AsyMo: Scalable and Efficient Deep-Learning Inference on Asymmetric Mobile CPUs
1 Introduction
On-device DL 연산이 주목받고 있다. 대부분의 on-device 연산에서는 모바일 CPU를 사용한다. AI 가속기가 많이 개발되긴 했지만, 범용성과 프로그래밍 환경, 지원하는 다양한 모델, 성능 등 때문이다. mobile GPU도 널리 사용될 수 있지만, 성능도 비슷하고 많은 모델이 지원되지 않는다.
Issues
하지만, 현재의 on-device 연산은 두 가지 문제가 있다. 첫째로 poor performance scalability on asymmetric multiprocessor(AMP) 이다. 모바일 CPU는 보통 ARM의 bigLittle 기술을 따른다. 좋은 성능의 big-core, 낮은 성능&에너지 소비의 little-core가 따로 있는 구조이다. 근데 현재의 DL framework에서는 DL 연산에서 두 코어 다 사용하면 오히려 시간이 오래 걸린다. DL framework는 가능한 연산력을 잘 활용해야 한다.
둘째로, energy inefficiency because of improper CPU frequency setting 이다. OS는 DL 연산의 특성을 모르니, 가장 최적의 주파수를 찾아낼 수 없다. 단순히 주파수를 높이면 성능은 좋지만 에너지는 그렇지 않다. 그리고 OS의 주파수 조정은 짧게 진행되는 연산에서 반응속도가 별로이다. [5]에서는 DL 모델의 레이어마다 에너지 사용을 측정하는 방식을 제안하지만, 이는 큰 모델에서 쓰기 힘들다.
Root Causes
scalability 문제에 대한 이유를 찾아보았다.
첫째, AMP 코어에서 task 분배가 균형에 맞지 않는다. DL 모델은 특히 행렬 연산(MM)을 많이 한다. 병렬 연산에서, DL framework의 쓰레드는 MM을 더 쪼개고 그 조각을 각 쓰레드에 넘긴다. 이는 round-robin으로 수행된다. 그리고 OS가 각 쓰레드를 AMP 코어에 스케쥴링한다. 하지만 이렇게 하면 (1) big과 little에게 같은 양을 주니 little 입장에서는 더 적은 task를 처리한다. (2) 모바일 환경은 interference-prone[?] 하여 코어별로 배분하는 것이 균형이 맞지 않는다. 그래서 DL framework가 단순히 OS의 스케쥴링에 의존할 게 아니라 비대칭성을 인식하도록 해야 한다.
다른 내부적 원인으로는, task를 조각내는 게 별로라서 그런 것이다. 비대칭성을 고려한 task 분배를 해도 좋은 방식으로 조각내지 않으면 성능 향상이 별로였다. 요샌 서버 CPU의 캐시가 커서 대부분의 MM 데이터를 갖고 있으니 연구가 별로 안 되었지만, 모바일 기기에서는 중요하다. 현재 DL framework에서는 ATLAS에 기반하는데, 작은 행렬은 loop에서 내부의 행렬이고, sub-MM task는 항상 캐시에 있을 수 있다는 기준에 따른다.[?]
Challenges
현재의 조각내기 방법이 풀지 못하는 문제가 네 가지 있다. (1) HW 비대칭성. 현재의 방법은 AMP에서 같은 블록 사이즈를 사용하는데, 이는 성능도 저하시키고 task의 수에 있어서도 fair하지 않다. (2) big, little 코어 사이에 캐시가 나뉘어있는 점. 먼 캐시 접근이 근처 캐시 접근보다 시간이 오래 걸리는데 현재 방식은 이를 신경쓰지 않는다. (3) 작은 캐시에 너무 경쟁한다. (4) Interference-prone 환경.
Our Approach
AsyMo를 소개한다. 기본 철학은 DL 연산이 결정론적이라는 점이다. 모든 연산은 모델에 따라서 결정된다. 그러니 모델 구조와 AMP CPU의 특징을 연결해서 생각하면, task 조각내기와 주파수 결정을 잘 할 수 있다.
scalability를 위해서 cost-model-directed block partitioning과 asymmetry-aware task scheduling을 제안한다. 조각내기는 프로세서 레벨에서 처음으로, 그리고 코어 레벨에서 최소 MM 지연시간을 갖는 task 크기를 나름대로 계산해서 수행된다. scheduling은 각 코에어 적절히 task를 분배하고, 불필요한 데이터 이동을 피하게 할 수 있다. task 크기는 그에 따른 지연 시간에 영향을 주는 여러 요소를 고려하여 cost model을 구성하고, 이를 사용한다. cost model의 parameter는 CPU에서의 특성에 따라 정할 수도 있고, 적당히 empirical하게 정할 수도 있다.
주파수 결정은 DL 모델이 보통의 메모리 intensive한 workload라는 점을 기반으로 하는데, 이는 DL 모델의 데이터 재사용률을 바탕으로 알 수 있다. AsyMo는 대상 CPU의 주파수와 메모리 액세스에 따른 에너지 사용량을 알고 있다. 그래서 DL 모델의 데이터 재사용률을 알면 최적의 주파수만 찾으면 된다.
AsyMo는 쓰레드 풀 레벨에서 구현되었으니, framework와 kernel 레벨에서의 최적화 기법과도 함께 사용할 수 있다.
2 Background
Parallelism in DL inference
inter-op thread pool은 data dependency 없는 연산을 수행할 수 있다. 하나 들어오면, 이를 pre-processing하고, task로 잘게 쪼개서, intra-op thread pool로 보낸다. inter-op thread는 자기가 쪼개서 보낸 task가 모두 돌아올 때까지 기다렸다가 post-processing한다. 이때 intra-op thread를 최적화하고자 한다. 현재는 단순히 같은 양을 각 thread에 할당한다. intra-op pool에 있는 쓰레드 수는 보통 CPU 코어의 수이다. 결국 한 쓰레드는 그냥 한 코어 위에서 OS의 지휘에 따라 실행되는 것이다.
MM partitioning
MM은 CNN과 RNN에 있어 시간적으로 매우 큰 비중을 차지한다. 기존의 partitioning은 같은 크기로만 나눠서 공평하게 나누는 방식이다. 이는 계속 말하지만 AMP에서는 효과적이지 않다.
Mobile AMP and OS DVFS
Single-ISA asymmetric multicore 아키텍쳐는 성능과 에너지 두 가지를 다 잡으려고 고안되어서 지금도 쓰이고 있다. little-core는 주파수도 낮고, 캐시도 작고, 메모리 대역폭도 작고, in-order pipeline에, 파워도 적게 쓴다. 원래는 big&little 각각 캐시를 따로 썼는데, 요샌 DSU 기술 나오고 L3는 같이 쓸 수 있게 되었다.
보통 big과 little의 주파수 설정은 따로 할 수 있다. 그리고 각각 OS DVFS가 현재 workload와 에너지 효율에 따라서 조절한다. 코어마다 주파수 설정은 ARM CPU에서는 아직 지원하지 않는다.
workload 변경에 따라서 주파수도 바꾸는 건 EAS Schedutil 기술이 실제로 적용되면서 잘 된다. 근데 DL 연산이 너무 짧으면 아직도 EAS Schedutil이 바로바로 바꿔주질 못한다. 그래서 AsyMo가 직접 바꿔주도록 했다.
On-device DNN accelerators
AI 가속기가 많이 개발되긴 했지만, 아직 CPU가 on-device 연산에서는 우세이다. 일단 CPU는 어디든 있다. TPU는 그렇지 않다. 다음으로 AI 가속기 생태계가 아직 닫혀있고 미성숙하다. 그리고 특화된 가속기는 다양한 DL 알고리즘을 유연하게 접목시키기 힘들다. 그리고 아직은 그냥 CPU 쓰는 게 성능도 괜찮다. 아키텍쳐도 대부분 비슷하다.
3 Performance evaluation and motivation
지금까지 제시한 문제들 때문에 얼마나 손해를 끼칠까?
3.1 Poor performance scalability on AMP
TensorFlow로 실제로 돌려보니, little-core는 거의 안 쓰더라. 각 코어에서 실행되는 task의 수를 기록해보니, task 분배가 두 단계에 있어 균형잡히지 않았고 이 때문에 CPU 활용도도 낮아진다.
첫 번째 단계는 big/little 프로세서 사이의 불균형이다. little 프로세서에서는 가능한 것 보다 훨씬 적은 수의 task가 돌아간다. 원래는 둘 사이 비율이 1.73정도는 될 수 있는데, 실제 결과에서는 5.63이나 되었다.
OS EAS는 모바일 AMP를 위해 디자인 되긴 했다. 근데 이게 big-core에다가 더 많은 task를 할당한 것이다.
두 번째 단계는 프로세서 사이의 불균형이다. 같은 형태의 코어여도 할당받는 task의 수가 꽤 달랐다. 이는 안드로이드 백그라운드 서비스나 EAS의 잘못된 판단 같은 것들이 간섭해서 그렇다. 이런 불균형은 평균적인 CPU 활용도를 낮춘다. 많은 task를 받은 core가 성능의 bottleneck이 된다.
결국 intra-op thread 스케쥴링의 OS EAS가 별로이고, 이는 각 thread의 workload에 대한 이해 부족 때문이다. 예를 들어, EAS는 thread 안에 같은 크기의 task들이 있고, 이를 코어의 연산 능력에 비례해서 분배되어야 한다는 걸 모른다. 그러니 intra-op thread pool은 task의 정보를 알면서 AMP를 위한 공평한 분배를 수행할 수 있어야 한다.
3.2 DVFS mismatch
EAS Schedutil이 OS랑 통합되었으니, 우리는 이것이 CPU 주파수를 시간에 따라 잘 맞게 설정할 것으로 기대한다. 그래서 해봤다.
그런데 OS가 CPU 주파수를 설정하는 것과 실제 DL 연산이 일어나는 것 사이에는 큰 mismatch가 있었다. DL 시작하고 더 지나서 주파수가 올라가고, DL 끝나고 더 지나서 주파수가 내려간다. 노는 상태에 맞도록 내려가는 건 더욱 한참 뒤이고, 이는 에너지 낭비이다.
더 옛날 기술인 Ondemand를 평가해봤지만 더 별로였다.
유저는 OS가 CPU 주파수를 설정하도록 하지 말고, Userspace에서 workload에 따라 직접 설정할 수 있게 할 수 있다. 이러면 1ms도 안 걸리고 바로 설정할 수 있다. 연산하는 동안 최고 주파수로 설정하면서 에너지 소모도 절반 가량 줄였다.
4 AsyMo system design
4.1 System overview
DL와 mobile AMP CPU의 특성을 모두 활용.
AsyMo의 workflow: 모델이 로드되면 초기화 진행. 초기화에서는 각 MM에서 task로 자를 크기를 결정하고, 데이터 재사용 비율과 프로세서의 에너지-주파수 함수를 바탕으로 최적 주파수를 결정한다. 초기화가 끝나면 각 intra-op thread를 코어 하나에 할당하고, task를 균형있게 분배한다.
AsyMo는 앱의 여러 요구사항을 만족하기 위해 두 가지 모드를 제공한다. 1) latency-first 모드, CPU 주파수는 가능한 최고로 설정한다. 2) energy-first 모드, AsyMo가 계산한 적정 주파수를 사용한다. 둘 다 AsyMo 안 쓰는 것보다 좋다(거의).
4.2 Cost-model-directed block partitioning
Design guidelines
간섭에 약한 환경 때문에 항상 막하는 쓰레드가 있다. 한가한 쓰레드가 바쁜 쓰레드의 task를 가져오더라도 그렇다. 만약 task가 너무 크면 가져오는 게 의미가 없다. 그러므로, task 균형을 맞추려면 task 크기는 최소화되어야 한다.
하지만 task 크기를 줄이면 메모리 접근이 늘어난다. 모든 태스크가 순서 없이 병렬적으로 이루어지기 때문이다. 캐시가 MM에 필요한 모든 데이터를 들고 있을 수 없다면 모든 task가 메모리에서 데이터를 가져와야 하고, 결국 thrashing이 일어난다. 그러므로, task의 크기는 캐시 크기보다는 작게 최대화되어야 한다.
두 조건 사이에서 최적을 찾아야 하는데, 결국 task 크기가 영향을 미치는 모든 영향을 고려해서 MM cost model을 만들었다. 그리고 보통 DL 모델의 input, filter, output 크기 등은 어느 정도의 범위 안에 있으므로 예측하기 좋다. 그리고 각 CPU에 대해서 한 번씩 실제로 돌려보면서 학습한 뒤에, 그 값을 계속 사용하면 된다.
MM cost model
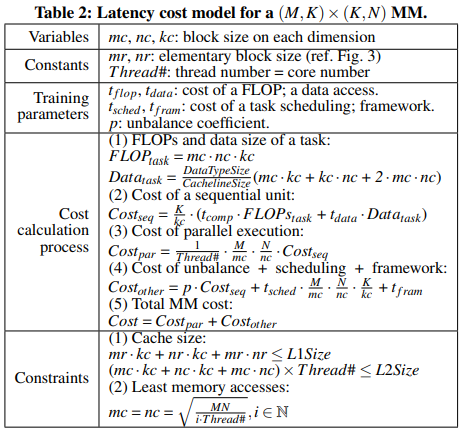
Partitioning for big and little processors
AsyMo는 두 단계로 매트릭스를 나눈다. (1) processor-level, big/little 프로세서마다 적절한 블록 사이즈가 다르므로. (2) core-level, 프로세서 사이의 데이터 이동을 줄일 수 있다.
결국 한 블럭 사이즈는 다른 방식보다 꽤 작은데, 그래서 task stealing을 활용하면 쓰레드 사이에서 적절히 분배할 수 있다.
4.3 Asymmetry-aware scheduling
스케쥴링에 있어 기준은: 1) 각 코어와 프로세서마다 task의 수를 균형있게 해라. 2) 프로세서 사이의 불필요한 데이터 이동을 지양해라.
AsyMo에서는 intra-op 쓰레드=코어 로 묶게 되는데, 이는 AsyMo가 scheduling을 직접 하기 위함임. AsyMo는 task를 현재 가장 작은 queue를 가진 쓰레드에 할당함. 만약 queue가 빈 쓰레드가 있다면 그 쓰레드는 다른 task를 steal함. 근데 big→big, little→big, little→little steal은 되지만 little→big steal은 안 됨. block 크기가 버거울 수 있으므로.
쓰레드 풀에 있는 task는 두 종류가 있다: 데이터 복사하는 task, sub-MM task. 복사.
복사 task는 말 그대로 연속적인 메모리 공간에 데이터를 복사하는 task인데, 그 후에 MM 연산을 시키면 캐시를 잘 활용할 수 있고 성능도 잘 나온다. 이와 같이 AsyMo는 같은 데이터에 대한 복사와 MM을 같은 코어에 할당한다.
4.4 Frequency setting for energy efficiency
AsyMo는, 가장 적은 에너지를 쓰는 주파수가 데이터 재사용률에 의해 결정된다는 것을 활용하여 주파수를 정한다. 그 이유는 아래와 같다.
Design Considerations
workload의 에너지 cost는 static 에너지와 dynamic 에너지의 합으로 계산된다. static 파워는 주파수와 무관하게 일정하게 유지되지만 dynamic 파워는 주파수에 비례한다. 주파수가 증가하면 static 에너지는 감소하지만, dynamic 에너지는 증가한다.
연산집중적인 workload라면 주파수를 올렸을 때 연산을 수행하는 시간이 줄어든다. 그럼 static 에너지도 줄어든다. 하지만 메모리 집중적인 workload라면 주파수를 올린다고 연산 시간이 줄어들지는 않는다. 메모리 접근 시간에 영향이 없기 때문이다. 따라서 메모리 집중적인 workload는 낮은 주파수를 선호한다.
각각 MM(Conv)는 연산집중적, MV(FC)는 메모리 집중적인 worload이다. 다음과 같은 수식으로 데이터 재사용률을 계산할 수 있다.
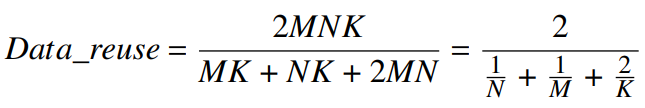
MV는 2를 넘지 못하는데(N or M = 1), MM은 훨씬 크다(20~540 등).
Experimental verification
이 아이디어를 검증하기 위해서 메모리 액세스, 연산에 따른 에너지 곡선을 그려보았다. 그런데 RNN을 돌릴 때, 예상처럼 주파수를 올린다고 성능이 좋아지지는 않다가, 갑자기 1.86Hz 이후에 시간과 에너지가 팍 줄었다. 그래서 아예 메모리 접근 시간을 측정해보았는데, 결과적으로 random memory access 시간 지연은 특정 CPU 주파수를 넘으면 급격히 줄었다.
Frequency setting for othre ops
다른 연산 종류에 대해서도 주파수 설정 기법을 적용해보려 했지만, 현재의 DL 모델은 대부분 Conv와 FC 연산에 집중되어 있다. ReLU나 Softmax같은 것들은 시간이 별로 걸리지 않는다. 그래서 그냥 Conv 와 FC만 고려했다.
5 Cost model training and energy profiling
Cost model training
cost model은 프로세서별로 한 번만 학습시키면 된다. 유명한 VGG-16, MobilNetsV1 모델에서 사용되는 input, filter, feature map 크기를 바탕으로 선형회귀를 통해 cost model을 학습했다. 걸린 시간은 Kirin 970에서 한 시간 내외였다.
Profiling of energy-frequency curves
이거도 CPU별로 한 번만 돌려보면 된다. 다만 이건 완전 HW 문제라서, 이상적으로는 CPU 판매자가 제공해주어야 할 것이다. 여기서는 안드로이드 API를 통해 측정했다. 근데 결과를 보니 little-core의 경우 주파수를 낮추는 게 소모전력을 낮추는 데 별로 도움이 되지 않았다. 최소, 최대 주파수 사이에 7% 밖에 전력 차이가 나지 않았다.
6 Evaluation
6.1 Experimental methodology
Hardware and OS
Hikey970 dev board with Kirin970, Anroid.
AsyMo on Kirin970, Debian.
Google Pixel 3 XL with Snapdragon 845 SoC, Android.
default DVFS is Schedutil.
Framework and model configurations
여러 framework에 적용했다고 한다.
여러 DL 모델을 사용해봄. 근데 굳이 CNN, RNN으로 안 나누고 Conv-dominant와 FC-dominant로 나눔.
1초 간격으로 20번 돌려보고 time과 energy의 평균을 측정함. 첫 연산은 제외함.
Optimized TF baseline
TF baseline을 자기 방법에 맞게 좀 수정했다고 한다.
6.2 Results
MM Results
여러 framework에서 쓰레드 수에 따른 성능 향상이 훨씬 좋아졌다. big, little 모두 utilization이 증가했다. 결국 AMP에서의 성능 scalability를 달성했다.
Model inference results
big, little 각각에서의 실제 DL 돌려본 결과를 보자. TF와 비교해서 시간과 에너지에 있어 매우 좋아졌다. 이는 3.2에서 말했던 이유들을 많이 해소했기 때문이다. 1) AsyMo가 선택한 주파수가 최대 주파수보다 적은 전력을 소모하고, 2) Schedutil에서 연산이 끝나도 계속 있었던 tail을 없앴고, 3) 주파수 상승이 늦어지는 문제를 해결해서 연산 시간을 줄였다.
Performance improvement breakdown
speedup에 각 기술이 기여한 정도를 파악함.
Scheduling: 공평한 스케쥴링과 캐시 지역성 활용. Conv-dominant에 대해 24% 향상. FC-domiant에서는 8 조각으로 나누는 게 적절히 분배하기에 너무 적은 수였다. 약간만 향상시킴.
Block partition: 나머지 24% 향상. cost model이 더 많은 것을 고려하고, 더 잘게 자르면서 스케쥴링도 잘 되고 병렬성도 증가함.
Results on other platforms
다른 경우에서도 성능은 향상되었다.
Debian에서 Android보다 향상이 적었는데, 이는 Debian이 이미 Cont-dominant에 대한 CPU 활용을 잘 하기 때문일 것이다. Debian은 Android보다 백그라운드 서비스가 적다. Android에서는 걔네가 자꾸 방해한다.
Background load interface
백그라운드에 연산과 메모리 부하가 있는 상태에서도 실행해보았다. 이 경우에도 성능 향상이 있었다. 이는 블럭을 더 작게 하여 잘게 자르고, 동적으로 stealing도 하니까 코어끼리 밸런스가 잘 맞았기 때문으로 보인다.
Continuous inference
원래는 1초씩 간격을 주면서 측정했는데, 이번에는 그냥 연달아서 돌려보았다. throttling의 영향이 있을까 해서. 결과적으로는 잘 되었다.
Comparison with other AMP scheduler
범용 AMP scheduler인 WASH를 TF에 적용해보았으나 오히려 baseline보다 성능이 떨어졌다. AsyMo의 적절한 block 조각내기가 아니면 안된다. AsyMo만이 답이다. AsyMo 만세!
7 Related work
다른 기존의 방식들과 비교해도 AsyMo가 좋다는 내용.
