Computer Vision Self-study
1.[ 논문 리뷰 ] DETR: End-to-End Object Detection with Transformers
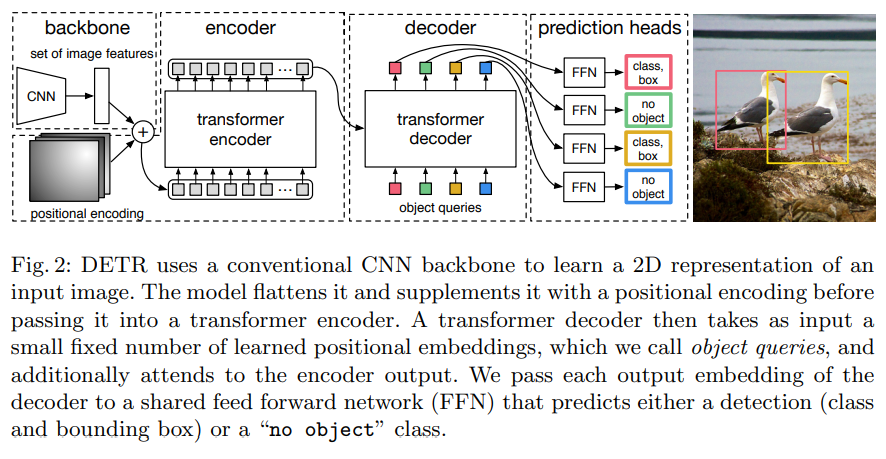
object detection의 최종 목표는, 관심 있는 각 object에 대해 category label과 bounding boxes 집합을 예측하는 것이다. 현대의 detector들은 이런 set prediction problem을 간접적으로 다룬다. (예를 들어,
2.[ 논문 리뷰 ] An Image is Worth 16X16 Words: Transformers for Image Recognition at Scale
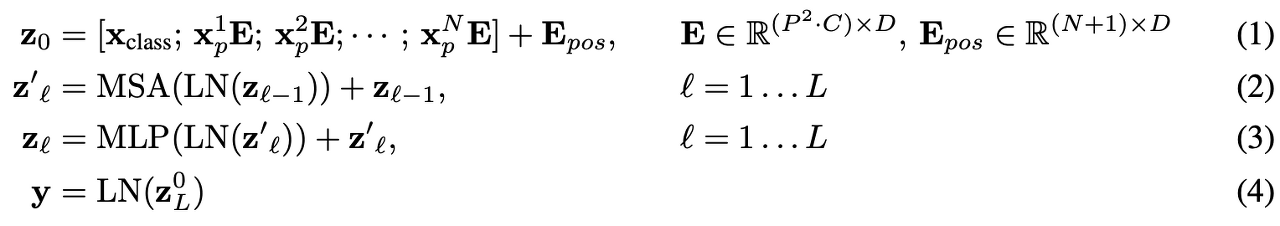
Self-attention 기반 구조는 NLP 분야에서 많이 사용되어 왔다. 가장 지배적인 방식은 큰 text corpus에서 사전 학습하고, 작은 task-specific 데이터셋에서 fine-tuning하는 BERT 방식이다. Transformer의 계산 효율성과
3.[ 코드 리뷰 ] Vision Transfomer (ViT) Pytorch 구현 코드 리뷰(1)
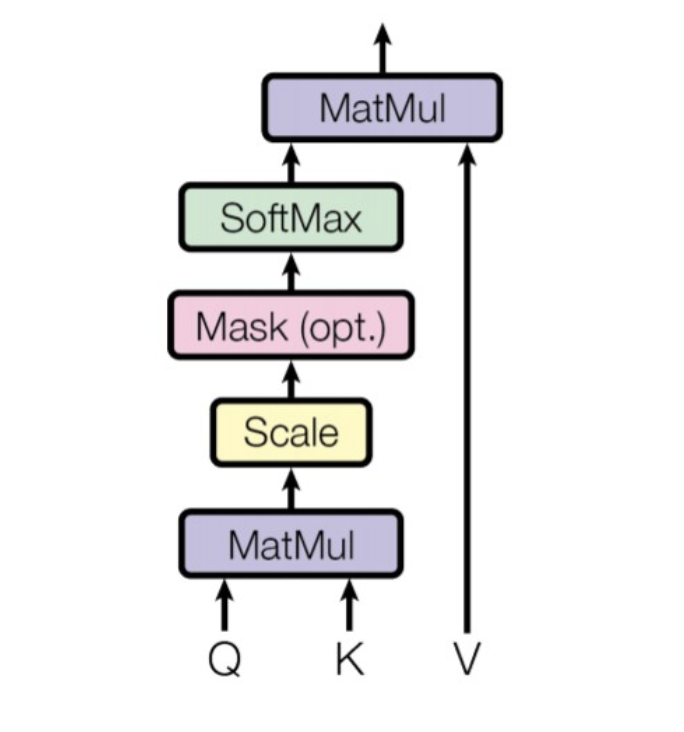
코드를 실행하기 위해 필요한 라이브러리와 프레임워크이다. 이미지를 패치로 쪼개 Embedding한다. 이 때, class token과 positional embedding을 추가한다. 그러므로, 처음으로 해야만 하는 단계는 이미지를 여러 패치로 쪼개어 flatten하는
4.[ 코드 리뷰 ] Vision Transfomer (ViT) Pytorch 구현 코드 리뷰(2)
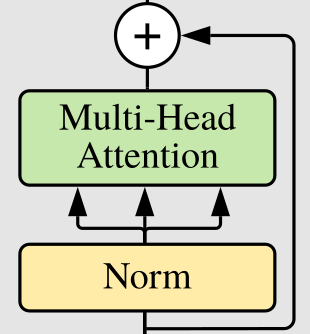
Residual Connection을 다음과 같이 클래스로 구현할 수 있다. fn을 forward하고 res를 더해 리턴한다. attention 결과가 완전 연결층으로 넘어가는데, 이 때 이 fully connected layer는 2개 레이어로 이루어져 있다. MLP
5.[ 논문 리뷰 ] Large-Scale Image Retrieval with Attentive Deep Local Features
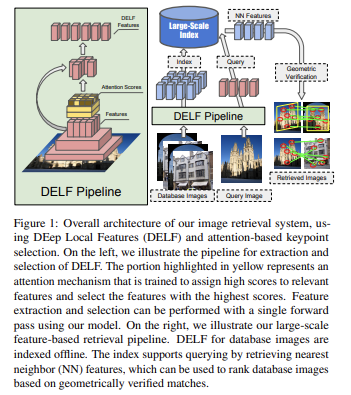
Paper : DELF (DEep Local Feature)이 논문에서는 DELF (DEep Local Feature)라는, 대규모 이미지 검색에 적합한 1️⃣ attentive local feature descriptor를 제안한다. 새 feature는 CNN 네트워