SQL
문자열 함수
실습
LTRIM(), RTRIM(), TRIM() 공백 제거
LTRIM
SELECT LTRIM('javascript_java', 'java') FROM dual;

문자를 제거하되, 좌측부터 제거.
RTRIM
SELECT RTRIM('javascript_java', 'java') FROM dual;

문자를 제거하되, 우측부터 제거.
TRIM
SELECT TRIM(' JAVA ') FROM dual;
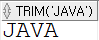
공백을 제거.
기존 문자열을 대체하는 REPLACE()
REPLACE
SELECT REPLACE('My Dream is a president', 'president', 'doctor') FROM dual;
SELECT REPLACE(REPLACE('My Dream is a president', 'president', 'doctor'), ' ', '') FROM dual;
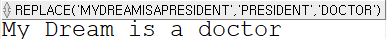

첫 번째 매개변수는 전체 문자열, 두 번째는 바꾸려는 기존 문자열, 세 번째는 바꿀 문자열의 내용을 입력하면 된다.
아래의 결과같은 경우, 안쪽의 REPLACE 함수에서 대치된 문장이 외부 REPLACE 함수를 만나면서 공백을 전부 제거당해 띄어쓰기가 없는 문장이 완성되었다.
연습문제
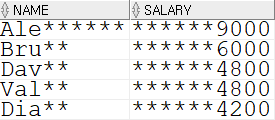
문제 1. EMPLOYEES 테이블에서 job_id가 IT_PROG인 사원의 이름과 급여를 출력
조건 1) 비교하기 위한 값은 소문자
조건 2) 이름은 앞 3문자까지 출력 후 나머지는 *로 출력, 별칭은 name
조건 3) 급여는 전체 10자리로 출력하되 나머지 자리는 *로 출력, 별칭은 salarySELECT rpad(substr(first_name, 1, 3), length(first_name), '*') AS name, lpad(salary, 10, '*') AS salary FROM employees WHERE lower(job_id) = 'it_prog'
연습문제
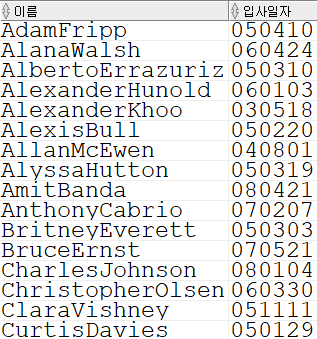
-- 문제 1. EMPLOYEES 테이블에서 이름, 입사일자 컬럼으로 변경해서 이름순으로 오름차순 출력
SELECT concat(first_name, last_name) AS 이름, replace(hire_date, '/', '') AS 입사일자 FROM employees ORDER BY 이름 ASC;
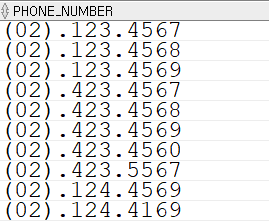
-- 문제 2. EMPLOYEES 테이블에서 phone_number 컬럼은 ###.###.#### 형태로 저장되어 있음
-- 여기서 처음 세 자리 숫자 대신 서울 지역번호(02)를 붙여 전화번호 출력하도록 쿼리 작성.
-- 내 해결 방법 SELECT '(02)' || substr(phone_number, 4) FROM employees; -- 강사님의 솔루션 SELECT concat('(02)', substr(phone_number, 4, length(phone_number))) AS phone_number FROM employees;
숫자 함수
실습
ROUND (반올림)
ROUND
SELECT ROUND(3.1415, 2), ROUND(45.923, 0), ROUND(45.923, -1) FROM dual;

두 번째 매개변수의 경우 소수점 n째 자리부터 반올림 할 것인지 결정하는 부분이다.
TRUNC (절사)
TRUNC
SELECT TRUNC(3.1415, 3), TRUNC(45.923, 0), TRUNC(45.923, -1) FROM dual;
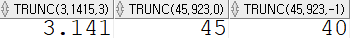
두 번째 매개 변수로 들어온 자리 아래의 부분은 전부 절사한다.
ABS (절댓값)
ABS
SELECT ABS(-34) FROM dual;

매개 변수로 들어온 값을 절댓값 처리한다.
CEIL (올림), FLOOR (내림)
CEIL, FLOOR
SELECT CEIL(3.14), FLOOR(3.14) FROM dual;

MOD (나머지)
MOD
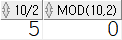
SELECT 10 / 2, mod(10, 2) FROM dual;
날짜 함수
실습
SYSDATE, SYSTIMESTAMP
SYSDATE
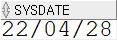
SELECT sysdate FROM dual;
SYSTIMESTAMP
SELECT systimestamp FROM dual;

자세한 시간과 타임존까지 표시된다.
날짜 연산
SELECT first_name, sysdate - hire_date FROM employees;

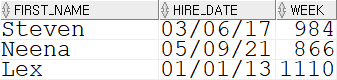
SELECT first_name, hire_date, TRUNC((sysdate - hire_date) / 7, 0) AS WEEK FROM employees;
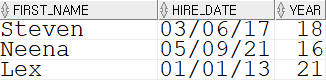
SELECT first_name, hire_date, TRUNC((sysdate - hire_date) / 365, 0) AS YEAR FROM employees;
날짜 반올림
SELECT ROUND(sysdate) FROM dual;
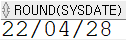
정오가 넘으면 다음날로, 넘지 않았으면 오늘로 계산
SELECT ROUND(sysdate, 'year') FROM dual;
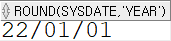
1년의 중간이 지났으면 내년 1월 1일로, 아닌 경우 올해 1월 1일로 계산
SELECT ROUND(sysdate, 'month') FROM dual;
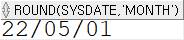
한 달의 중간이 지났으면 다음 달의 1일로, 지나지 않았으면 이번 달의 1일로 계산
SELECT ROUND(sysdate, 'day') FROM dual;

이건 조금 다르긴 한데, 올림 처리되면 다음 주의 일요일, 내림 처리되면 그 주의 일요일을 표시해준다.
날짜 절사
SELECT TRUNC(sysdate) FROM dual;
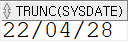
SELECT TRUNC(sysdate, 'year') FROM dual;

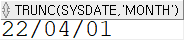
SELECT TRUNC(sysdate, 'month') FROM dual;
SELECT TRUNC(sysdate, 'day') FROM dual;
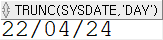
위의 반올림 파트를 보면 알 수 있듯, day단위로 계산되는 경우 전 주의 일요일, 달의 경우 그 달의 1일, 년의 경우 그 년도의 1월 1일로 계산되는 것을 알 수 있다.
날짜의 형 변환
TO_CHAR, 문자열 형태로 변경
SELECT TO_CHAR(sysdate) FROM dual;
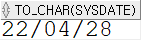
sysdate 의 경우 DATE 자료형이지만, TO_CHAR() 함수를 통해 문자열 형태로 변환시켰다.
SELECT TO_CHAR(sysdate, 'YYYY-MM-DD HH:MI:SS') FROM dual;

sysdate 의 경우 표시되는 부분은 날짜 뿐이지만 내부적으로는 세부 시간 데이터까지 가지고 있기 때문에, TO_CHAR() 함수를 통해서 원하는 표시 형식으로 형 변환을 하면 내부에 있는 세부 시간까지 뽑아낼 수 있다.
사용하고 싶은 문자를 ""로 묶어 전달
SELECT first_name, TO_CHAR(hire_date, 'YYYY"년" MM"월" DD"일"') FROM employees;

숫자를 문자로 (TO_CHAR)
SELECT TO_CHAR(20000, '99999') FROM dual;
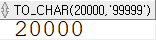
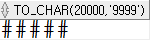
SELECT TO_CHAR(20000, '9999') FROM dual;
SELECT TO_CHAR(20000.21, '99999.9') FROM dual;
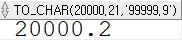
SELECT TO_CHAR(20000, '99,999') FROM dual;
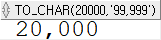
형식을 지정해서 원하는 형식으로 표현하거나, 절사하거나 할 수 있고, 표현하려는 길이에 비해서 원래 숫자의 길이가 더 긴 경우에는 표시할 수 없다는 의미로 # 등으로 채워져 출력된다.
SELECT TO_CHAR(salary, 'L99,999') AS salary FROM employees;
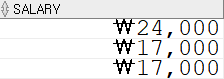
L을 사용하면 시스템상의 화폐 단위를 불러와 적용한다고 한다.
문자를 숫자로
묵시적 형 변환
SELECT '2000' + 2000 FROM dual; -- 묵시적 형 변환
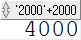
명시적 형 변환
SELECT TO_NUMBER('2000') + 2000 FROM dual; -- 명시적 형 변환
문자와 숫자가 섞인 경우
SELECT TO_NUMBER('$3,300', '$9,999') + 2000 FROM dual;

뒤의 '$9,999' 부분은 앞에 입력된 $3,300 부분이 어떤 형식으로 이루어져 있는지 함수에 전달하여 문자열을 숫자로 변환하는데 도움을 주기 위해 있는 부분이다.
문자를 날짜로 변환 (TO_DATE)
TO_DATE를 통해 문자를 날짜로 변환하기
SELECT TO_DATE('2021-11-25') from dual;문자를 날짜로 바꾸고, 날짜끼리 연산하기
SELECT sysdate - TO_DATE('2022-03-27') FROM dual;특정 형식의 형태로 날짜 출력하기
SELECT TO_DATE('2020/12/25', 'YY-MM-DD') FROM dual;주어진 날짜 길이를 전부 변환해야 하는 경우
(HH:MI:SS를 입력하지 않는 경우 실행 불가)SELECT TO_DATE('2021-03-31 12:23:34', 'YYYY-MM-DD HH:MI:SS') FROM dual;YYYY년 MM월 DD일 형식의 형태로 출력하기
SELECT TO_CHAR( TO_DATE('20050102', 'YYYY/MM/DD'), 'YYYY"년" MM"월" DD"일"') AS dateinfo FROM dual;
NULL 제거 함수 NVL(), NVL2()
NVL(컬럼, 대체할 값)
SELECT first_name, NVL(commission_pct, 0) AS comm_pct FROM employees;
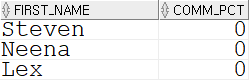
NVL() 함수를 통해 COMM_PCT 컬럼이 NULL 인 사원의 경우 0으로 대체하여 출력하도록 하고 있다.
NVL2(컬럼, null이 아닐 경우 값, null일 경우 값)
SELECT NVL2(null, '널아님', '널임') FROM dual;

널 값에 대한 대체가 잘 처리되고 있는지 테스트.
DECODE() 조건 함수
DECODE(컬럼 혹은 표현식, 항목1, 결과1, 항목2, 결과2 ... default)SELECT DECODE('A', 'A', 'A입니다', 'B', 'B입니다', 'C', 'C입니다', '해당없음') FROM dual;

테스트를 위한 쿼리. 'A' 라는 내용의 컬럼이 주어졌고 조건에 따라서 결과문을 출력하고 있다.
job_id가 특정 id 와 일치할 때 월급에 보너스를 주도록 하는 쿼리SELECT job_id, salary, DECODE( job_id, 'IT_PROG', salary * 1.1, 'FI_MGR', salary * 1.2, 'AD_VP', salary * 1.3, salary ) AS result FROM employees;
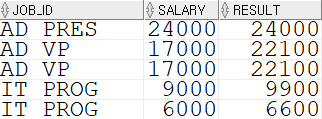
CASE ~ WHEN ~ THEN ~ ELSE ~ END 조건 함수
CASE ~ END
SELECT first_name, job_id, salary, (CASE job_id WHEN 'IT_PROG' THEN salary * 1.1 WHEN 'FI_MGR' THEN salary * 1.2 WHEN 'AD_VP' THEN salary * 1.3 ELSE salary END) AS result FROM employees;
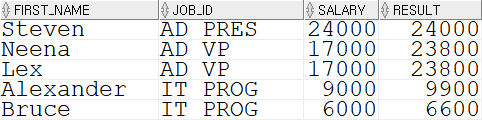
아까의 DECODE() 함수를 통해 실행한 쿼리문과 같은 결과를 같게 하는 쿼리문을 작성해 보았다.
연습문제
문제 1.
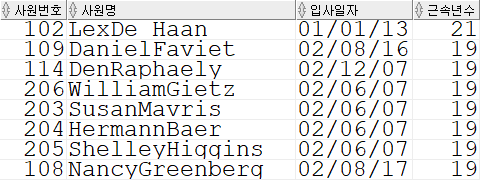
현재 일자를 기준으로 EMPLOYEE 테이블의 입사일자(hire_date)를 참조해서
근속년수가 10년 이상인 사원을 다음과 같은 형태의 결과를 출력하도록 쿼리를 작성해 보세요.
사원번호/ 사원명 (이름, 성 붙여서)/ 입사일자 / 근속년수
근속년수가 높은 사원 순서대로 결과가 나오도록 합니다.SELECT employee_id AS 사원번호, CONCAT(first_name, last_name) AS 사원명, hire_date AS 입사일자, TRUNC((sysdate - hire_date) / 365) AS 근속년수 FROM employees WHERE (sysdate - hire_date) / 365 >= 10 ORDER BY 근속년수 DESC;
문제 2.
EMPLOYEE 테이블의 department_id 컬럼을 확인하여 first_name, manager_id, 직급을 출력
100인 경우 사원, 120은 주임, 121은 대리, 122는 과장, 나머지는 임원으로 출력
추가 조건) department_id가 50인 사람들을 대상으로만 조회.SELECT first_name AS 이름, manager_id, (CASE manager_id WHEN 100 THEN '사원' WHEN 120 THEN '주임' WHEN 121 THEN '대리' WHEN 122 THEN '과장' ELSE '임원' END) AS 직급 FROM employees WHERE department_id = 50;

코드를 짧게 치려면 DECODE가 훨씬 더 편하긴 하다.
집합 연산자
집합 연산자는 연산 시 위, 아래 column의 개수가 정확히 일치해야만 가능하다.
실습
UNION(합집합, 중복X)SELECT employee_id, first_name FROM employees WHERE hire_date LIKE '%04' UNION SELECT employee_id, first_name FROM employees WHERE department_id = 20;
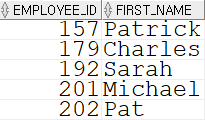
UNION 을 빼고 실행할 경우 157~192번 사원이 상단 쿼리문에 의해서 출력되고, 201~202번 사원이 아래 쿼리문에 의해 출력된다.
여기서는 UNION 을 이용해 두 결과를 합집합으로 출력하였으므로, 상단의 스크린샷과 같은 결과를 확인할 수 있다.
UNION ALL(합집합 중복 O)SELECT employee_id, first_name FROM employees WHERE hire_date LIKE '04%' UNION ALL SELECT employee_id, first_name FROM employees WHERE department_id = 20;
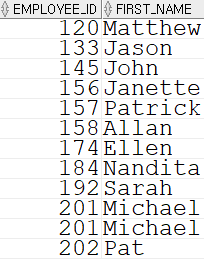
UNION ALL 의 경우 201번 사원인 Michael이 두 번 출력되는 것을 확인할 수 있다.
INTERSECT(교집합)SELECT employee_id, first_name FROM employees WHERE hire_date LIKE '04%' INTERSECT SELECT employee_id, first_name FROM employees WHERE department_id = 20;
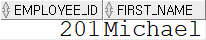
교집합의 경우 상단의 쿼리와 똑같은 쿼리문을 갖으나, INTERSECT 명령어로 인해 서로 공통된 부분인 201번 Michael 사원만을 출력하게 된다.
MINUS(차집합)SELECT employee_id, first_name FROM employees WHERE hire_date LIKE '04%' MINUS SELECT employee_id, first_name FROM employees WHERE department_id = 20;
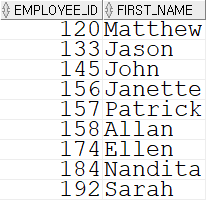
차집합의 경우 전자의 출력결과에서 후자의 출력결과를 뺀 결과를 갖는다.
그룹 함수 (GROUP BY, HAVING)
실습
그룹 함수 AVG, MAX, MIN, SUM, COUNT
AVG,MAX,MIN,SUM,COUNTSELECT AVG(salary), MAX(salary), MIN(salary), SUM(salary), COUNT(salary) FROM employees;
각각 평균, 최대값, 최소값, 모든 데이터를 더한 값, 총 행 데이터의 개수를 계산하는 함수들이다.
GROUP BY 부서별로 그룹화, 그룹 함수의 사용
GROUP BY()SELECT department_id, AVG(salary) FROM employees GROUP BY department_id;

department_id 를 그룹화해서 각 동일 department_id 를 가진 데이터끼리의 salary를 AVG() 하여 계산한다.
만약 GROUP BY 를 작성하지 않았으면, 쿼리문 실행 자체가 안 되게 된다. 또한, GROUP BY 사용 시 GROUP 절에 묶이지 않으면 다른 컬럼을 조회할 수 없다.
GROUP BY()다중 컬럼 그룹화SELECT job_id, department_id, AVG(salary) FROM employees GROUP BY department_id, job_id ORDER BY department_id;
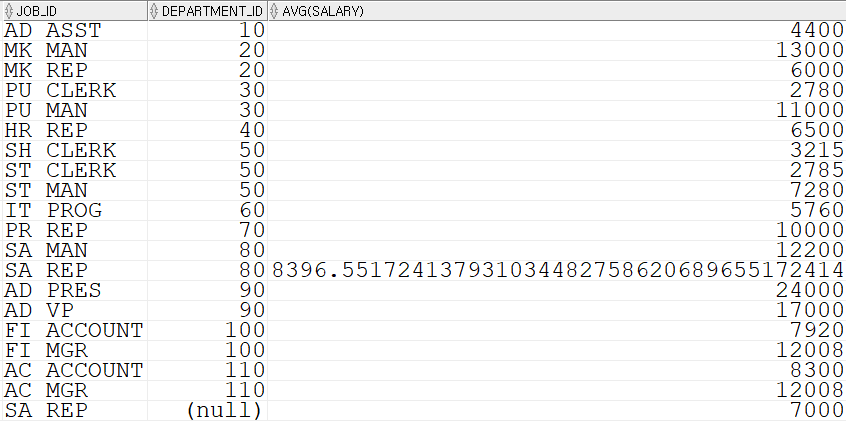
여러 개의 컬럼을 지정할 수도 있다.
HAVING 조건 지정하여 그룹화하기
특정 부서의 임급 합계가 100,000을 넘는 부서를 조회하고자 한다.
조건 지정하여 그룹화하기
-- 이렇게 작성하면 될 것이라고 생각하지만 되지 않는다. SELECT department_id, SUM(salary) FROM employees WHERE SUM(salary) > 100000 GROUP BY department_id; -- 이때 이렇게 작성해야 한다. SELECT department_id, SUM(salary) FROM employees GROUP BY department_id HAVING SUM(salary) > 100000;
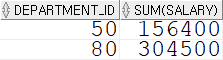
부서 아이디가 50 이상인 것들을 그룹화 시키고, 그룹 월급 평균 중 5000 이상만 조회
SELECT department_id, AVG(salary) FROM employees WHERE department_id >= 50 GROUP BY department_id HAVING AVG(salary) > 5000 ORDER BY department_id ASC;

실행 순서를 작 숙지해서 작성할 것.
