SQL
실습
연습문제
해당 연습문제는 주말 사이에 과제로 나온 문제였다.
문제 1.
사원 테이블에서 job_id별 사원 수를 구하세요.
사원 테이블에서 job_id별 월급의 평균을 구하세요. 그리고 월급의 평균 순으로 내림차순 정렬하세요.SELECT job_id, COUNT(*) AS 사원수, AVG(salary) AS 평균급여 FROM employees GROUP BY job_id ORDER BY AVG(salary) DESC;
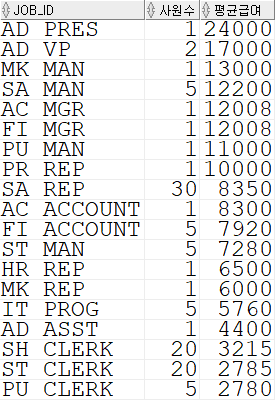
job_id 별 사원수와 월급의 평균을 구하고, ORDER BY 를 통해 월급의 평균 순으로 내림차순 정렬하였다.
문제 2.
사원 테이블에서 입사 년도 별 사원 수를 구하세요.SELECT TO_CHAR(hire_date, 'YY'), COUNT(*) FROM employees GROUP BY TO_CHAR(hire_date, 'YY');
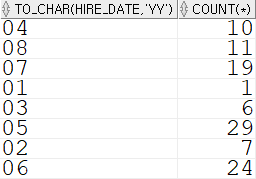
처음에는 어떻게 찾아내야 하나 고민했는데, TO_CHAR 함수를 간과하고 있었다.
TO_CHAR 함수를 통해서 DATE 형식의 데이터인 hire_date를 'YY' 형식의 문자열로 변환한 뒤, 해당 변환된 문자열을 그룹으로 묶어 COUNT 로 개수를 세어주면 되는 간단한 문제였다.
문제 3.
급여가 1000 이상인 사원들의 부서별 평균 급여를 출력하세요.
단, 부서 평균 급여가 2000 이상인 부서만 출력합니다.SELECT department_id, AVG(salary) FROM employees WHERE salary >= 1000 GROUP BY department_id HAVING AVG(salary) >= 2000;

HAVING 을 배워놓고도 깜빡해서, GROUP BY 까진 잘 작성해 놓고 살짝 헤맸었다. 어쨌든 전체 쿼리를 작성해놓고 살짝 의아해했던 게, 저 두 조건에 해당되지 않는 데이터가 없어서 조건을 거나 마나라는 점?
문제 4.
사원 테이블에서 commission_pct(커미션) 컬럼이 null 이 아닌 사람들의 department_id(부서별) salary(월급)의 평균, 합계, count를 구합니다.조건 1) 월급의 평균은 커미션을 적용시킨 월급입니다.
조건 2) 평균은 소수 2째 자리에서 절삭하세요.SELECT department_id, TRUNC(AVG(salary + salary * commission_pct), 2) AS 월급평균, COUNT(*) FROM employees WHERE commission_pct IS NOT NULL GROUP BY department_id;

일단 부서별로 묶어야하니까 부서를 앞에 놓고, 월급 평균은 보너스를 곱해서 계산한 다음, TRUNC 로 소수점 둘째 자리 밑은 절삭하였다.
그리고 COUNT 를 구하라고 했으니 구해주었다.
중요한 부분은 보너스가 없는 사람은 포함하면 안 되니까, WHERE 절에서 IS NOT NULL 조건을 주었다.
JOIN
두 개의 테이블을 서로 연관해서 조회하는 것을 조인이라 부른다.
이제 우리는 employees 테이블 뿐만이 아닌, departments 테이블에서도 정보를 가져다 쓸 것이다.
employees 테이블에서 department_id 를 보면 부서의 이름이 짧게 기록되어 있는데, 이 부서들의 풀 네임을 JOIN 을 통해서 departments 테이블에서 데이터를 가져올 수 있다.
중요 조인의 종류에는 INNER JOIN (내부 조인) 과 OUTER JOIN (외부 조인) (LEFT, RIGHT, FULL OTHER) 등이 있으나 아래에서 천천히 살펴보도록 하자.
ORACLE 문법과 ANSI 표준 문법
실습 1. ORACLE 문법과 ANSI 표준 문법
-- ORACLE 조인 문법 SELECT e.first_name, e.last_name, e.hire_date, e.salary, e.job_id, e.department_id, d.department_name FROM employees e, departments d WHERE e.department_id = d.department_id; -- ANSI 표준 조인 문법 SELECT e.first_name, e.last_name, e.hire_date, e.salary, e.job_id, e.department_id, d.department_name FROM employees e INNER JOIN departments d ON e.department_id = d.department_id;

두 테이블이 각각 가지고 있는 데이터에 대해서는 e. d. 등으로 표기하지 않아도 괜찮으나, department_id 와 같이 양쪽 테이블에 존재하는 데이터의 경우 어느 테이블의 데이터인지 명시적으로 작성해 주어야 한다.
INNER JOIN 의 경우, 예를 들자면 테이블 1에서 부서를 30개를 운영중이고, 테이블 2에서 실제로 운용되는 부서는 20개라고 쳤을 때, 여기서 상호 일치하는 부서가 20개 만을 가져오게 한다.
INNER JOIN (내부 조인)
두 테이블 모두에서 일치하는 값을 가진 행 만을 반환한다.
실습 1. 3개의 테이블을 이용한 INNER JOIN
-- 3개의 테이블을 이용한 내부 조인 (INNER JOIN) -- 내부 조인 : 두 테이블 모두에서 일치하는 값을 가진 행 만을 반환합니다. SELECT e.first_name, e.last_name, e.department_id, d.department_name, j.job_title FROM employees e, departments d, jobs j WHERE e.department_id = d.department_id AND e.job_id = j.job_id;

job_id 는 employees 테이블에서 조회해 볼 경우 아래와 같이 요약한 수준으로 데이터가 저장되어 있는데,
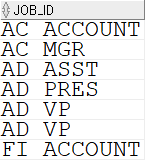
이를 jobs 테이블에서 employees 테이블의 job_id 와 일치하는 job_title 들을 가져옴으로써 각 job_id 의 풀 네임을 확인할 수 있게 되었다.
실습 2. 4개의 테이블을 대상으로 일반 조건을 걸어 INNER JOIN
SELECT e.first_name, e.last_name, e.department_id, d.department_name, e.job_id, j.job_title, loc.city FROM employees e, departments d, jobs j, locations loc WHERE e.department_id = d.department_id AND e.job_id = j.job_id -- 3, 4 AND d.location_id = loc.location_id -- 2 AND loc.state_province = 'California'; -- 해석순서 1 /* 1. loc 테이블의 province = 'California' 조건에 맞는 값을 대상으로 2. location_id 값과 같은 값을 갖는 데이터를 departments 에서 찾아 조인 3. 위의 결과와 동일한 department_id 를 가진 employees 테이블의 데이터를 찾아 조인 4. 위에 결과와 jobs 테이블을 비교하여 조인하고 최종 결과를 출력. */

state_province 가 'California' 인 사람만 조회하고 싶을 때는,INNER JOIN 을 하는 데에 필요한 조건도 WHERE 절에 같이 존재하므로 WHERE 절의 가장 마지막 조건에 적어 주어야 한다.
OUTER JOIN (외부 조인)
상호 테이블간에 일치되는 값으로 연결되는 내부 조인과는 다르게, 어느 한 테이블에 공통 값이 없더라도 해당 row들이 조회 결과에 모두 포함되는 조인을 말한다.
-- 오라클 조인 SELECT e.first_name, e.last_name, e.department_id, d.department_name FROM employees e, departments d, locations loc WHERE e.department_id = d.department_id(+) -- OUTER JOIN AND d.location_id = loc.location_id; -- INNER JOIN /* employees 테이블에는 존재하고, departments 테이블에는 존재하지 않아도 (+)가 붙지 않은 테이블을 기준으로 하여 departments 테이블이 조인에 참여하라는 의미를 부여하기 위해 기호를 붙인다. 외부 조인을 사용했더라도, 이후에 내부 조인을 사용하면 내부 조인을 우선적으로 인식한다. */
OUTER JOIN만 한 경우
INNER JOIN까지 한 경우


차이를 보면 알 수 있듯, INNER JOIN 을 하게 되면서 department_id 와 department_id 가 NULL 인 컬럼이 잘려나갔다.
테이블 분리 시의 장점
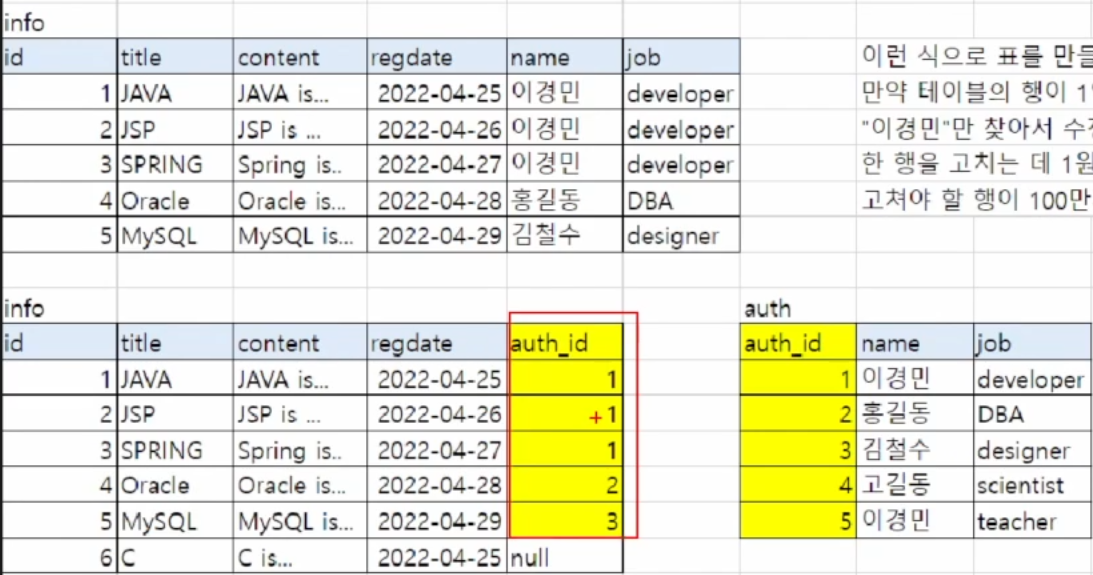
상단의 info 테이블에 모든 정보를 유지시키면서 서비스를 개발하면 나중에 특정 사람에 대한 정보를 수정해야 할 때, (예. 여기서는 '이경민' 강사님) 해당하는 사람의 데이터가 든 모든 레코드를 수정해야 하는데, 그 과정에서 시간과 비용이 매우 크게 발생할 수 있다.
따라서 하단처럼 auth_id 를 갖는 info 테이블과 auth 라는 테이블을 나누어 정보를 관리하게 되면, 여러 장점을 갖게 된다.
- 특정 인물의 job을 단순 하나만 수정하더라도 info 테이블의 모든 행에서 바뀐 작업을 참조 가능
- info에 글을 한 번도 쓴 적이 없더라도 auth 테이블에는 존재 가능
- 동명이인 등록이 가능 (이름이 같아도 다른 job을 얼마든지 지정 가능, auth_id는 중복되지 않으므로)
조인해보기 실습
실습
-- 이너(내부) 조인 (ANSI)
SELECT * FROM info i INNER JOIN auth a ON i.auth_id = a.auth_id;-- 오라클 문법 (자주 사용은 안 할 것)
SELECT * FROM info, auth WHERE info.auth_id = auth.auth_id;
-- auth_id 는 두 테이블 다 가지고 있는 컬럼이므로
-- 어떤 테이블의 것으로 할 지 명시적으로 적어주어야 한다.SELECT info.auth_id, title, content, name FROM info INNER JOIN auth ON info.auth_id = auth.auth_id;
-- 필요한 데이터만을 조회하고자 하는 경우
-- WHERE 구문을 통해 일반 조건만을 걸어주면 된다.SELECT i.auth_id, i.title, i.content, a.name FROM info i INNER JOIN auth a ON i.auth_id = a.auth_id WHERE a.name = '홍길자';
-- OUTER (외부) 조인
-- 기준이 왼쪽 테이블(info)에 맞춰서 조인됨.
``sql
SELECT *
FROM info i LEFT OUTER JOIN auth a
ON i.auth_id = a.auth_id;
-- 오라클 문법
SELECT * FROM info i, auth a WHERE i.auth_id = a.auth_id(+);
-- 좌측 테이블과 우측 테이블 데이터를 모두 읽어 중복된 데이터는 삭제되는 외부 조인.
SELECT * FROM info i FULL OUTER JOIN auth a ON i.auth_id = a.auth_id;
-- CROSS JOIN은 JOIN조건을 설정하지 않기 때문에
-- 모든 컬럼에 대해 JOIN을 진행합니다.
-- 실제로는 거의 사용하지 않습니다.SELECT * FROM info CROSS JOIN auth ORDER BY id ASC;
-- 여러 개 테이블 조인 -> 키 값만 찾아서 구문을 연결하여 사용하면 됨.
SELECT * FROM employees e LEFT OUTER JOIN departments d ON e.department_id = d.department_id LEFT OUTER JOIN locations loc ON d.department_id = loc.location_id;
/*
테이블 별칭 a, i를 이용하여 LEFT OUTER JOIN을 사용.
info, auth 테이블 사용.
job 컬럼이 scientist 인 사람의 id, title, content, job을 출력
*/
-- scientist는 auth에는 있지만 info에는 없어서 안 나옴SELECT i.id, i.title, i.content, a.job FROM info i LEFT OUTER JOIN auth a ON i.auth_id = a.auth_id WHERE a.job = 'scientist';-- auth를 기준으로 join하면 scientist가 나오기는 함
SELECT i.id, i.title, i.content, a.job FROM auth a LEFT OUTER JOIN info i ON i.auth_id = a.auth_id WHERE a.job = 'scientist';
연습 문제
-- 문제 1.
-- 이너조인SELECT * FROM employees e INNER JOIN departments d ON e.department_id = d.department_id; -- LEFT OUTER SELECT * FROM employees e LEFT OUTER JOIN departments d ON e.department_id = d.department_id; -- RIGHT OUTER SELECT * FROM employees e RIGHT OUTER JOIN departments d ON e.department_id = d.department_id; -- FULL OUTER SELECT * FROM employees e FULL OUTER JOIN departments d ON e.department_id = d.department_id;
-- 문제 2.
SELECT e.first_name || ' ' || e.last_name AS name, d.department_name FROM employees e INNER JOIN departments d ON e.department_id = d.department_id WHERE e.employee_id = 200;
-- 문제 3.
SELECT e.first_name, j.job_title FROM employees e INNER JOIN jobs j ON e.job_id = j.job_id ORDER BY e.first_name ASC;
-- 문제 4.
SELECT * FROM jobs j LEFT OUTER JOIN job_history jh ON j.job_id = jh.job_id;
-- 문제 5.
SELECT CONCAT(e.first_name, e.last_name), d.department_name FROM employees e INNER JOIN departments d ON e.department_id = d.department_id WHERE CONCAT(e.first_name, e.last_name) = 'StevenKing';
-- 문제 6.
SELECT * FROM employees e CROSS JOIN departments d;
