01. Analysis Seoul CCTV
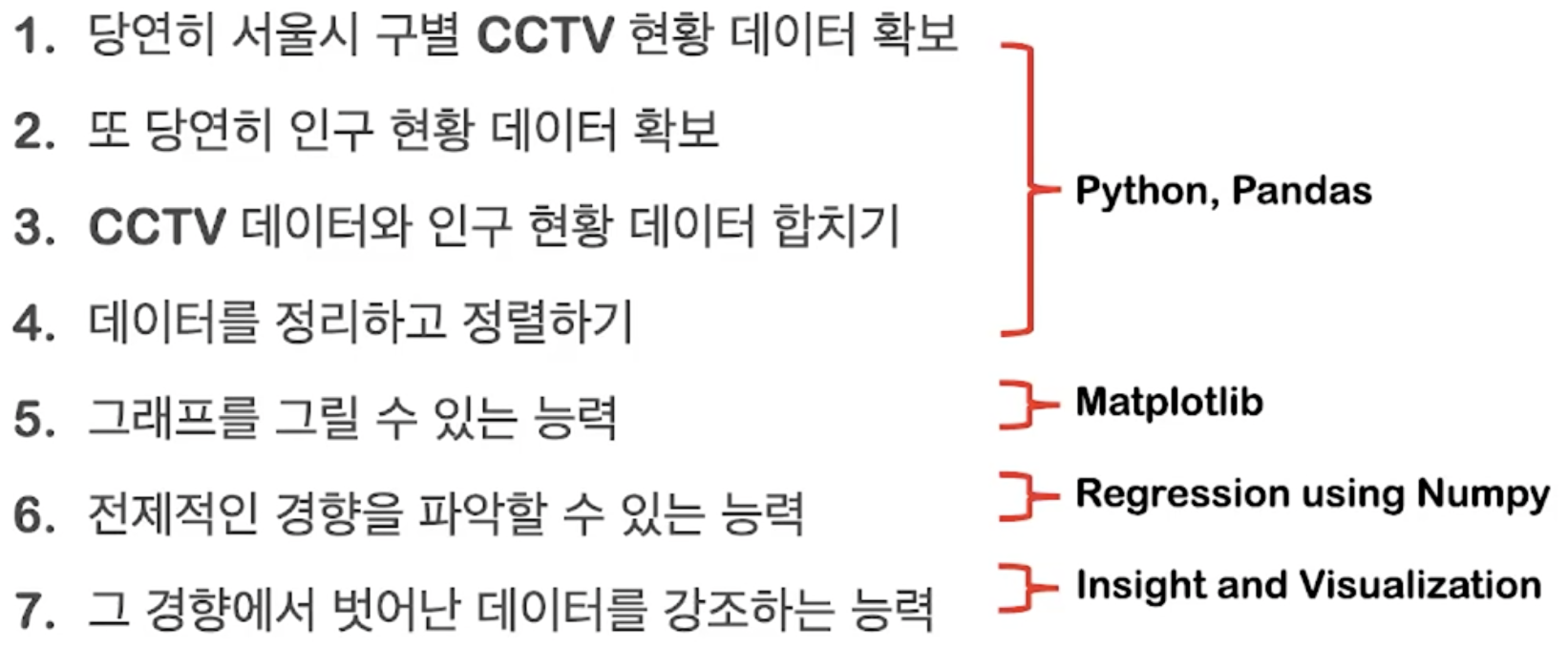
📍 1. 데이터 읽기
🔖 Pandas Basic
- Python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 누군가 스테로이드를 맞은 엑셀로 표현함
# pandas 이용한 파일 불러오기 # 1 import pandas as pd --> 선언 import numpy as np --> 선언
- pandas는 통상 pd
- numpy는 통상 np
# 2 변수명 = pd.read_csv("../파일경로/파일명.csv") # 3 한글오류방지 변수명 = pd.read_csv("../파일경로/파일명.csv", encoding="utf-8)
🔖 Series
-
index와 value로 이루어져 있습니다
-
한 가지 데이터 타입만 가질 수 있습니다
-
numpy와 pandas 패키지를 모두 import해야한다.
-
pd.Series() : python의 list나 numpy의 array가 인자로 입력
# Series 만들기
list = pd.Series({1, 3, 5, np.nan, 6, 8})
array = pd.Series(np.array([1, 2, 3, 4]))
dtype
# dtype-str설정
str = pd.Series([1, 2, 3, 4], dtype=str)
# dtype-float64설정
float64 = pd.Series([1, 2, 3, 4], dtype=np.float64)pd.date_range()
# 날짜(시간)을 이용
dates = pd.date_range("20230606", periods=6)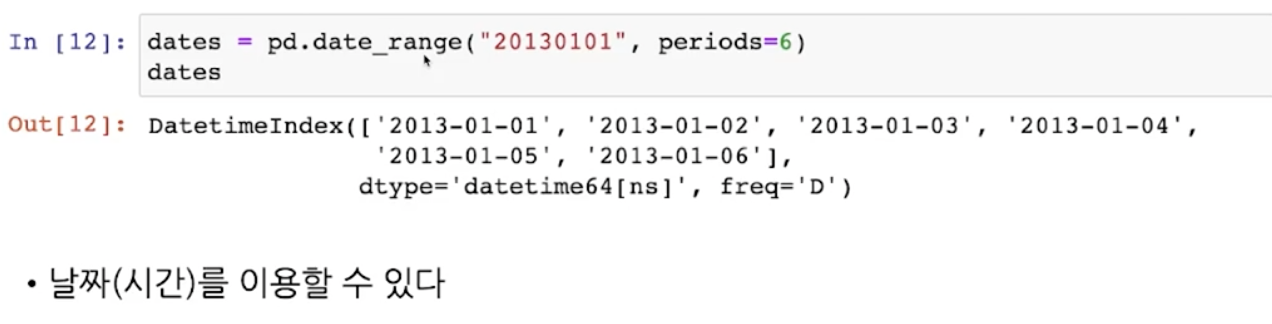
- start, end, periods, freq는 같이 쓸수 없다(오류발생)
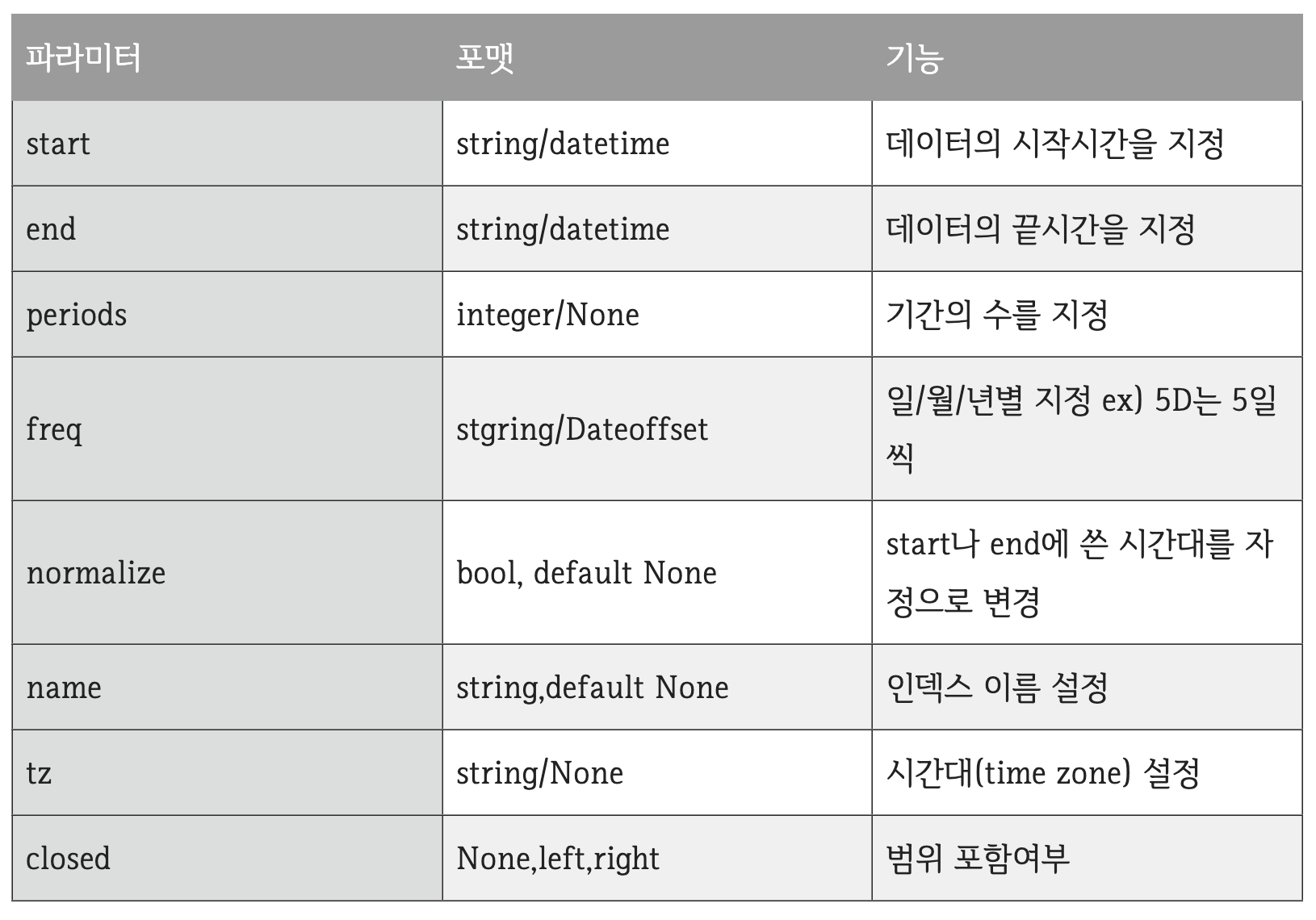
- freq값
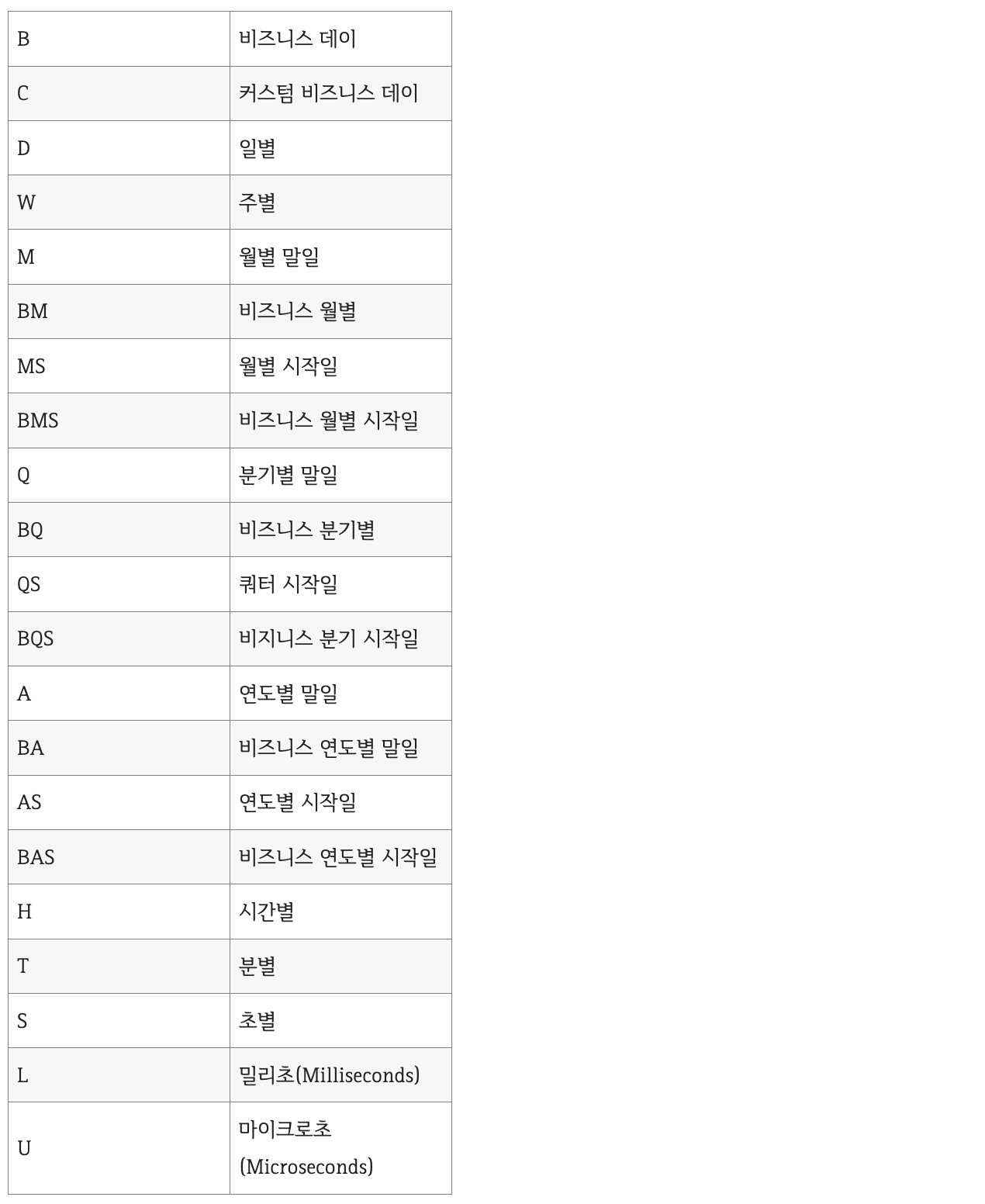 예) date_range() start, end 3일간격(freq)
예) date_range() start, end 3일간격(freq)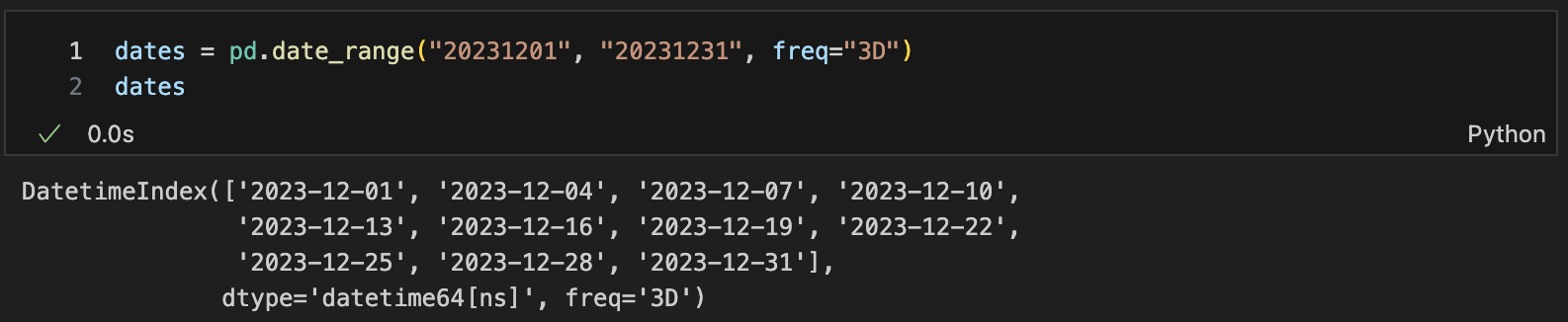
출처 : https://seong6496.tistory.com/120
🔖 DataFrame
- pd.Series()
- index, value
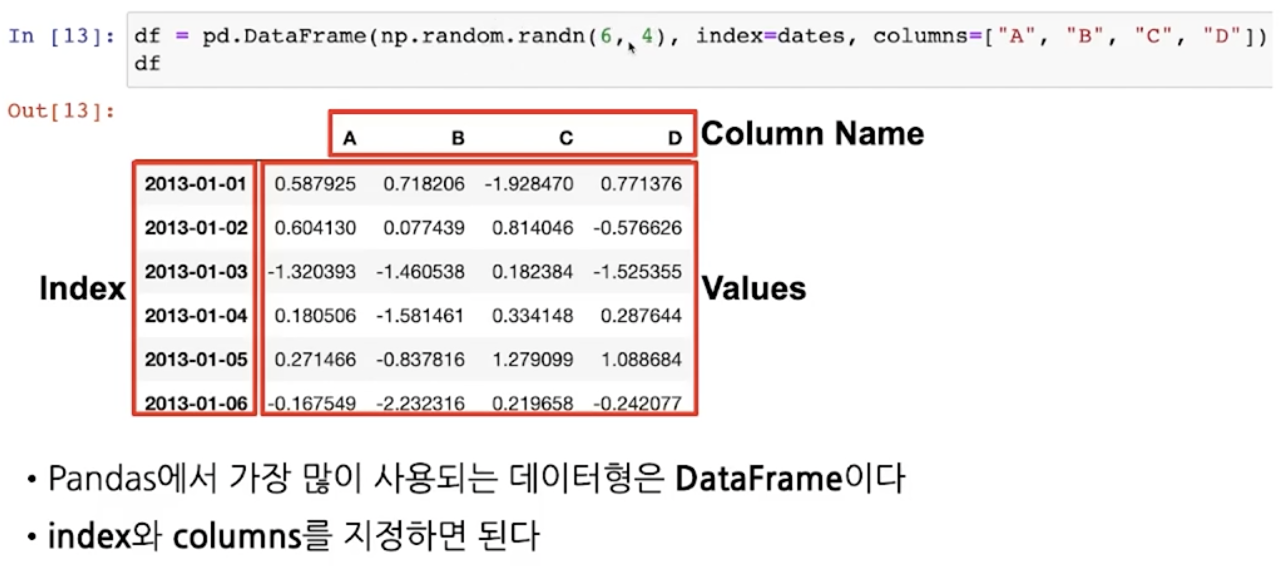
- pd.DataFrame()
- index, value, column
numpy의 np.random.
randintvsrand,randnnp.random.randint: 사이숫자 랜덤하게 1개 뽑기np.random.rand: 0부터 1사이의 균일분포 표준 정규분포에서 난수생성np.random.randn: 평균0, 표준편차1의 표준 정규분포에서 난수생성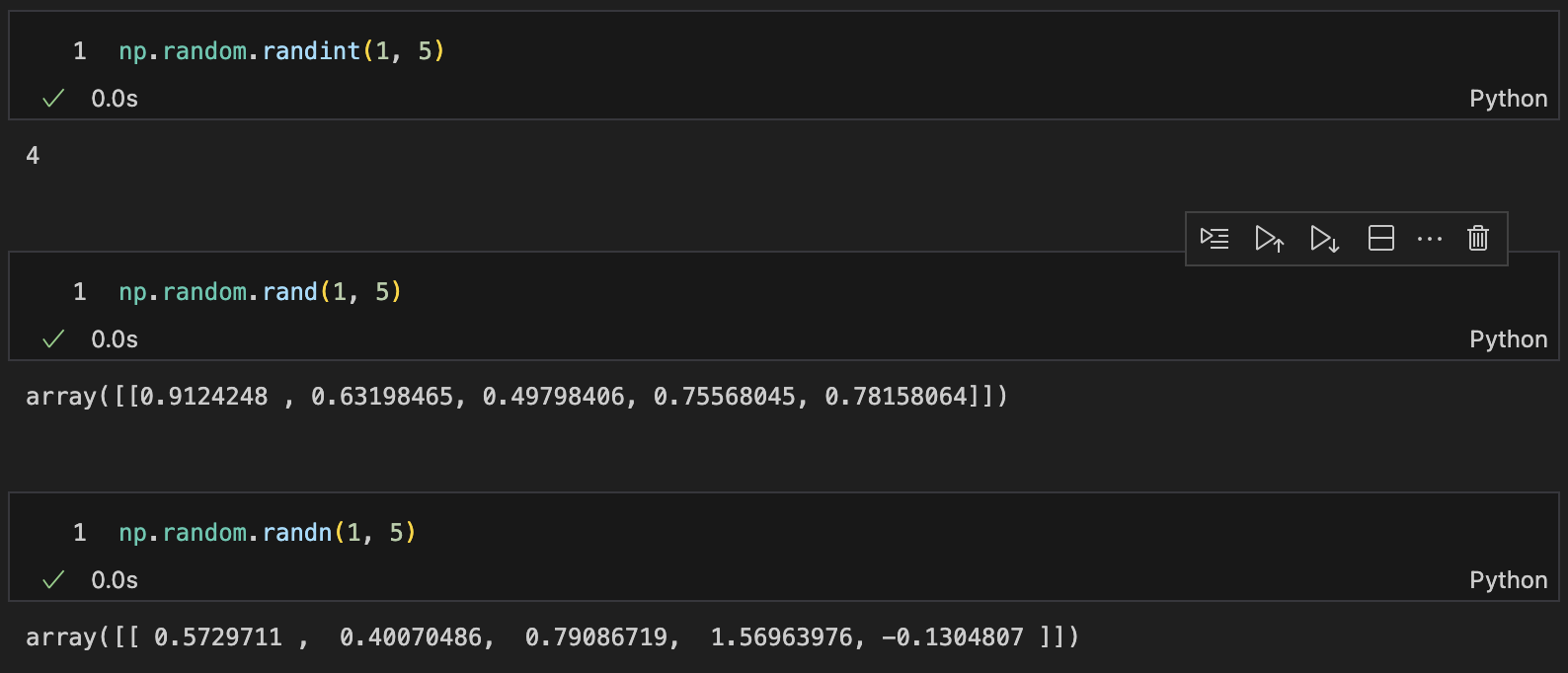
# 표준 정규분포에서 난수 생성(np.random.randn)
data = np.random.randn(6, 4)
data
# DataFrame 생성
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=["A", "B", "C", "D"])
🔖 데이터 정렬
- sort_values()
- 특정 컬럼(열)을 기준으로 데이터를 정렬합니다
sort_values : 데이터 정렬
# 오름차순 : ascending=True
df.sort_values(by="columnName", ascending=True)
# 내림차순 : ascending=False
df.sort_values(by="columnName", ascending=False)
# 새로운정보 저장 : inplace=True
df.sort_values(by="columnName", ascending=False, inplace=True)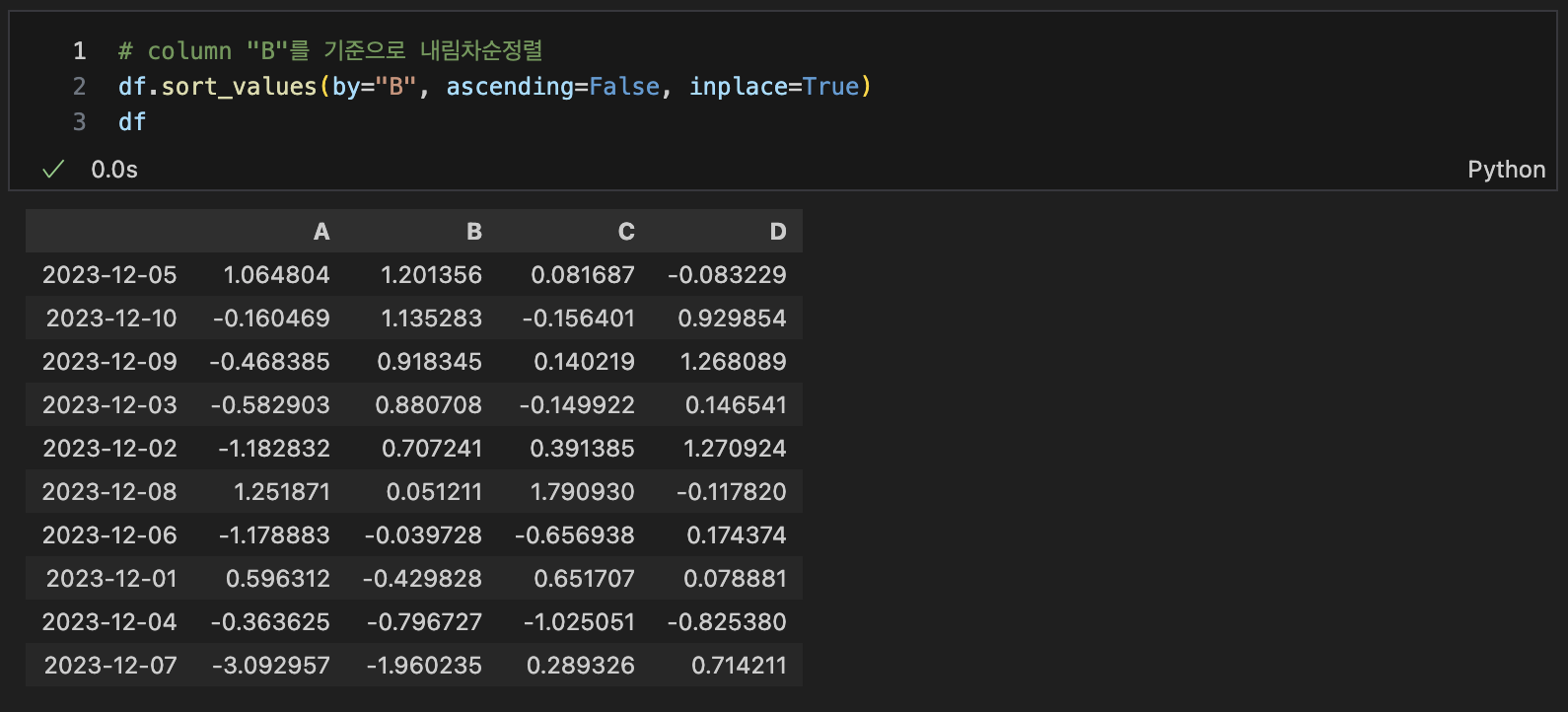
🔖 컬럼선택
한개 선택
df["columnName"]
df.columnName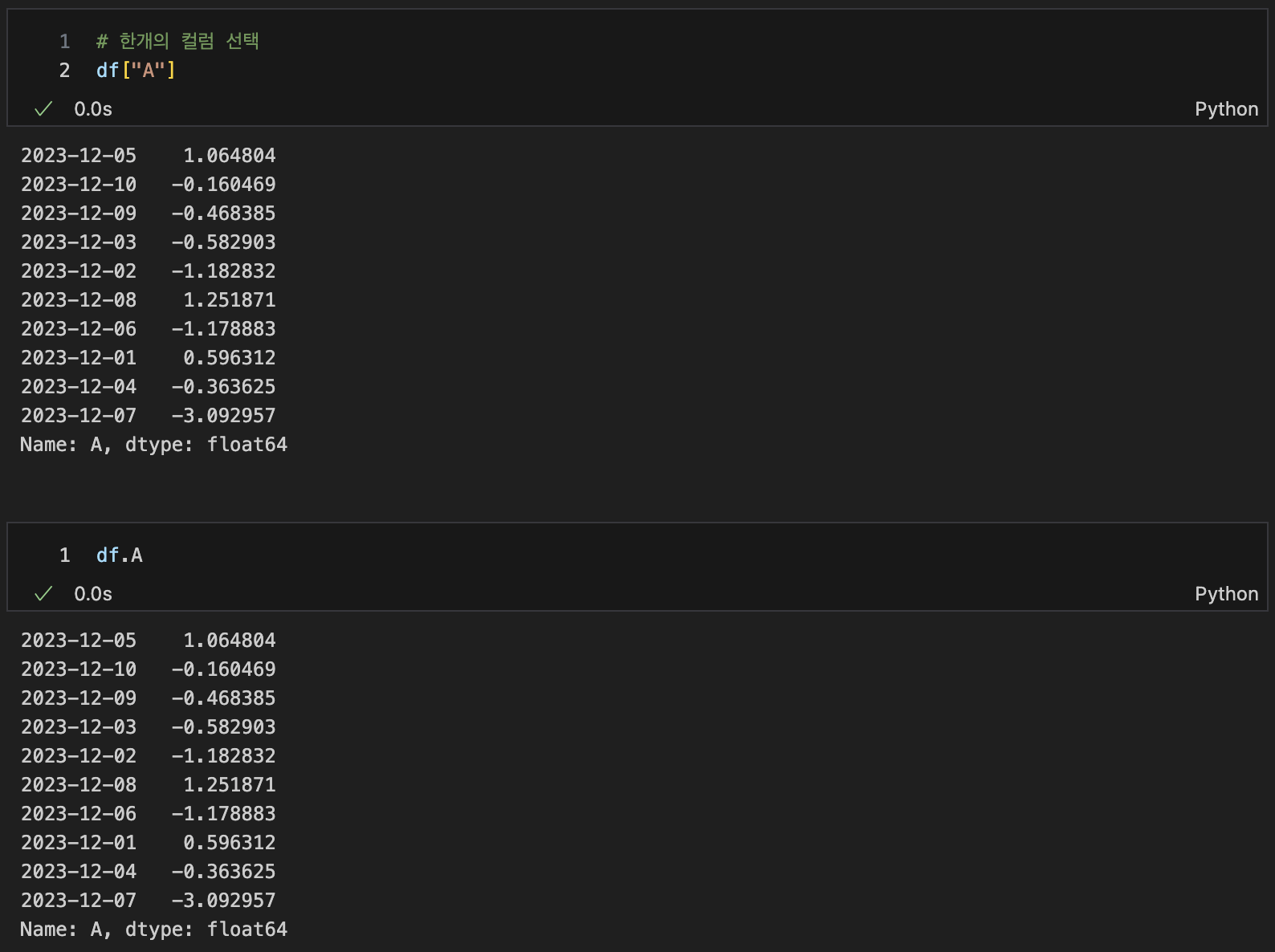
두개이상 선택
df[["A", "B"]]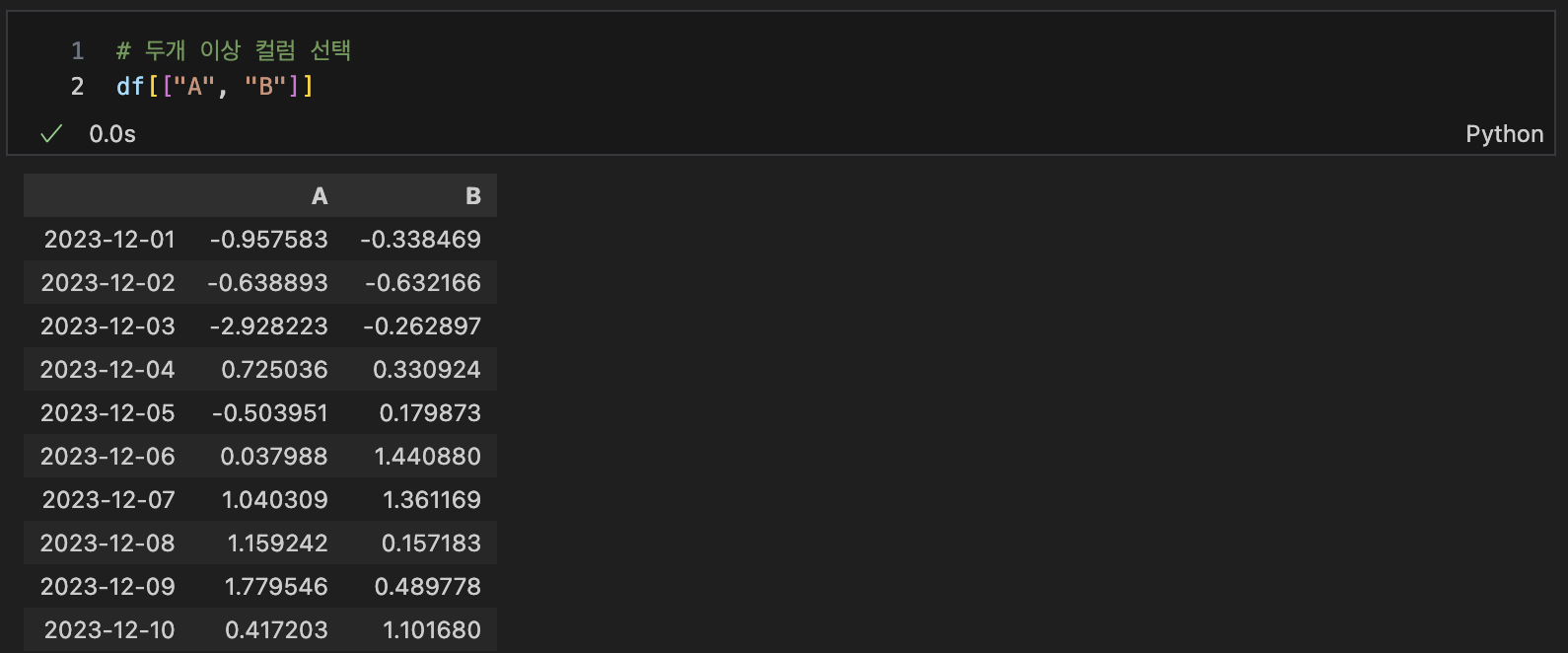
🔖 offset index(slice)
[n:m] : n부터 m-1 까지
- 인덱스나 컬럼의 이름으로 slice 하는 경우는 끝을 포함합니다
# index 0부터 2까지
df[0:3]
# 20230604부터 20230606까지
df["20230604":"20230606"] - loc : location
- index 이름으로 특정 행, 열을 선택합니다
# column A와 B의 전체인덱스의값
df.loc[:, ["columnNameA", "columnNameB"]]
# column A와 B의 index 0부터 5까지의값
df.loc["indexName0":"indexName5", ["columnNameA", "columnNameB"]]
# column A부터 D index 0부터 3까지의값
df.loc["indexName0":"indexName3", "columnNameA":"columnNameD"]
# column A와 B index 2 의값
df.loc["indexName2", ["columnNameA", "columnNameB"]]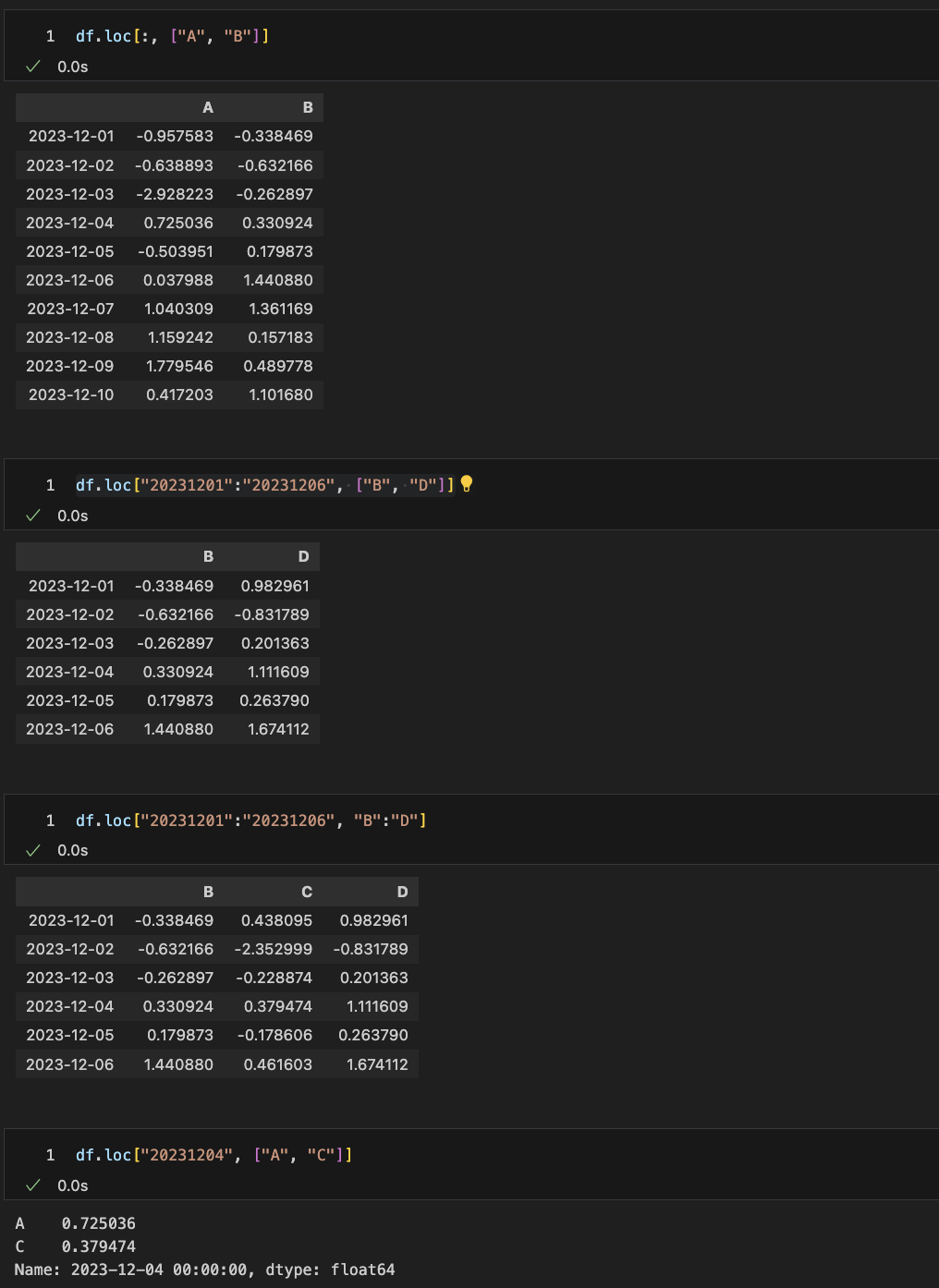
- iloc : inter location
- 컴퓨터가 인식하는 인덱스 값으로 선택
df.iloc[3]
df.iloc[3, 2]
df.iloc[3:5, 0:2]
df.iloc[[1, 2, 4], [0, 2]]
df.iloc[:, 1:3]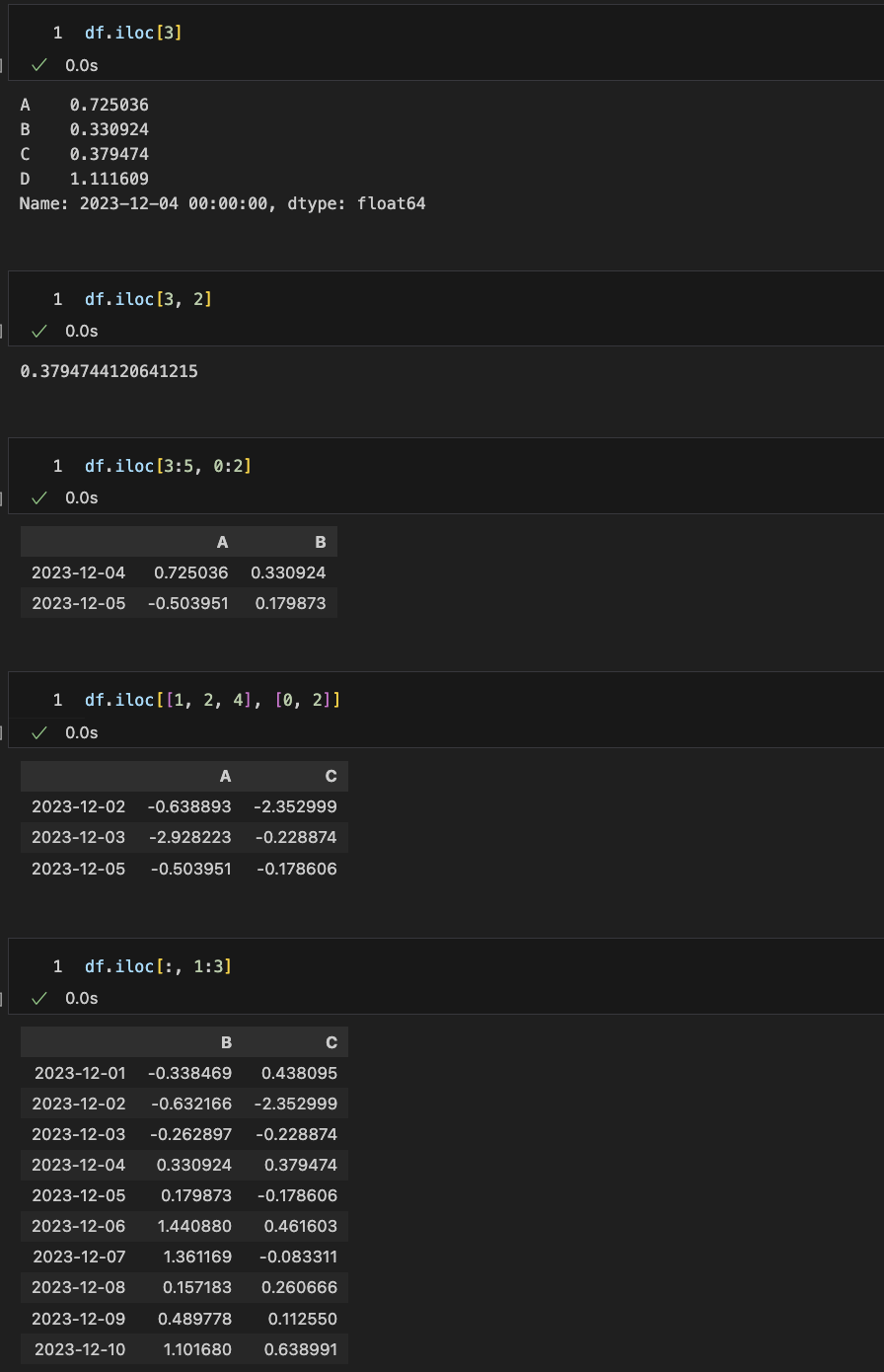
🔖 condition
- 범위 컬럼 선택
A 칼럼에서 0보다 큰 숫자(양수)만 선택
df["A"] > 0
df[df["A"] > 0]
df[df > 0]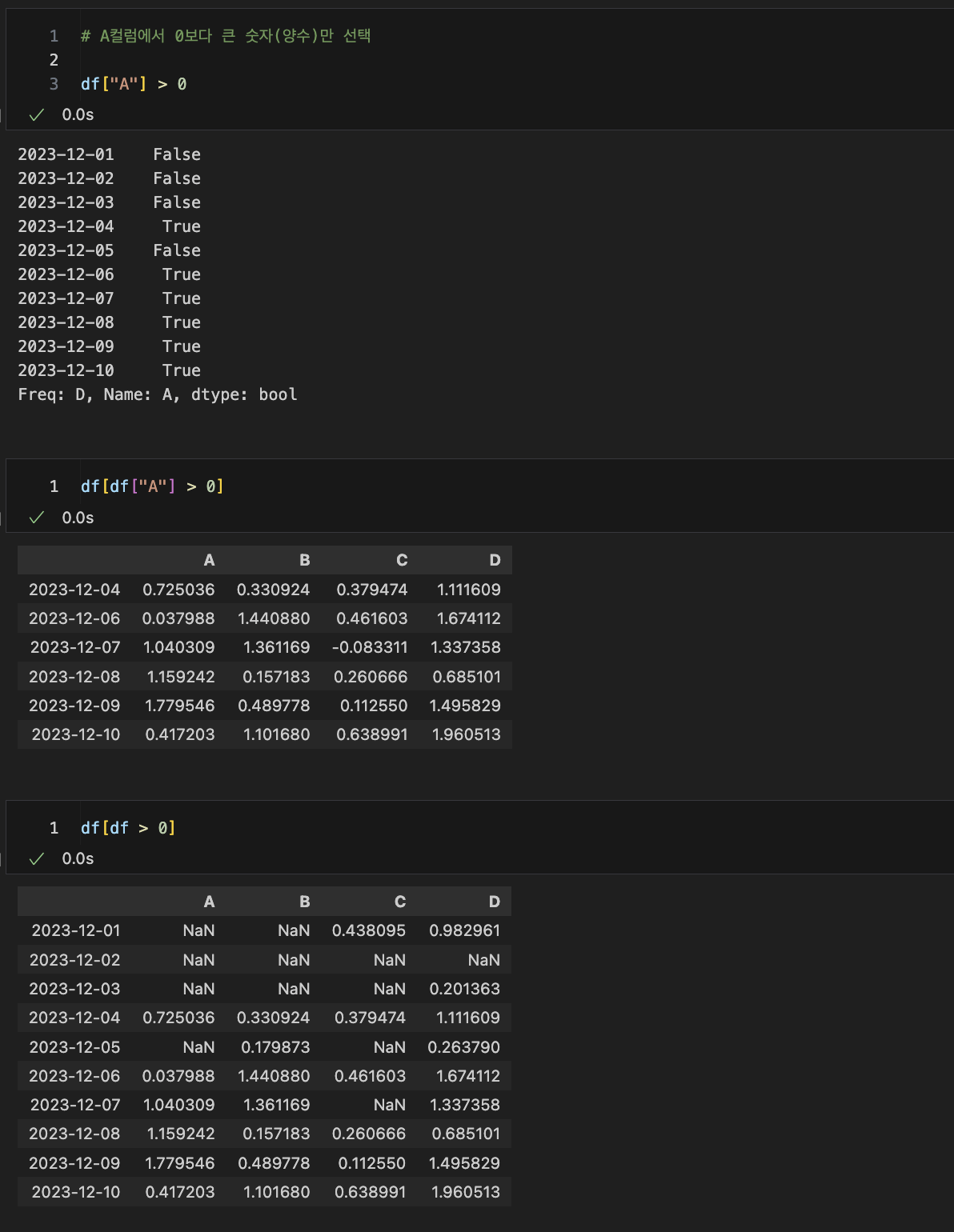
NaN : Not a Number
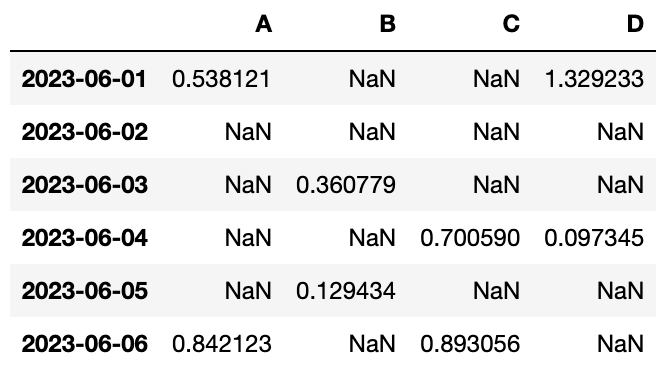
🔖 컬럼 추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
- 행, 열 만들어 추가/ 수정

특정요소 찾기
isin()
# 특정요소 있는지 확인
df["E"].isin(["TWO", "four"])
--> "E"열에 "TWO", "four" 있으면 True, 없는열은 False
# 특정요소가 있는 행만 선택
df[df["E"].isin(["TWO", "four"])]
--> "E"열에 "TWO", "four"가 있는 특정열만 보여줌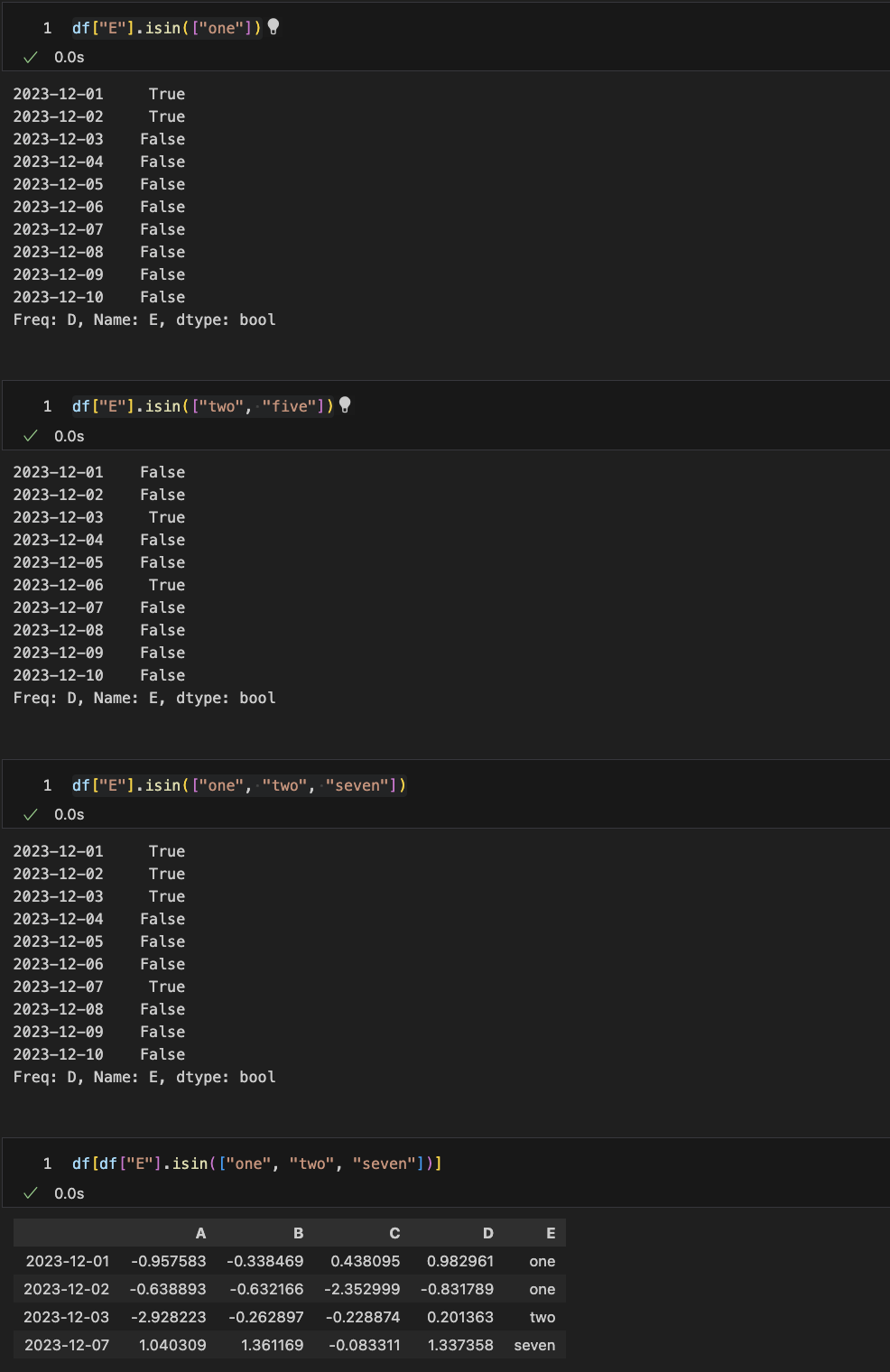
특정 컬럼 제거
del
del df["E"] --> "E"열 제거drop
df.drop(["20230601"])
df.drop(["D"], axis=1) # axis=0 가로, axis=1 세로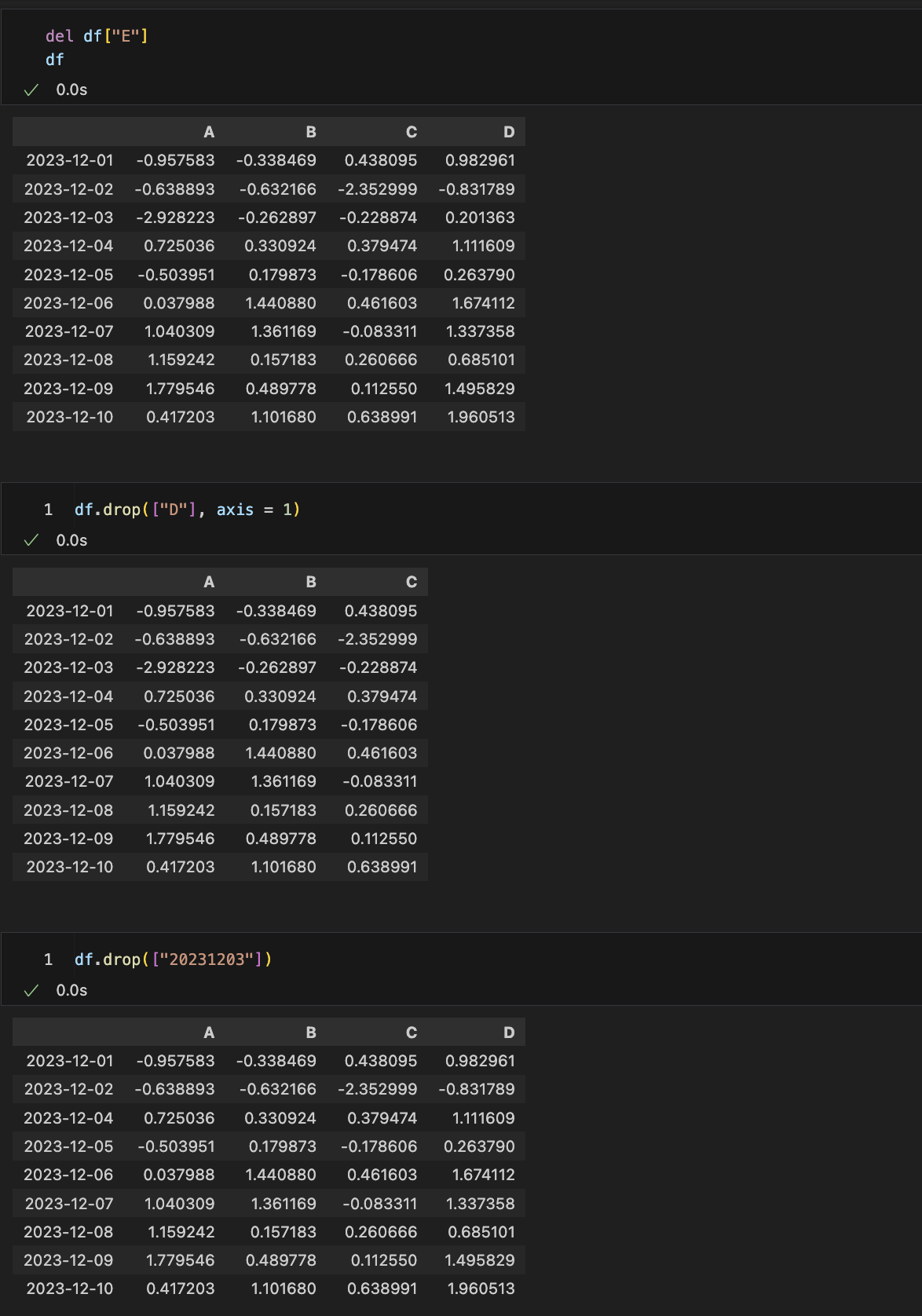
🔖 apply()
- 연산을 가능하게 해주는 함수
컬럼 누적 합
df["A"].apply("sum")
df[["A", "D"]].apply("sum")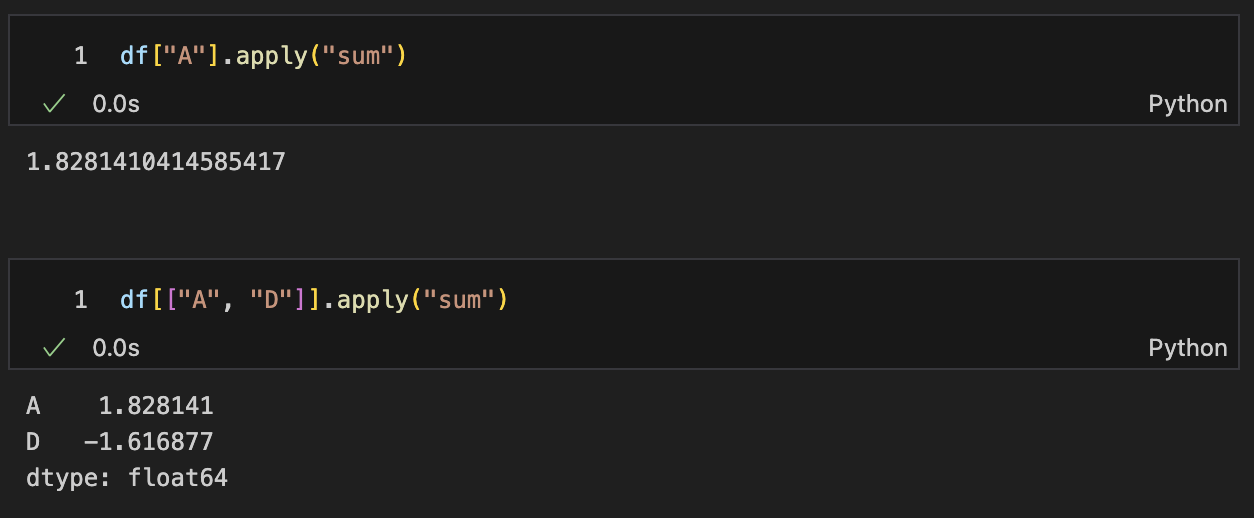
평균
df["A"].apply("mean")
최소, 최대값
df["A"].apply("min"), df["A"].apply("max")
np 이용
# 합
df["A"].apply(np.sum)
# 평균
df["A"].apply(np.mean)
# 지정된 축에 따른 표준편차계산
df["A"].apply(np.std)
# 각 컬럼별 합
df.apply(np.sum)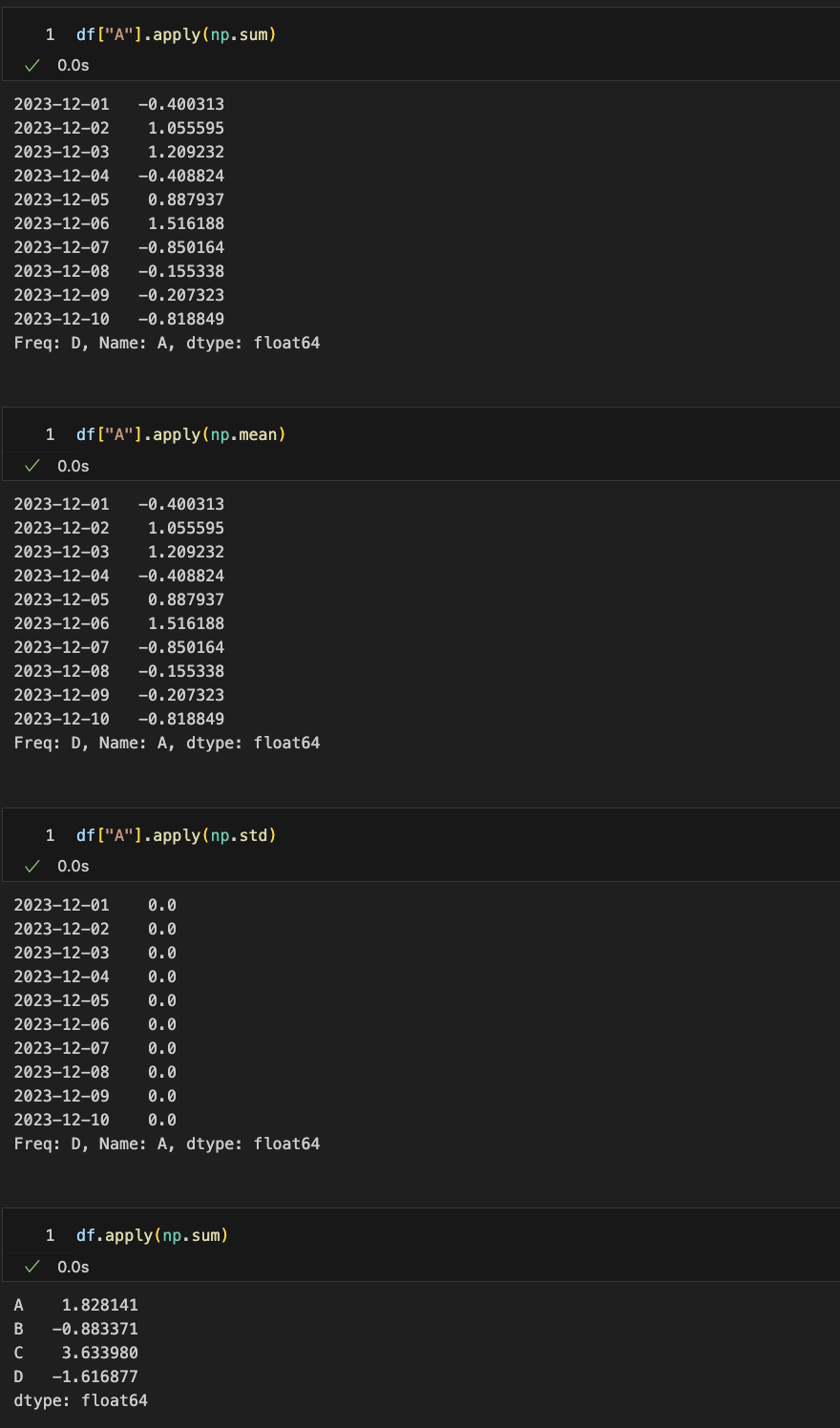
양수, 음수 찾기
lambda 매개변수 : 표현식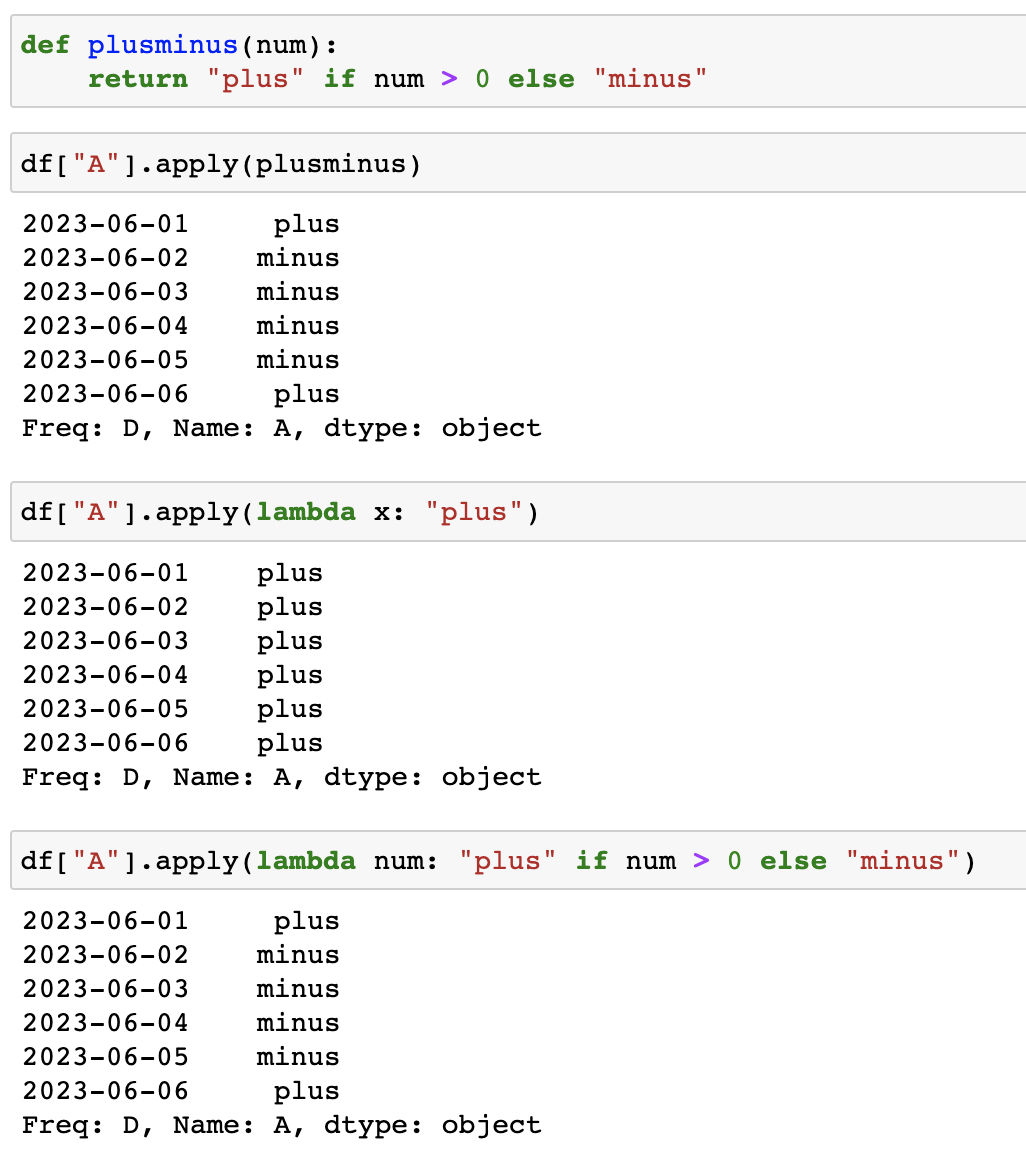
✨ 코드 정리
자료보기
.head() --> 시작자료 5개 자료 확인
.head(n) --> 시작자료 n개 자료 확인
.tail() --> 끝나는자료 5개만 볼 수 있음, 총자료수 확인 가능
.tail(n) --> 끝나는자료 n개 확인
.columns --> 전체 이름조회(리스트형태로 반환됨+인덱스가 생김)
.colums[n] --> n번째 위치한 이름 조회(인덱스로 조회가능)
head=n --> n번째부터 자료읽기
usecols = 'a, b, c, d' --> 읽어올 컬럼 지정
.index --> index 자료 확인
.values --> 밸류값 조회
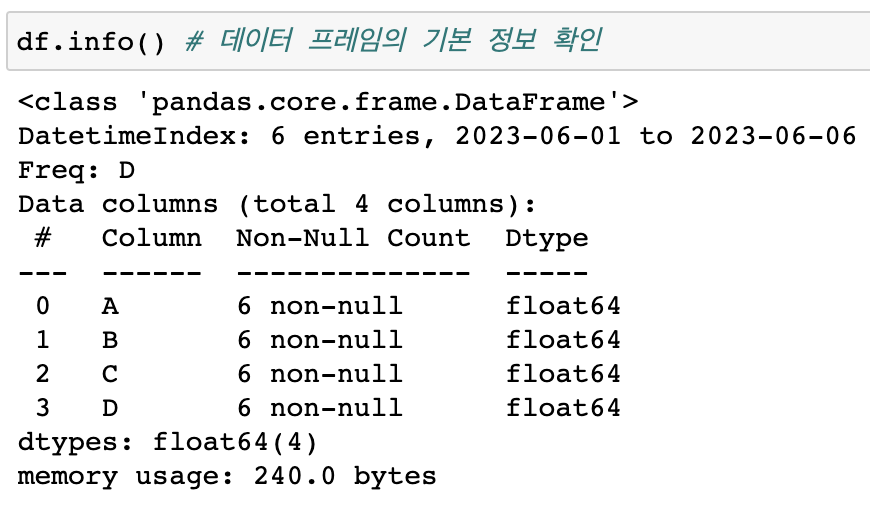
.info() --> 기본정보 확인(각 컬럼의 크기와 데이터형태 확인가능)
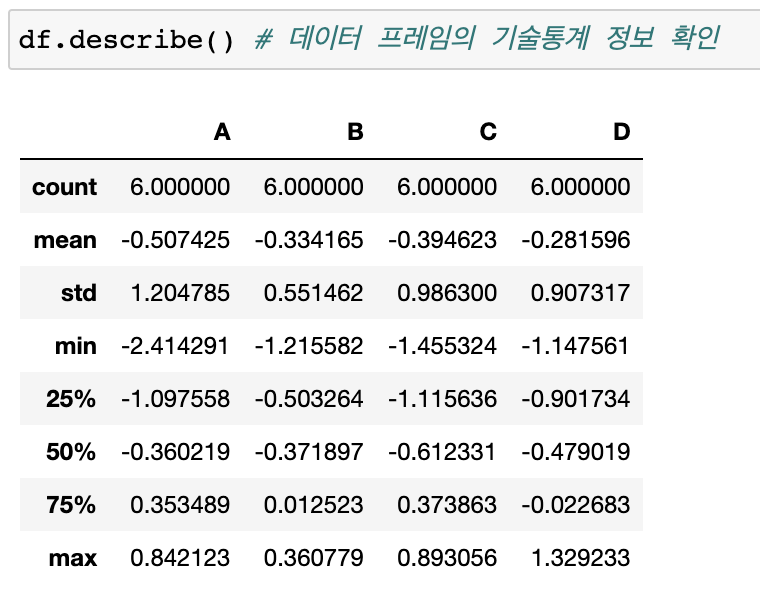
.describe() --> 통계적 기본정보(개요)확인
특정컬럼읽기(slice)
변수명["A"] --> 특정 컬럼만 읽기
변수명[n:m] --> 인덱스의 n부터 m-1까지 보여주기
(인덱스이름으로 범위설정 가능(날짜지정도가능)-이떄는 지정범위의 처음과끝까지 보여지기 가능)
loc 이용 컬럼읽기(slice)
.loc[:, ["A", "B"]] --> :, 모든행의 열 "A","B"컬럼을 선택
.loc["20230606:"20230610", ["A", "B"]] --> 특정컬럼 선택
.loc["20230606, ["A", "B"]] --> 특정컬럼 선택
iloc 이용 컬럼읽기(slice)
.iloc[n] --> 구역x 번호로만 접근 n번째행
.iloc[3:5, 0:2] --> 3~4행, 0~1열
.iloc[[1, 2, 4], [0, 2]] --> (1, 2, 4)행, (0, 2)열
.iloc[:, 1:3] --> 전체행, 1~2열
범위지정 컬럼읽기(slice)
변수명[변수명["A"] > 0] --> "A"열에서 0보다 큰 자료만 선택
변수명[변수명 > 0] --> 전체영역에서 0보다 큰 자료만 선택
파일열기
.read_excel() --> 엑셀파일열기
.read_csv() --> csv파일열기
변경내용적용
inplace = True --> 변경내용적용
rename, 컬럼명변경
columns ={원래 컬럼명 : 바꿀컬럼명}
.rename(columns={변수명.columns[n]:"a"}) --> n번째위치 이름 'a'로 변경
.rename(columns={변수명.columns[n]:"a"}, inplace = True) --> n번째위치 이름 'a'로 변경 변경내용 적용
pandas 언어 사용법 참고 : https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
