DML (SQL)
테이블 구조 확인
-- DESCRIBE DESC departments;

- 이름 : 컬럼명
- 널? : 데이터가 없어도 되게 허락할지 말지
- 유형 : NUMBER(n) → n자리까지의 숫자 받기
VARCHAR2(30) → 가변 길이 문자열로 30바이트까지 받겠다는 뜻
INSERT
INSERT의 첫 번째 방법 (모든 컬럼 데이터를 한번에 지정)
INSERT INTO departments VALUES (280, '개발자', null, 1700); SELECT * FROM departments; ROLLBACK; -- 실행 시점을 다시 뒤로 되돌리는 키워드
INSERT의 두 번째 방법 (직접 컬럼을 지정하고 저장하는 방식)
-- manager_id 부분은 NULL이어도 되므로 일단 잘 삽입됨. INSERT INTO departments(department_id, department_name, location_id) VALUES (280, '개발자', 1700);
INSERT 연습
-- 강사님의 제시된 레코드를 보고 어떻게 INSERT를 하면 되는지 작성 INSERT INTO departments(department_id, department_name, manager_id, location_id) VALUES (290, '디자이너', null, 1700); INSERT INTO departments(department_id, department_name, manager_id, location_id) VALUES (300, 'DB관리자', null, 1800); INSERT INTO departments(department_id, department_name, manager_id, location_id) VALUES (310, '데이터분석가', null, 1800); INSERT INTO departments(department_id, department_name, manager_id, location_id) VALUES (320, '퍼블리셔', 200, 1800); INSERT INTO departments(department_id, department_name, manager_id, location_id) VALUES (330, '서버관리자', 200, 1800); SELECT * FROM departments; ROLLBACK;
-- 서브쿼리로 조회된 내용을 기반으로 managers 테이블을 생성 -- WHERE절에 true 조건을 주변 테이블 내용을 싹 복사, -- false 조건을 주면 내용을 복사해 오지 않는다. CREATE TABLE managers AS (SELECT employee_id, first_name, job_id, hire_date FROM employees WHERE 1 = 2); SELECT * FROM managers; -- 위의 CREATE TABLE 쿼리문에서 WHERE절을 FALSE로 주었을 때, -- 아래의 서브쿼리문을 이용해서 내용을 채울수도 있다. INSERT INTO managers (SELECT employee_id, first_name, job_id, hire_date FROM employees);
UPDATE
-- CTAS(create table as ...)를 사용하면 제약 조건은 NOT NULL 말고는 복사되지 않는다. -- 제약조건은 업무규칙을 지키는 데이터만 저장하고, 그렇지 않은 것들이 -- DB에 저장되는 것을 방지하는 목적으로 사용합니다. CREATE TABLE emps AS (SELECT * FROM employees); SELECT * FROM emps; -- UPDATE를 진행할 때는 누구를 수정할 지 지목해야 한다. -- 그렇지 않은 경우 수정 대상이 테이블 전체로 지목된다. -- 이렇게 하는 경우 전 직원의 급여가 30000이 되어버린다. UPDATE emps SET salary = 30000;
UPDATE 대상을 지목하여 수정
UPDATE emps SET salary = 30000 WHERE employee_id = 100; UPDATE emps SET salary = salary + salary * 0.1 WHERE employee_id = 100;
한 번에 여러 개의 값을 수정
-- 한 번에 여러 개의 값을 수정할 때는 ',' 콤마로 구분하여 적는다. UPDATE emps SET phone_number = '515.123.4566', manager_id = 102 WHERE employee_id = 100;
UPDATE 서브쿼리
-- UPDATE (서브쿼리) -- 100번 사원의 job_id, salary, manager_id를 얻어와서 -- 101번 사원의 동일 컬럼의 내용을 UPDATE 해주고 있다. UPDATE emps SET (job_id, salary, manager_id) = (SELECT job_id, salary, manager_id FROM emps WHERE employee_id = 100) WHERE employee_id = 101;
DELETE
-- 103번 사원의 데이터 삭제 DELETE FROM emps WHERE employee_id = 103; -- 103번 사원을 콕 찝어서 조회해보면 없는 것을 알 수 있다. SELECT * FROM emps WHERE employee_id = 103;
DELETE 서브쿼리
-- 사본 테이블 생성 CREATE TABLE depts AS (SELECT * FROM departments); -- DELETE(서브쿼리) -- depts 테이블에서 부서번호가 100번인 부서를 찾아서 -- 해당 부서에 있는 직원을 emps 테이블에서 전부 삭제 DELETE FROM emps WHERE department_id = (SELECT department_id FROM depts WHERE department_id = 100); -- 부서명이 IT인 데이터를 찾아 department_id를 넘겨주고 -- 그에 해당하는 직원을 emps 테이블에서 삭제. DELETE FROM emps WHERE department_id = (SELECT department_id FROM depts WHERE department_name = 'IT');
MERGE
MERGE : 테이블 병합
UPDATE와 INSERT 한방에 처리. 한 테이블에 해당하는 데이터가 있다면 UPDATE를, 없으면 INSERT로 처리. 만약 MERGE가 없었다면 해당 데이터의 존재 유무를 일일히 확인하고 if문을 사용해서 데이터가 있다면 UPDATE, 없으면 else문을 사용해서 INSERT를 하라고 일일히 얘기해야 하지만, MERGE를 통해 쉽게 처리 가능.-- 내용 복사하지 않고 형식만 복사 CREATE TABLE emps_it AS (SELECT * FROM employees WHERE 1 = 2); SELECT * FROM emps_it; -- 특정 데이터 삽입 INSERT INTO emps_it (employee_id, first_name, last_name, email, hire_date, job_id) VALUES(105, '데이비드', '김', 'DAVIDKIM', '22/04/27', 'IT_PROG'); -- 조회 SELECT * FROM employees WHERE job_id = 'IT_PROG';
MERGE INTO emps_it a -- (머지를 할 타겟 테이블) USING -- 병합시킬 데이터 (SELECT * FROM employees WHERE job_id = 'IT_PROG') b -- 조인 구문 ON -- 병합시킬 데이터의 연결 조건 (a.employee_id = b.employee_id) -- 조인 조건 WHEN MATCHED THEN -- 조건에 일치할 경우 타겟 테이블에 이렇게 실행해라. UPDATE SET a.phone_number = b.phone_number, a.hire_date = b.hire_date, a.salary = b.salary, a.commission_pct = b.commission_pct, a.manager_id = b.manager_id, a.department_id = b.department_id /* DELETE 를 추가해보고자 한다. 하지만 단독으로 사용은 불가능하다. UPDATE 이후에 DELETE 작성이 가능하며, UPDATE 된 대상을 DELETE 하도록 설계되어 있기 때문에, 삭제할 대상 컬럼들을 동일한 값으로 일단 UPDATE 를 진행하고, DELETE 의 WHERE 절에 아까 지정한 동일한 값을 지정해서 삭제한다. */ DELETE WHERE a.employee_id = b.employee_id WHEN NOT MATCHED THEN -- 조건에 일치하지 않는 경우 타겟 테이블에 실행 INSERT /*속성(컬럼)*/ VALUES (b.employee_id, b.first_name, b.last_name, b.email, b.phone_number, b.hire_date, b.job_id, b.salary, b.commission_pct, b.manager_id, b.department_id);
-- 위의 아주 긴 쿼리문을 실행하고 나면 알 수 있는 부분이, -- employee_id가 105인 사람은 emps_it와 employee에 둘 다 존재하므로, -- MATCHED 조건에 들어가게 되어서 기존의 '데이비드 킴' 의 일부 데이터는 보존되면서 -- 나머지 데이터는 UPDATE됨과 동시에 emps_it에 없는 데이터는 INSERT 되었다. SELECT * FROM emps_it;
-- 더미데이터 삽입 INSERT INTO emps_it (employee_id, first_name, last_name, email, hire_date, job_id) VALUES(102, '렉스', '박', 'LEXPARK', '01/04/06', 'AD_VP'); INSERT INTO emps_it (employee_id, first_name, last_name, email, hire_date, job_id) VALUES(101, '니나', '최', 'NINA', '20/04/06', 'AD_VP'); INSERT INTO emps_it (employee_id, first_name, last_name, email, hire_date, job_id) VALUES(103, '흥민', '손', 'HMSON', '20/04/06', 'AD_VP'); /* employees 테이블이 매번 수정되는 테이블이라고 가정하자. 기존의 데이터는 email, phone, salary, comm_pct, man_id, dept_it 는 업데이트 하도록 처리하고, 새로 유입된 데이터는 그래도 추가하도록 만들자. */ MERGE INTO emps_it a USING (SELECT * FROM employees) b ON (a.employee_id = b.employee_id) WHEN MATCHED THEN UPDATE SET a.email = b.email, a.phone_number = b.phone_number, a.salary = b.salary, a.commission_pct = b.commission_pct, a.manager_id = b.manager_id, a.department_id = b.department_id WHEN NOT MATCHED THEN INSERT VALUES (b.employee_id, b.first_name, b.last_name, b.email, b.phone_number, b.hire_date, b.job_id, b.salary, b.commission_pct, b.manager_id, b.department_id); -- 아마 위 쿼리를 실행해봤으면 103번 사원이 두 명이 존재하게 될 텐데, -- CTAS로 테이블을 생성하는 바람에 제약조건이 복사되지 않아서 -- 중복된 employee_id를 갖는 사원이 생기게 됨. SELECT * FROM emps_it ORDER BY employee_id ASC; ROLLBACK;
연습문제
문제 1. DEPTS 테이블에 다음을 추가하세요.
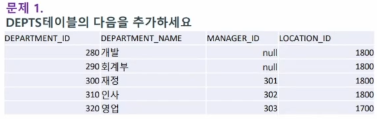
-- 문제 1. SELECT * FROM depts; CREATE TABLE depts AS (SELECT * FROM departments WHERE 1 = 1); INSERT INTO depts (department_id, department_name, manager_id, location_id) VALUES(280, '개발', null, 1800); INSERT INTO depts (department_id, department_name, manager_id, location_id) VALUES(290, '회계부', null, 1800); INSERT INTO depts (department_id, department_name, manager_id, location_id) VALUES(300, '재정', 301, 1800); INSERT INTO depts (department_id, department_name, manager_id, location_id) VALUES(310, '인사', 302, 1800); INSERT INTO depts (department_id, department_name, manager_id, location_id) VALUES(320, '영업', 303, 1700);
문제 2. DEPTS 테이블의 데이터 수정하기
1) department_name이 IT Support 인 데이터의 department_name을 IT bank로 변경
2) department_id 가 290인 데이터의 manager_id를 301로 변경
3) department_name이 IT Helpdesk 인 데이터의 부서명을 IT Help로, 매니저아이디를 303으로, 지역아이디를 1800으로 변경
4) department_id 가 290 ~ 320번인 데이터의 manager_id를 301로 일괄 변경
-- 문제 2. -- 2-1. UPDATE depts SET department_name = 'IT bank' WHERE department_name = 'IT Support'; -- 2-2. UPDATE depts SET manager_id = 301 WHERE department_id = 290; -- 2-3. UPDATE depts SET department_name = 'IT Help', manager_id = 303, location_id = 1800 WHERE department_name = 'IT Helpdesk'; -- 2-4. 회계, 재정, 인사, 영업의 manager_id를 한번에 301로 변경 UPDATE depts SET manager_id = 301 WHERE department_name IN('회계부', '재정', '인사', '영업'); SELECT * FROM depts;
문제 3. 데이터 삭제하기
삭제의 조건은 항상 primary key로 한다. 여기서 primary key는 department_id라고 가정하자.
1) 부서명 '영업'을 삭제
2. 부서명 'NOC'를 삭제
-- 문제 3. DELETE FROM depts WHERE department_id = 320; DELETE FROM depts WHERE department_id = 220;
문제 4.
1) depts 사본 테이블에서 department_id 가 200보다 큰 데이터를 삭제
2) depts 사본 테이블의 manager_id가 null이 아닌 데이터의 manager_id를 전부 100으로 변경
3) depts 테이블을 타겟 테이블로 놓고, departments 테이블을 매번 수정이 일어나는 테이블이라고 가정하고, depts와 비교하여 일치하는 경우 depts의 부서명, 매니저ID, 지역ID를 업데이트하고 새로 유입된 데이터는 그대로 추가하는 merge문 작성.
-- 문제 4. -- 4-1. DELETE FROM depts WHERE department_id > 200; -- 4-2. UPDATE depts SET manager_id = 100 WHERE manager_id IS NOT NULL; -- 4-3, 4-4 MERGE INTO depts a USING (SELECT * FROM departments) b ON (a.department_id = b.department_id) WHEN MATCHED THEN UPDATE SET a.department_name = b.department_name, a.manager_id = b.manager_id, a.location_id = b.location_id WHEN NOT MATCHED THEN INSERT VALUES (b.department_id, b.department_name, b.manager_id, b.location_id);
문제 5. jobs_it 사본 테이블 생성&수정
1) jobs_it 사본 테이블 생성 (조건 : min_salary 6000 이상)
2) jobs_it 테이블에 다음 데이터 추가

3) jobs_it 를 타겟 테이블로 놓고, jobs 테이블은 매번 수정이 일어나는 테이블이라고 가정하고, jobs_it와 비교하여 min_salary 컬럼이 0보다 큰 경우 기존의 데이터는 min_salary, max_salary 를 업데이트하고 새로 유입된 데이터는 그대로 추가해주는 merge 문을 작성할 것.
-- 문제 5. -- 5-1) CREATE TABLE jobs_it AS (SELECT * FROM jobs WHERE min_salary >= 6000); SELECT * FROM jobs_it; -- 5-2) INSERT INTO jobs_it VALUES('IT_DEV', '아이티개발팀', 6000, 20000); INSERT INTO jobs_it VALUES('NET_DEV', '네트워크개발팀', 5000, 20000); INSERT INTO jobs_it VALUES('SEC_DEV', '보안개발팀', 6000, 19000); -- 5-3, 5-4) MERGE INTO jobs_it a USING (SELECT * FROM jobs WHERE min_salary >= 0) b ON (a.job_id = b.job_id) WHEN MATCHED THEN UPDATE SET a.min_salary = b.min_salary, a.max_salary = b.max_salary WHEN NOT MATCHED THEN INSERT VALUES (b.job_id, b.job_title, b.min_salary, b.max_salary); SELECT * FROM jobs_it;
트랜잭션
- 트랜잭션은 논리적인 작업의 단위이다
- 트랜잭션은 분리되어서는 안 되는 작업의 단위이다
- 트랜잭션의 시작은 실행 가능한 첫 번째 SQL 문장이 실행 될 때 시작한다.
- 트랜잭션은 COMMIT 이나 ROLLBACK 문에 의해 명시적으로 종료하거나, DDL 이나 DCL 문장 실행으로 자동 커밋되어 종료될 수 있다.
- 사용자의 데이터베이스 종료 또는 시스템 충돌(Crash)에 의한 데이터베이스 비정상적 종료에 의해 트랜잭션이 종료되어 변경사항이 취소될 수 있다.
COMMIT
보류중인 모든 데이터 변경을 영구적으로 적용하면서 트랜잭션을 종료.
커밋한 이후에는 어떤 방법을 사용하더라도 되돌릴 수 없다.
COMMIT;
AUTOCOMMIT
-- 오토커밋 확인 SHOW AUTOCOMMIT; -- 오토커밋 온 SET AUTOCOMMIT ON; -- 오토커밋 오프 SET AUTOCOMMIT OFF; INSERT INTO emps (employee_id, last_name, email, hire_date, job_id) VALUES (300, 'kim', 'abc@naver.com', sysdate, 1800);
ROLLBACK
보류중인 모든 데이터 변경사항을 취소(폐기), 직전 커밋 단계로 회귀(돌아가기) 및 트랜잭션 종료
ROLLBACK;
SAVEPOINT
-- commit까진 아님 /* SAVEPOINT 생성 롤백할 포인트를 직접 이름을 붙여서 지정 ANSI 표준 문법이 아니기 때문에 그렇게 권장하지는 않는다. */ SAVEPOINT insert_kim; INSERT INTO emps (employee_id, last_name, email, hire_date, job_id) VALUES (301, 'Park', 'park@naver.com', sysdate, 1800); ROLLBACK TO SAVEPOINT insert_kim; SELECT * FROM emps;
CREATE
테이블 생성
NUMBER(2) -> 정수를 2자리까지 저장할 수 있는 숫자형 타입 NUMBER(5, 2) -> 정수부, 실수부를 합친 총 자리수 5자리, 소수점 2자리 NUMBER -> 괄호를 생략할 시 (38, 0)으로 자동 지정 VARHCAR2(byte) -> 괄호 안에 들어온 문자열의 최대 길이를 지정 (4000byte까지) DATE -> BC 4712년 1월 1일 ~ AD 9999년 12월 31일까지 지정 가능. 시, 분, 초 지원 가능CREATE TABLE dept2 ( dept_no NUMBER(2), dept_name VARCHAR2(14), loca VARCHAR(15), dept_date DATE, dept_bonus NUMBER(10) );
테이블 잘 생성되었는지 확인
DESC dept2; SELECT * FROM dept2;
NUMBER 타입에 들어가는 자리수를 확인
위에서 정한 자료형 수준을 넘어버리면 데이터 자체가 안 들어감.INSERT INTO dept2 VALUES(10, '영업', '서울', sysdate, 20000);
컬럼 추가
ALTER TABLE dept2 ADD (dept_count NUMBER(3));
열 이름 변경
ALTER TABLE dept2 RENAME COLUMN dept_count TO emp_count;
열 속성 수정
ALTER TABLE dept2 MODIFY (emp_count NUMBER(4));
열 삭제
ALTER TABLE dept2 DROP COLUMN emp_count;
테이블 이름 변경
ALTER TABLE dept2 RENAME TO dept3;
테이블 삭제
아래의 두 명령어는 ROLLBACK 불가.
따라서 두 명령어의 경우 서류 올려서 결재까지 받고 사용하는 경우가 많다고 하심.
테이블 삭제 (구조만 남기고 내부 데이터를 전부 삭제)TRUNCATE TABLE dept3; -- 테이블 자체를 삭제 DROP TABLE dept3;
