖는 사람을 검색해보자.
-- employee_id가 103번인 사람과 job_id가 동일한 사람을 검색하는 문장 SELECT * FROM employees WHERE job_id = (SELECT job_id FROM employees WHERE employee_id = 103);

다중 행 연산자
다음 문장은 서브쿼리의 리턴 행이 여러 행이라 단일 행 연산자 사용이 불가하다.
이러한 경우 다중 행 연산자를 사용해야 한다.
job_id가IT_PROG인 사람들을 확인해 보려 하지만 안된다.SELECT * FROM employees WHERE job_id = (SELECT job_id FROM employees WHERE job_id = 'IT_PROG');
IN : 목록의 어떤 값과 같은지 확인
IN
job_id가IT_PROG인 사람들을 확인해보려 한다면 이렇게 해야 한다.SELECT * FROM employees WHERE job_id IN(SELECT job_id FROM employees WHERE job_id = 'IT_PROG');
-- first_name이 David인 사람 중 가장 작은 값보다 급여가 큰 사람을 조회 SELECT salary FROM employees WHERE first_name = 'David';
ANY: 값을 서브쿼리에 의해 리턴된 각각의 값과 비교합니다.
ANY
제시되는 값 중 어떤 값과 하나라도 일치하면 된다.-- first_name이 David인 사람 중 가장 작은 값보다 급여가 큰 사람을 조회. SELECT * FROM employees WHERE salary > ANY (SELECT salary FROM employees WHERE first_name = 'David');
ALL: 값을 서브쿼리에 의해 리턴된 값과 모두 비교해서 모두 만족해야 합니다.
ALL
SELECT * FROM employees WHERE salary > ALL (SELECT salary FROM employees WHERE first_name = 'David');
David라는 이름을 가진 사람들 모두보다 많은 봉급을 받는 사람을 조회하고자 하고 있다. (3000, 6000, 9000이라고 치면, 9000보다 많이 받는 사람이 조회되게 된다)
스칼라 서브쿼리
SELECT 구문에 서브쿼리가 오는 것.
LEFT OUTER JOIN과 유사한 결과를 갖는다.
LEFT OUTER JOIN 스타일의 서브쿼리
기존의 LEFT OUTER JOIN
SELECT e.first_name, d.department_name FROM employees e LEFT JOIN departments d ON e.department_id = d.department_id ORDER BY first_name ASC;
스칼라 서브쿼리
SELECT e.first_name, ( SELECT department_name FROM departments d WHERE d.department_id = e.department_id ) AS department_name FROM employees e ORDER BY first_name ASC;
결과는 완전히 같은 결과를 갖는다.
스칼라 서브쿼리가 조인보다 좋은 경우
: 함수처럼 한 레코드당 정확히 하나의 값 만을 리턴할 때조인이 스칼라 서브쿼리보다 좋은 경우
: 조회할 데이터가 대용량인 경우,
해당 데이터가 수정, 삭제 등이 빈번한 경우.
각 부서의 매니저의 이름 가져오기
LEFT JOIN
SELECT d.*, e.first_name FROM departments d LEFT JOIN employees e ON d.manager_id = e.employee_id ORDER BY d.manager_id ASC;
스칼라
SELECT d.*, ( SELECT first_name FROM employees e WHERE e.employee_id = d.manager_id ) AS manager_name FROM departments d ORDER BY d.manager_id ASC;
각 부서별 사원수 뽑기 (departments의 모든 컬럼, 사원 수를 별칭을 지어서 출력)
-- GROUP BY SELECT COUNT(*) FROM employees GROUP BY department_id; -- 서브쿼리 SELECT d.*, ( SELECT COUNT(*) FROM employees e WHERE e.department_id = d.department_id GROUP BY department_id ) AS 사원수 FROM departments d;
인라인 뷰
FROM 구문에 서브쿼리가 오는 것.
순번을 정해놓은 조회 자료를 범위를 지정해서 가지고 오는 경우 사용.
/* salary로 정렬을 진행하면서 ROWNUM을 붙이면 ROWNUM이 정렬이 되지 않는 문제가 발생한다. 이유 : ROWNUM이 먼저 붙고 정렬이 진행되기 때문. ORDER BY는 항상 마지막에 진행. 해결방법 : 정렬이 끝난 자료에 ROWNUM을 붙여서 조회하도록 하기. */ SELECT ROWNUM AS rn, employee_id, first_name, salary FROM employees ORDER BY salary DESC;
/* ROWNUM을 붙이고 나서 범위를 지정해서 조회하려고 하는데, 범위 지정도 불가능하고, 지목할 수 없는 문제가 발생했다. 이유 : WHERE절 부터 먼저 실행하고 나서 ROWNUM이 SELECT되므로. 해결방법 : ROWNUM까지 붙여 놓고 다시 한 번 자료를 SELECT 해서 범위를 지정. */ SELECT ROWNUM AS rn, tbl.* FROM ( SELECT employee_id, first_name, salary FROM employees ORDER BY salary DESC ) tbl WHERE rn <= 20 AND rn > 10;
/* 가장 안쪽 SELECT 절에서 필요한 테이블 형식 (인라인 뷰) 을 생성 바깥쪽 SELECT 절에서 ROWNUM을 붙여서 다시 조회 가장 바깥쪽 SELECT 절에서는 이미 붙어있는 ROWNUM의 범위를 지정해 조회 SQL의 실행 순서 FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY */ SELECT * FROM ( SELECT ROWNUM AS rn, tbl.* FROM ( SELECT employee_id, first_name, salary FROM employees ORDER BY salary DESC ) tbl ) WHERE rn <= 20 AND rn > 10;
연습문제 시작
문제 1. EMPLOYEES 테이블에서..
- 모든 사원들의 평균급여보다 높은 사원들의 데이터를 출력. (AVG(컬럼) 사용)
-- AVG(salary) 는 6461이다. SELECT * FROM employees WHERE salary > (SELECT AVG(salary) FROM employees) ORDER BY salary DESC;
- 모든 사원들의 평균급여보다 높은 사원들의 수를 출력
SELECT COUNT(*) FROM employees WHERE salary > (SELECT AVG(salary) FROM employees) ORDER BY salary DESC;
job_id가IT_PROG인 사원들의 평균급여보다 높은 사원들의 데이터를 출력.
SELECT * FROM employees WHERE salary > ( SELECT AVG(salary) FROM employees WHERE job_id = 'IT_PROG' ) ORDER BY salary DESC;
문제 2. DEPARTMENTS 테이블에서 manager_id가 100인 사람의 department_id와 EMPLOYEES 테이블에서 department_id가 일치하는 모든 사원의 정보를 검색하세요.
SELECT * FROM employees WHERE department_id = (SELECT department_id FROM departments WHERE manager_id = 100);
문제 3.
- EMPLOYEES 테이블에서 "Pat"의 manager_id보다 높은 manager_id를 갖는 모든 사원의 데이터를 출력하세요.
SELECT * FROM employees WHERE manager_id > ( SELECT manager_id FROM employees WHERE first_name = 'Pat' );
- EMPLOYEES 테이블에서 "James"(2명)들의 manager_id와 이를 갖는 모든 사원들의 데이터를 출력하세요.
-- 처음에 나는 여기 비교조건에 = ANY 를 줬었는데 IN이 맞는 듯. SELECT * FROM employees WHERE manager_id IN ( SELECT manager_id FROM employees WHERE first_name = 'James' );
문제 4. EMPLOYEES 테이블에서 first_name 기준으로 내림차순 정렬하고, 41~50번째 데이터의 행 번호, 이름을 출력하세요.
SELECT * FROM ( SELECT ROWNUM as rn, first_name FROM ( SELECT * FROM employees ORDER BY first_name DESC ) ) WHERE rn > 40 AND rn <= 50;
문제 5. EMPLOYEES 테이블에서 hire_date 기준으로 오름차순 정렬하고, 31~40번째 데이터의 행 번호, 사원id, 이름, 번호, 입사일을 출력하세요.
SELECT * FROM ( SELECT ROWNUM as rn, tbl.* FROM ( SELECT employee_id, first_name, phone_number, hire_date FROM employees ORDER BY hire_date ASC ) tbl ) WHERE rn > 30 AND rn <= 40;
문제 6.
employees 테이블 departments 테이블을 left 조인할 것.
조건 1) 직원아이디, 이름(성, 이름 붙여서), 부서아이디, 부서명만 출력한다.
조건 2) 직원아이디 기준 오름차순으로 정렬한다.SELECT e.employee_id, CONCAT(e.first_name, e.last_name), e.department_id, d.department_name FROM employees e LEFT JOIN departments d ON e.department_id = d.department_id ORDER BY e.employee_id ASC;
문제 7. 문제 6의 결과를 (스칼라 쿼리)로 동일하게 조회할 것
SELECT e.employee_id, CONCAT(e.first_name, e.last_name), e.department_id, ( SELECT department_name FROM departments d WHERE e.department_id = d.department_id ) AS department_name FROM employees e ORDER BY e.employee_id ASC;
문제 8.
departments 테이블 locations 테이블을 left 조인할 것.
조건 1) 부서아이디, 부서이름, 매니저 아이디, 로케이션 아이디, 스트릿 어드레스, 포스트 코드, 시티만 출력한다.
조건 2) 부서아이디 기준 오름차순 정렬SELECT d.department_id, d.department_name, d.manager_id, d.location_id, loc.street_address, loc.postal_code, loc.city FROM departments d LEFT JOIN locations loc ON d.location_id = loc.location_id ORDER BY d.department_id ASC;
문제 9. 문제 8의 결과를 (스칼라 쿼리)로 동일하게 조회하세요.
솔직히 여기는 진짜 어떻게 해야 하나 싶었는데 해결책을 너무 어렵게 생각했었음. 풀어주시고 나서 알았는데 그냥 서브쿼리를 많이 작성하면 그만임.
그런데 굳이 이렇게 할 바에 그냥 JOIN이 낫지 않나 싶고..
SELECT d.department_id, d.department_name, d.manager_id, d.location_id, ( SELECT loc.street_address FROM locations loc WHERE loc.location_id = d.location_id ) AS street_address, ( SELECT loc.postal_code FROM locations loc WHERE loc.location_id = d.location_id ) AS postal_code, ( SELECT loc.city FROM locations loc WHERE loc.location_id = d.location_id ) AS city FROM departments d LEFT JOIN locations loc ON d.location_id = loc.location_id ORDER BY d.department_id ASC;
문제 10.
locations 테이블 countries 테이블을 left 조인하세요.
조건 1) 로케이션 아이디, 주소, 시티, country_id, country_name 만 출력합니다.
조건 2) country_name 기준 오름차순 정렬SELECT loc.location_id, loc.street_address, loc.city, c.country_id, c.country_name FROM locations loc LEFT JOIN countries c ON loc.country_id = c.country_id ORDER BY c.country_name ASC;
문제 11. 문제 10의 결과를 (스칼라 쿼리)로 동일하게 조회하세요.
여기도 문제 9랑 비슷한 느낌이라 손 놨는데, 9 풀어주시고 어떻게 해야할지는 알았지만, 이쪽도 굳이 이래야 하나 싶은 생각만..
-- 조인 예시. SELECT loc.location_id, loc.street_address, loc.city, ( SELECT country_id FROM countries c WHERE loc.country_id = c.country_id ) country_id, ( SELECT country_name FROM countries c WHERE loc.country_id = c.country_id ) country_name FROM locations loc ORDER BY country_name ASC;
문제 12.
employees 테이블, departments 테이블을 left 조인, hire_date를 오름차순 기준으로 1~10번째 데이터만 출력.
조건 1) rownum을 적용하여 번호, 직원아이디, 이름, 전화번호, 입사일, 부서아이디, 부서이름을 출력.
조건 2) hire_date를 기준으로 오름차순 정렬. rownum이 틀어지면 안 됨.SELECT * FROM ( SELECT ROWNUM AS rn, a.* FROM ( SELECT e.phone_number, e.employee_id, e.first_name, e.hire_date, e.department_id, d.department_name FROM employees e LEFT JOIN departments d ON e.department_id = d.department_id ORDER BY hire_date ) a ) WHERE rn >= 1 AND rn <= 10;
문제 13.
employees 와 departments 테이블에서 job_id가 sa_man인 사원의 정보의 last_name, job_id, department_id, department_name을 출력
SELECT tbl.*, d.department_name FROM ( SELECT last_name, job_id, department_id FROM employees WHERE job_id = 'SA_MAN' ) tbl JOIN departments d ON tbl.department_id = d.department_id;
문제 14.
이 문제가 특히 빡셌다 싶은데, 왜냐하면 JOIN쪽에 서브쿼리를 작성하는걸 아마 위에서 안 배웠나? 그랬을 것.
애초에 응용을 해본다는 발상도 있긴 했을텐데 도저히 거기까진 생각이 안 닿았음
department 테이블에서 각 부서의 id, name, manager_id와 부서에 속한 인원수를 출력하세요.
조건 1) 인원수 기준 내림차순 출력
조건 2) 사람 없는 부서는 출력하지 말 것SELECT d.department_id, d.department_name, d.manager_id, a.total FROM departments d JOIN ( SELECT department_id, COUNT(*) AS total FROM employees GROUP BY department_id ) a ON d.department_id = a.department_id ORDER BY a.total DESC;
문제 15.
14번이 특히 빡셌다고는 하지만 뭐 여기라고 안 어렵진 않았다.
부서에 대한 정보 전부와, 주소, 우편번호, 부서별 평균 연봉을 구해서 출력하세요.
조건) 부서별 평균이 없으면 0으로 출력하세요.SELECT d.*, loc.street_address, loc.postal_code, NVL(a.result, 0) AS 부서별평균급여 FROM departments d JOIN locations loc ON d.location_id = loc.location_id LEFT JOIN ( SELECT department_id, TRUNC(AVG(salary)) AS result FROM employees GROUP BY department_id ) a ON d.department_id = a.department_id;
NVL() 써서 null 인 경우를 0 으로 치환해줬음.
