[ 논문 리뷰 ] Large-Scale Image Retrieval with Attentive Deep Local Features
Computer Vision Self-study
Paper : Large-Scale Image Retrieval with Attentive Deep Local Features
DELF (DEep Local Feature)
0. Abstract
이 논문에서는 DELF (DEep Local Feature)라는, 대규모 이미지 검색에 적합한 1️⃣ attentive local feature descriptor를 제안한다. 새 feature는 CNN 네트워크를 기반으로 하는데, 랜드마크 이미지 데이터셋의 image 수준 주석으로”만” 학습된다.
이미지 검색을 위해, 의미적으로 유용한 local feature를 구별하기 위해, keypoint 선택을 위한 2️⃣attention mechanism도 제안한다.
이 시스템은 false positive를 reject하기 위해 reliable한 confidence score를 생성한다. — 데이터베이스와의 정확한 매칭이 없는 쿼리에 대해서 강건하다.
또, 이 논문에서 제안한 descriptor(DELF)을 평가하기 위해 3️⃣새로운 대규모 데이터셋, Google-Landmarks dataset을 제안한다.
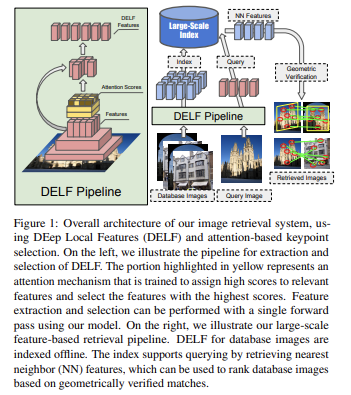
- DELF의 전체 구조는 위와 같다.
- 왼쪽을 보면, 추출된 feature들이 (노랗게 칠해진) attention mechanism을 지난다. 이는 관련된 feature에 대해 높은 점수를 할당하고, 가장 높은 점수를 가지는 feature들을 선택한다. 이렇게 Feature extraction과 selection이 단 한 번의 single forward pass만으로도 마칠 수 있다는 걸 볼 수 있다.
- 또, attention 모델이 descriptor와 강하게 결합(tightly coupled)되어 있는데;
-
동일한 CNN 구조를 재사용하고,
-
매우 적은 추가 계산비용으로도 feature score를 계산할 수 있다.
⇒ 이로 인해, one forward pass만으로도 local descriptor와 keypoint를 둘 다 추출할 수 있게 된다.
-
1. Introduction
최근에는, 이미지 검색을 위해, global descriptor learning을 위한 CNN을 기반으로 하는 방법들이 제시되어 왔다.
그런데, CNN 기반 global descriptor는 small/medium size 데이터셋에 대해서는 큰 진보를 보였지만, 여전히 대규모 데이터셋에 대해서는 많은 문제를 보였다.
⇒ 그 이유는, global descriptor가 이미지 간에 patch-수준 매치를 찾는 능력이 부족하기 때문이다.
background clutter(관심 대상과 유사한 다른 객체들이 다양하게 존재하면 구분이 어려운 경우)와 occlusion(물체 이동 시 다른 물체가 가려지는 경우) 때문에 부분 매칭 기반의 이미지를 검색하는 것이 어렵다.
최신 트렌드로는, CNN 기반의 local feature들이 patch 수준 매칭을 통해 얻어지는데, 이는 이미지 검색에 최적화되진 않았다.
⇒ 그 이유는, semantically meaningful feature을 탐지하는 능력이 부족해 정확도가 제한되기 때문이다.
⭐ 따라서, patch-level이 아닌 image-level로 retrieve해보는 게 어떨까?
또,현존하는 이미지 검색 알고리즘은 매우 적은 쿼리 이미지와 함께 small/medium-size 데이터셋에 대해서만 평가되어, 다양성이 제한되었다.
⭐ 따라서, “대규모” 데이터셋에 대해서도 좋은 성능을 보일 수는 없을까?
위와 같은 고려 사항들 때문에, 이 논문의 목적은 다음과 같다.
⭐ 최신 CNN feature descriptor를 기반의 대규모 이미지 검색 시스템을 개발하자.이 목적을 달성하기 위해, 다음을 도입한다.
1) Google-Landmark라는 새로운 대규모 데이터셋을 도입한다.
⇒ 데이터베이스와 매치가 없는 이미지들도 포함해서, 쿼리가 랜드마크를 묘사하지 않을 때, robustness를 평가할 수 있도록 함.
2) attention과 함께 CNN기반의 local feature를 도입한다.
⇒ object 수준/patch 수준의 주석 없이도, image 수준의 class label만을 써도 weak supervision으로도 학습할 수 있음. ⭐⭐
2. Related Work
이미지 검색의 평가를 위해 주로 쓰이는 표준 데이터셋 3가지가 대표적이다. : Oxford5k, Paris6k, Flickr100k. 그런데 이 3가지 데이터셋은 “작다”, 특히 쿼리 이미지 수는 더 작아, 일반화 능력이 적다.
최근에는, lcoal feature를 aggregate하는 방식들이 집중을 받는데, 이런 global descriptor의 주요 장점은 compact index로 고성능의 이미지 검색을 할 수 있는 능력이다.
CNN 기반의 global descriptor는 semantically meaningful feature를 학습하지 않기 때문에 이미지 검색에 적합하다고 볼 수 없었다.
⇒ 즉, 이 연구의 모델은 semantically meaningful feature를 학습해 선택한다.
3. Google-Landmarks Dataset
기존 데이터셋과는 달리 새로운 데이터셋은 훨씬 더 크고, 다양한 랜드마크를 포함하고, 상당한 도전 과제도 포함한다. : (데이터베이스와의 match가 없는 이미지도 포함하기 때문)
현존하는 데이터셋의 대부분의 이미지가 랜드마크 중심적이어서 global descriptor가 잘 작동하던 반면에, 이 데이터셋은 훨씬 더 현실적이다.: 전경/배경 clutter, occlusion 등을 포함한다. 특히, 1️⃣ 랜드마크를 포함하지 않을 수도 있고 2️⃣ 데이터베이스의 이미지를 검색하지 못할 수도 있다. 이런 것들을 query image “distractor”라고 부르는데, 이는 관련 없거나, noisy한 쿼리에 대해 robustness를 평가할 수 있도록 하는 중요한 역할을 수행한다.
데이터베이스의 모든 이미지는 2가지 정보를 기반으로 모이고, 각 cluster에 landmark identifier를 할당한다. 만약 쿼리 이미지의 위치와 cluster의 중심 간의 “물리적 거리”가 threshold보다 적다면, 두 이미지가 같은 랜드마크에 속한다고 가정한다.
랜드마크가 무엇인지 미리 정의할 수 없다는 것을 고려하면 ground-truth annotation이 어렵다는 걸 알 수 있다. 또, 하나의 이미지 내에 여러 instance가 있을 수도 있기에 랜드마크가 noticeable하지 않을 수 있다. 더불어, GPS 에러 때문에 noisy할 수도 있다. 게다가, 랜드마크로부터 멀리서 찍어서 사진을 찍은 위치가 실제 랜드마크 위치로부터 상대적으로 멀 수도 있다. 그러나, 이런 사소한 minor error가 있더라도, 문제가 되지 않는다. 그 이유는, 알고리즘은 랜드마크가 외관상으로 충분히 구별 가능하다면, 랜드마크들을 혼동하지 않기 때문이다.
4. Image Retrieval with DELF
DELF는 4가지 블럭으로 나뉠 수 있다.
1) Dense localized feature extraction
2) Keypoint selection
3) Dimensionality reduction
4) Indexing and Retrieval
4.1. Dense Localized Feature Extraction
이 모델은 FCN (Fully Convolutional Network)를 적용해 이미지로부터 dense feature를 추출한다.
scale change를 다루기 위해, image pyramid를 만들어 각 레벨에 대해 FCN을 적용한다. 그렇게 얻은 feature map을 local descriptor의 dense grid로 볼 수 있다. feature들은 receptive field를 기반으로 국소화되어, FCN의 convolutional, pooling layer들의 구성을 고려해 계산할 수 있다. receptive fiedl의 중심의 픽셀 좌표가 feature location으로 쓸 수 있다.
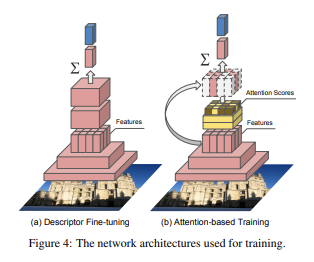
Figure 4의 (a)를 보면, input 이미지가 처음엔 center-crop되어 정사각형 이미지를 생성하고, 사이즈로 맞춰진다. 그러고는, crop이 랜덤하게 학습에 쓰인다. 학습 결과로, local descriptor는 암시적으로 representation을 학습한다. 이런 방식으로, 향상된 local descriptor를 얻기 위해, 굳이 object 수준, patch 수준의 label이 필요 없게 된다.
4.2. Attention-based Keypoint Selection
직접적으로 densely extracted feature를 쓰기 보다는, feature의 subset을 효율적으로 선택할 것이다. densely extracted feature의 상당 부분이 관련 없고 clutter가 추가하기도 하기 때문에, keypoint selection이 정확성 측면과 계산 효율성 측면 모두에서 중요하다.
4.2.1. Learning with Weak Supervision
local feature descriptor를 위해 명시적으로 relevance score를 측정할 수 있는 attention과 함께 landmark classifier를 학습시킨다.
Figure 4. (b)를 보면 노랗게 색칠된 부분을 볼 수 있는데, 이는 attention network이다. 이는 전체 input image에 대한 임베딩을 생성하는데, 이는 softmax 기반의 landmark classifier를 학습시키는 데에 쓰인다.
이 과정들을 공식화해보자.
이 차원의 feature라고 하자.
우리 목적은 각 feature에 대해 score function 를 학습하는 것이다. : 이 때, 는 functino 의 parameter이다. 그리고 output logit 는 feature 벡터의 가중치 합으로 생성된다.
이 때, 는 class를 예측하기 위해 학습된 CNN의 FC layer의 최종 가중치이다. 학습을 위해, cross entropy loss를 사용할 것이다. cross entropy loss는 다음과 같다.
이 때, 는 원-핫 표현으로 된 ground-truth이고, 은 one vector이다. score function 의 패러미터는 역전파로 학습될 수 있다. 따라서 gradient는 다음과 같이 계산될 수 있다.
이 때, output score 의 역전파는 표준 MLP와 같다.
negative weighting을 하지 않도록 하기 위해서 는 non-negative하다고 제한한다.
4.2.2. Training Attention
descriptor와 attention 모델 둘 다 이미지 수준의 label로 학습될 수 있다.
feature representation과 score function이 동시에 역전파로 학습될 수 있는 반면에, 이 셋업이 weak model을 생성해내는 걸 확인할 수 있었다.
따라서, 2단계의 학습 전략을 세웠다.
1) fine-tuning으로 descriptor를 학습시킨다.
2) fixed descriptor가 주어지면 score function이 학습된다.
4.2.3. Characteristics
기존 기술과는 달리, 이 시스템에서는 descriptor extraction 이후에 keypoint selection 단계가 따라와서, keypoint는 1) detect되고는 2) describe된다.
제안된 파이프라인은, feature map에 higher level semantic을 인코딩하는 모델을 학습시키고 discriminative feature를 선택하도록 학습시켜 두 가지 목표를 달성한다.
4.3. Dimensionality Reduction
1) 선택된 feature는 -normalize된다
2) PCA로 인해 dimensionality를 40으로 줄인다.
⇒ compactness와 discriminativeness간의 tradeoff
3) feature가 다시 normalize된다.
4.4. Image Retrieval System
쿼리와 데이터베이스로부터 feature descriptor를 추출한다. 우리 이미지 검색 시스템이 nearest neighbor(NN) search를 기반으로 하기에, KD-tree와 Product Quantization (PQ)의 결합으로 수행된다.
쿼리가 주어지면,
1) approximate nearest neighbor search를 수행한다.
⇒ 쿼리 이미지로부터 추출된 각 local descriptor에 대해 적용한다.
2) top nearest local descriptor에 대해, 모든 매치를 aggregate
3) Geometric verification 수행
4) inlier의 개수를 검색된 이미지의 score로 사용.
많은 distractor query들이 이 geometric verification 단계에서 걸러진다. 그 이유는, distractor의 feature들이 랜드마크 이미지와 일관되게 매치되지 않을 수 있기 때문이다.
5. Experiments
5.1. Implementation Details
[ Multi-scale descriptor extraction ]
[ Training ]
[ Parameters ]
5.2. Compared Algorithms
[ Deep Image Retrieval (DIR) ]
[ siaMAC ]
[ CONGAS ]
[ LIFT ]
5.3. Evaluation
5.4. Quantitative Results
5.5. Qualitative Results
[ DELF vs. DIR ]
[ DELF vs. CONGAS ]
[ Analysis of keypoint detection methods ]
5.6. Results in Existing Datasets
6. Conclusion
대규모 이미지 검색에 특화된 새로운 local feature descriptor인 DELF를 제안한다.
1) DELF는 weak supervision으로도 학습된다.
2) 오직 이미지 수준의 label만을 사용해 학습된다.
3) semantic feature selection을 위한 새로운 attention 메커니즘을 제안한다.
4) 단 한 번의 forward pass만으로도 keypoint와 descriptor 둘 다를 얻을 수 있다.
5) 새로운 대규모 데이터셋인 Google-Landmarks dataset을 도입한다.
