Residuals
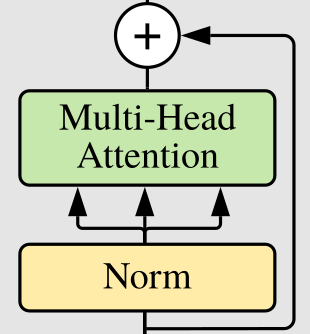
Residual Connection을 다음과 같이 클래스로 구현할 수 있다.
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return xfn을 forward하고 res를 더해 리턴한다.
MLP

attention 결과가 완전 연결층으로 넘어가는데, 이 때 이 fully connected layer는 2개 레이어로 이루어져 있다.
MLP 부분, 즉 Multi-Head Attention 이후 부분에서는,
1️⃣ Linear 2️⃣ GELU 3️⃣ Dropout 4️⃣ Linear 순서대로 진행된다.
두 Linear 레이어 중 첫 번째 Linear 레이어에서는, expansion을 곱해준대로, 임베딩 사이즈를 확장시킨다.
두 Linear 레이어 중 두 번째 Linear 레이어는 GELU, Dropout 이후에 이루어지는데, 원래의 임베딩 사이즈로 다시 축소시킨다.
FeedForwardBlock 클래스는 다음과 같다.
class FeedForwardBlock(nn.Sequential):
def __init__(self, emb_size : int, expansion : int = 4, drop_p : float = 0.):
super().__init__(
nn.Linear(emb_size, expansion * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(expansion * emb_size, emb_size)
)Transformer Encoder Block
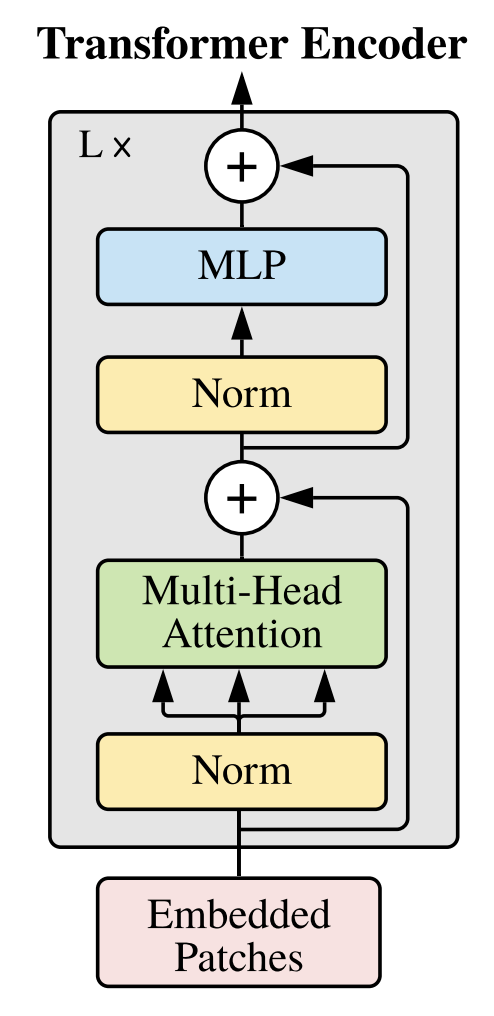
앞선 과정을 모두 합치면 Transformer의 Encoder Block을 만들어낼 수 있다.
ResidualAdd를 사용해주면 block을 잘 표현해낼 수 있다.
TransformerEncoderBlock 클래스를 다음과 같이 구현한다. nn.Module 대신 nn.Sequential을 상속한다.
class TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size: int = 768,
drop_p: float = 0.,
forward_expansion: int = 4,
forwrd_drop_p: float = 0.,
**kwargs):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size), # Norm
MultiHeadAttention(emb_size, **kwargs), #MHA
nn.Dropout(drop_p)
)),
ResidualAdd((
nn.LayerNorm(emb_size), # Norm
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p
), #MLP
nn.Dropout(drop_p)
))
)Transformer
ViT에서는 기존 transformer의 Encoder 부분만이 사용된다.
이제 앞에서 본 Encoder Block을 주어지는 depth만큼 쌓아준다.
class TransformerEncoder(nn.Sequential):
def __init__(self, depth : int = 12, **kwargs):
super.__init__(*[TransformerEncoderBlock(**kwargs) for _ in range(depth)])Head
마지막 레이어는 classification을 한다. 임베딩사이즈의 벡터를 1차원으로 투영하고, LayerNorm, nn.Linear을 거친다.
class ClassficationHead(nn.Sequential):
def __init__(self, emb_size : int =768, n_classes: int = 1000):
super().__init__(
Reduce('b n e -> b e', reduction = 'mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes)
)Vi(sual) T(ransformer)
최종 ViT 구조는 PatchEmbedding, TransformerEncoder, ClassificationHead으로 이루어져 있다.
class ViT(nn.Sequential):
def __init__(self,
in_channels : int = 3,
patch_size: int = 16,
emb_size: int= 768,
img_size: int = 224,
depth: int =12,
n_classes: int = 1000,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassficationHead(emb_size, n_classes)
)