DeepThings: Distributed Adaptive Deep Learning Inference on Resource-Constrained IoT Edge Clusters
I. Introduction
보통 제한된 컴퓨팅 자원을 갖는 IoT 기기에서 DNN/CNN 연산을 직접 하기는 힘들다.
그래서 클라우드 컴퓨팅 기법을 사용한다면? 여러 예측할 수 없는 지연 시간 문제, 개인 정보 문제 등이 있다. 게다가 IoT 기기가 폭발적으로 늘 것으로 예상되어, 이런 중앙화된 클라우드 컴퓨팅으로 데이터를 처리하는 것도 infeasible할 것으로 보인다.
그래서 대안으로 fog/edge 컴퓨팅이 제안되었다. 이는 데이터를 모으는 끝단과 가까운 지점에서 컴퓨팅 자원을 제공하는 방식이다. 하지만 이러한 CNN inference를 효과적으로 분배하고 스케쥴링하는 기법은 아직 적절한 게 나오지 않았다. 현존하는 레이어 기반 partitioning 기법은 중간 데이터를 너무 많이 처리해야 해서 메모리가 감당할 수 없다[?]. 또한, 현존하는 분산 DNN/CNN 엣지 컴퓨팅 제안은 static한 분산 및 분배 기법이라서 IoT 엣지 클러스터가 최적으로 도와줄 수 없다.
그래서 이 논문에서 DeepThings를 제안한다. 이는 locally 분산되고, adaptive하다.
1) Fused Tile Partitioning(FTP) 방식을 제안한다. 이는 각 conv layer를 독립된 task로 나눈다. 이는 레이어 자체를 grid로 나누어서 memory footprint를 최소화한다. 통신 및 task를 가져오는 부하도 줄인다.
2) IoT 클러스터에서 FTP 조각을 각종 상황에 대해 adaptive하게 분배하기 위해 런타임을 steal하는 시스템을 개발한다. 이 방식은 중앙에서 synchronize하는 부하를 피하고, 병렬 처리를 잘 한다.
3) 새로운 스케쥴링, 분배 기법. 인접한 FTP 조각 사이의 겹치는 데이터를 재사용하거나, 성능을 올리기 위함.
결과적으로 infeasible했던 CNN inference를 훨씬 좋은 성능으로 IoT edge cluster에서 각종 상황에 대해 수행했다.
II. Related Work
[9], [10]: 부분적으로 클라우드 서버에 전송하여 처리. 하지만 성능이 매우 예측 불가능하고, 개인정보 문제가 있으며, 레이어 기반으로 나누기 때문에 꽤나 많은 메모리를 차지하게 된다. [?]
[11], [12]: DNN을 직접 edge device(컴퓨팅 자원 제한됨)에 넣어버리려고 saprsification, pruning 기법이 제안되었다.
[13]-[15]: 신경망을 줄이는 압축 기술도 개발되었다.
⇒ 정확도 떨어지는 건 당연하고, 성능 향상도 앱 또는 상황에 매우 의존한다. 그리고 우리는 멀쩡한 신경망을 IoT cluster 속에서의 컴퓨팅 자원 한계에 맞추려고 한다는 점에서 이런 방법과는 orthogonal하다. (그럼 나중에는 둘 다 같이 쓸 수 있는 걸까?)
[16]: 여러 스마트폰을 WLAN으로 묶어서 그 속에 DNN을 넣어보려고 했다. 분배 기법은 MapReduce와 비슷하고, 이것이 동기적으로 CNN inference를 지휘했다. 각 레이어를 조각내서 병렬성은 늘리고 메모리 사용량은 줄였다. 하지만 결국 레이어 단위로 연산되어서 중앙화 되어있고, 동기성도 크게 중요하다. 반면 우리는 레이어를 더 촘촘히 나눠서 통신, 동기화, 메모리 사용량이 훨씬 좋다.
[17]: 레이어 퓨전 기술을 CNN 가속기에 제안함. 근데 이건 하드웨어 연산 수준에서의 병렬성을 위한 것임. 그래서 사이즈 제한이 있고 정적인 분산이 이뤄짐. 우리는 일반적이고 그리드를 동적으로 설정할 수 있다. 병렬성도 task 레벨이다.
[16] 에서도 기존 CNN을 정적으로 나눈다. 연산 관련 자원이 모두 예측 가능하다고 생각한다.
[18] 에서는 동적 로드밸런싱을 위한 work stealing 프레임워크가 제안되었다. 여기서는 비슷하지만 더 경량화된 방식을 제안한다.
III. Background and Motivation
CNN 데이터 처리에서는 convolution 연산이 자원을 제일 잡아먹는다. Fig. 1을 보면 앞 레이어에서 굉장히 큰 visual 데이터가 생겨나고, 이후 뒤로 갈수록 큰 필터를 쓰면서 정보가 압축된다. 출력의 통신 시간도 갈수록 줄어든다. 그래서 통신 시간이 적당히 줄어드는 지점을 edge와 gateway 기기로 나누는 지점으로 사용할 수도 있다. 하지만 이래서는 병렬 처리를 하기 애매하고 의미도 없다.
연산 시간 뿐 아니라 메모리 사용에 있어서도, 초기에는 한 레이어 계산에 70MB나 사용될 만큼 크다. 거의 전체 사용량의 90%나 된다! 그래서 CNN 연산을 IoT 기기 자체에서 하기 힘들다.
그래서 여기에선 초기 단계의 conv layer 연산을 나누고 분배해서 경량화된 채로 수행할 수 있게 한다. 이는 기존 CNN 레이어 스택을 각각 계산할 수 있는 단위로 나누어서 뿌리는 방식이다. 이를 통해서 로드밸런싱도 할 수 있다.
IV. DeepThings Framework
A. Fused Tile Partitioning
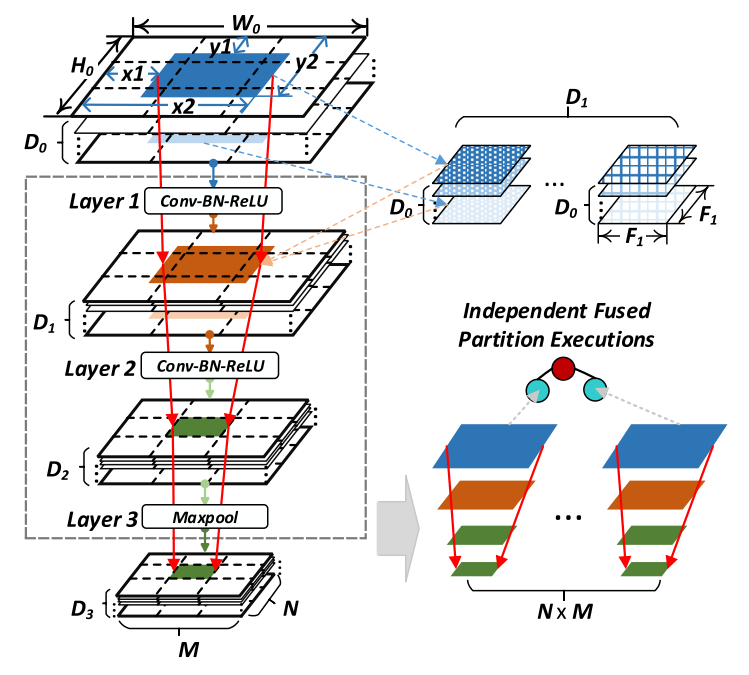
이 그림이 모든 걸 설명한다. 이렇게 쪼갤 수 있다 + 수식으로 정리.
B. Distributed Work Stealing
Idle 한 기기: 주기적으로 Gateway에게 일거리 달라고 요청함
- 일거리가 등록된 게 있다면 Gateway가 어떤 기기인지 알려주고, 노는 기기가 바쁜 기기에게 peer-to-peer로 데이터 받아옴.
- 딱히 없으면 한 주기 쉼.
Busy한 기기: Gateway에 자기 바쁘다고 등록해둠
이를 구현하기 위해서 edge node 런타임과 gateway 런타임을 각각 구현함.
1) Edge Node Service
두 가지 기능이 있음: Work Stealing, CNN Inference
들어오는 데이터는 일단 FTP에 따라서 쪼개짐. 그리고 task queue에 들어감.
CNN Inference Service 에서 Comp.Thread가 gateway에게 내 큐는 비어있지 않다고 등록함. 그리고 task queue에서 계속 일거리를 가져와서 계산을 수행함. 만약 task queue가 비어버리면, comp thread가 나 비었다고 gateway에게 알림. 그리고 steal thread한테 일거리 가져와서 일하라고 말함. steal thread는 gateway에게 어디서 일거리를 훔칠 지 물어봄. 일거리가 없다면 한 주기 쉬고 다시 물어봄. 원래 자기꺼든 훔쳐온 일거리든 처리한 결과는 result queue에 넣음.
Work Stealing Service 안에는 Steal 요청에 응답하기 위해서 Stealing Server Thread가 돌고 있음. 요청이 들어오면 서버 안의 request handler가 자기 task queue 에서 하나 가져와서 응답으로 보냄. Partition Result Collection Thread는 result queue에 있는 모든 결과물을 gateway에 보냄.
2) Gateway Service
얘가 뭘 해야 하느냐? 데이터 모으기, 합치기, 후처리. steal 과정 도와주기.
그래서 두 가지 기능이 있음: Work Stealing Service
Work Stealing Service 안에는 Stealing Server Thread가 있음. 얘는 바쁘다는 애(queue에 뭔가 있다는 애)가 얘기하면 기억해둠. Ring buffer에 바쁜 애 IP 저장하고 포인터는 계속 돌아가면서 고름. round-robin 방식으로 공정하고 균형있게 분배함. [이게 라운드로빈이야?] Partition Result Collection Thread는 일단 edge 노드에서 들어오는 연산 결과 받음. 그리고 result pool에 적절히 집어넣음. 참고: 받은 결과들은 자기들끼리 겹치지는 않음! 그냥 이어붙이기만 하면 됨. result pool에 집어넣을 때 몇 개 모였나 확인해서, 다 모였다면 CNN Inference Service에 있는 Computation Thread가 해당 데이터들 쭉 가져와서 이어붙이고, 나머지 CNN 과정에 그거 가져다가 연산 하라고 보냄.
C. Work Scheduling and Distribution
FTP가 좋긴 한데, 중복된 부분이 존재함. input부터도 나뉜 부분끼리 중복된 부분이 있고, 연산 결과중에도 중복되는 부분이 있음. 그래서 FTP가 메모리 사용량이랑 기기끼리 통신하는 부분은 개선하지만, 오히려 추가적인 연산 부하가 생길 수도 있음. 게다가 그런 중복 데이터와 불필요 연산 등의 부하는 나누는 게 많아질수록 극대화됨. 그래서 이를 해결하기 위해 스케쥴링과 분산 최적화 기법을 소개한다.
1) Overlapped Data Reuse
인접한 조각에서 동일하게 사용되는 데이터 혹은 연산 결과를 캐싱한다. 캐싱된 데이터를 사용할 수 있다면 나머지 부분에 대해서만 연산을 진행하면 된다. 이러면 데이터 전달과 연산에 필요한 자원이 줄어든다.
하지만 이렇게 하면 조각 사이에 의존성이 생기고, 이는 병렬성을 제한한다. 직접적인 해결 방법은 레이어 하나를 계산하고 나면 그 결과를 다른 기기에 전달하는 것이다. 하지만 계산 결과를 받는 레이어는 레이어 단위로 동기화되어야 한다. 이는 성능에 제한을 준다.
그래서 병렬화도 하면서 데이터 재사용도 하고 동기화 부하도 줄이기 위해서, 새로운 스케쥴링 기법을 선보인다.
2) Partition Scheduling
겹치는 부분이 다 계산되고 나면 바로 다른 조각을 넘길 건데, 조각을 계산하는 순서를 잘 조정하면 이득이 많다.
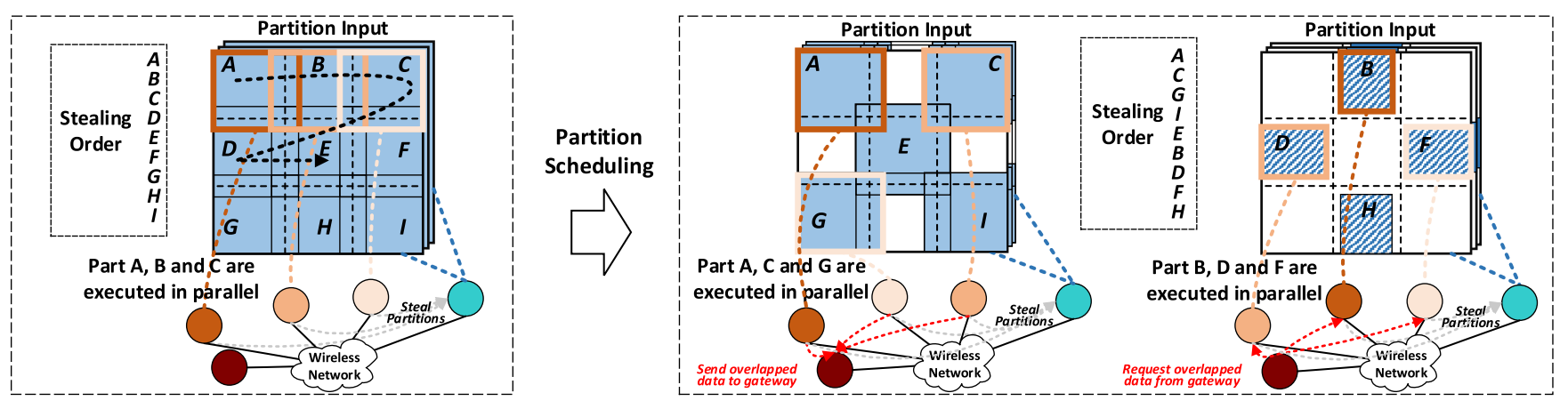
최대한 안 겹치면서 병렬적으로 잘 처리할 수 있게, A, C, E, G, I 를 먼저 연산하고, 그 결과를 십분 활용해서 B, D, F, H 를 계산한다.
그래서 DeepThings에서는 local & steal 두 경우 모두 의존성 순서대로 연산하게 한다. 중복 부분의 데이터를 잘 공유하기 위해서 gateway가 겹치는 부분의 데이터를 다 모으고 관리한다. 연산 과정에서, IoT edge 노드는 input 데이터를 peer에게서 받으면서 겹치는 부분은 gateway에게서 받는다. 이후 계산은 자기가 알아서 한다. 만약 gateway한테 겹치는 부분을 요청했는데 아직 없다고 하면, 그냥 자기가 계산한다. 만약 인접한 조각이 같은 기기에서 연산된다면 locally 겹치는 데이터를 저장하고, 써먹을 수 있다. 이 경우 gateway와 통신하는 부하가 없어진다.
이런 동작 수행을 위해 gateway 기기에서 재사용 데이터를 모으고 내보내는 기능이 있어야 한다. 기존의 Stealing Server Thread가 해당 기능을 같이 수행한다. edge node에서도 fetcher가 추가되어 연산 전에 겹치는 부분의 데이터를 gateway에 요청한다.
3) Overlapped Region Computation
이런 스케쥴링 기법을 적용하기 위해서 각 FTP 조각은 어떤 부분이 어떤 조각과 겹쳐지는지 레이어별로 기록해두어야 한다. 이를 계산하기 위해 Algorithm 1을 겹치는 부분, 겹치지 않는 부분을 모두 계산하도록 확장시켰다. 이러한 겹치는 부분에 대한 재사용은 input 크기를 줄이고, 겹치는 부분의 연산을 줄일 수 있지만, 그런 부분의 통신에 대한 부하는 새로 발생한다.
V. Experimental Results
실제로 C/C++로, TCP/IP와 socket API를 활용하여 오픈소스로 구현함. YOLOv2 인공신경망에 대해 실험했고, Darknet 라이브러리를 사용함. 이와 함께 NNPACK을 백엔드 가속 커널로 사용했다고 함. RPi3 로 edge node 6개, gateway 1개 구현함. edge node로 쓰인 RPi3는 싱글코어로 제한함. YOLOv2의 처음 16개 레이어에 대해 분산&분배 방식을 구현함.
비교 대상은 [16]에서 나온 MoDNN framework임. 이는 Biased One-Dimensional Partition(BODP) 방식이고, 한 레이어 안에서 조각내고 공평하게 분배하는 방식(work sharing, WSH)임.
그래서 WSH과 WST(work stealing) 비교, FTP, data reuse 등을 실험함. 결과적으로 가장 큰 장점은 여러 동적인 데이터 소스 환경에서의 throughput 개선이었다.
A. Memory Footprint
메모리 사용량에 대해 각 방식들을 비교해 보았다. 공통점은 conv layer를 조각내는 것은 input/output 데이터의 메모리 사용량만 개선했고, weight에 대해서는 그대로였다. 결국 한 기기에서의 메모리 사용량은 가장 큰 레이어 이하, 전체 weight 이상이다.
원래의 CNN 모델과 비교하면, 전체 메모리 사용량은 BODP-4는 61%, FTP-3x3은 58%, FTP-5x5는 68% 줄었다. 결과적으로, 조각을 많이 낼 수록 기기당 메모리 사용량이 줄긴 하지만 FTP에서 BODP보다 더 많이 조각내면 겹치는 부분들 때문에 오히려 메모리 사용량이 약간 증가하게 된다.
각 레이어에서의 평균 메모리 사용량 감소를 비교하면, BODP-4는 67% 줄였는데 FTP-3x3은 69%, FTP-5x5는 79% 줄였다. 특히 처음 7개 레이어에서는 FTP-3x3은 BODP-4보다 7% 많은 메모리를 쓴다. 하지만 뒤로 갈 수록 겹치는 부분은 줄어든다.
BODP와 FTP는 둘 다 괜찮게 메모리를 절약한다. 근데 FTP는 겹치는 부분 때문에 메모리를 조금 더 사용하긴 한다. 하지만, 조각내기 parameter가 통신 부하, 지연시간, throughput에 영향을 미친다. BODP와 MR 기반 모델은 기기 수에 맞게 조각내는 게 최선인데… 이 점을 기억해라. 두고보자.
[졌잘싸 느낌인데?]
B. Communication Overhead
통신 부하는 분산, 분배 기법 모두에 영향을 받는다. FTP에서는 input/output 데이터만 통신을 통해 전송된다. 따라서 전체 통신 용량은 모든 조각의 input/output 크기의 합 아래이다. 중복 부분 데이터는 추가적인 통신을 요하고, 잘게 조각을 자를 수록 이 점이 늘어날 것이다. 반면, BODP-MR 기반 모델은 중앙화된 스케쥴러가 각 레이어가 연산되고 나서 중복 부분을 처리한다. [레이어별로 조각낼 거면 output에 중복 부분이 있긴 한가?] 이 때는 통신 부하가 기기 수에 비례해서 증가할 것이다. 그리고 중간의 feature map은 input보다 큰 depth를 가지기도 하므로, BODP-MR은 중복 부분에 대한 부하는 없겠지만 기기 수가 5개가 넘어가면 통신 부하가 FTP보다 커진다.
우선 동일한 WSH 분배 기법을 사용하여 MoDNN과 FTP를 비교하였다. 평균으로는 MoDNN은 14.0MB의 데이터를 통신했지만, 기기 수가 6에 달하자 19.6MB까지 찍었다. FTP는 3x3, 4x4, 5x5에 따라 13.8MB, 16.2MB, 18.9MB로 기기 수와 무관하게 동일했다. 결과적으로 FTP는 scalability에 있어 유리했지만, 오히려 기기 수가 적으면 별로였다.
FTP의 중요한 점 하나는 각 독립된 조각을 분배하는 방식 선택이 자유롭다는 점이다. 그래서 FTP에 WSH와 WST 둘 다 적용해보았다. 실험 결과 WST는 통신 부하를 평균 52% 정도로 낮추면서 scalability도 더 좋았다. WST에서는 중앙화 없이 알아서 데이터가 이동하고, locally 많은 일이 일어난다.
데이터 재사용 기법은 통신 부하를 늘렸는데, intermediate feature map 데이터가 오고 갔기 때문이다. FTP-WST-S 에서는 계산이 끝나면 항상 중복 부분을 넘겨준다. 그래서 FTP-WST-S는 항상 FTP-WST보다 부하가 크다. 하지만 그런 부하는 input에서 재사용 첫 레이어까지를 줄여서 줄일 수 있다.[?] 결과적으로, FTP-WST-S는 더 잘게 조각낼수록 재사용 가능성이 높아지므로 통신 부하가 줄어든다. 3x3보다 5x5 경우가 FTP-WST에서 늘어난 메모리 사용량이 적다(각각 1.4MB, 0.9MB).
C. Latency and Throughput
분배 기법에 있어서는 WST가 보통 지연 시간이 짧다. FTP-WSH 와 FTP-WST를 비교하면 평균 10.3% 줄어든다. 다만 scalability는 분산/분배 기법 모두가 영향을 끼치는데, MoDNN에서는 통신 부하 때문에 기기 4개에서 최소를 찍고 그 이후 증가한다. FTP-WST와 FTP-WST-S에서는 적절히 통신 대역을 탐색할 수 있다. 그러면 모든 기기를 쓰지 않게 될 수도 있다.
더 잘게 조각내면 병렬 연산에는 좋지만, 겹치는 부분과 잉여 연산/통신이 발생한다. 3x3 에서 5x5 로 바꾸면 지연 시간이 평균 43% 증가한다. 겹치는 부분 때문에. 그래서 FTP-WST-S를 도입하면 FTP-WST와 비교해서 지연 시간이 27% 이상 줄어든다. 더 잘게 조각낼수록 데이터 재사용을 더 잘 할 수 있고, 실제로 FTP-WST-S는 3x3에서는 16% 개선시켰지만 5x5에서는 33% 개선시켰다.
결과적으로, DeepThings는 scalability에서는 비슷했지만 통신과 연산에서는 더 부하가 컸다. edge 기기 하나만 있을 땐 FTP-WST-S가 25% 큰 지연 시간을 가졌다. 하지만 기기가 늘어날수록, 지연 시간은 MoDNN과 비슷하거나 그 이하였다.
더 실제적인 상황에서 평가해보고자 최대 소요 시간과 전체 throughput을 여러 dataset, 고정된 기기 수로 평가해보았다. WSH는 항상 edge에 일을 똑같이 시켰고, 들어오는 데이터들은 순차적으로 실행시켰다. 결국 병렬성은 하나의 data frame에 대해서만 가질 수 있었다. WST은 바쁜 기기는 일 안 시키고 노는 애들만 일 하게 되었다. 그래서 병렬성과 여러 데이터 처리에 있어 좋았다.
최대 지연 시간과 throughput에 있어서도 확인해보았다. 일반적으로 성능은 분배 방식에 의해 결정되었다. WSH의 지연시간은 데이터가 많을 수록 선형적으로 늘어났다. 하지만 WST는 최대 지연 시간이 조금씩만 늘어났고, 기기 하나의 지연 시간보다는 짧았다. 중앙화되고 순차적으로 처리하는 WSH는 여러 data frame이 있어도 throughput이 좋아지지 않았다. FTP-WSH도 비슷했다. 하지만 WST에서는 데이터가 많아질수록 throughput이 증가했다.
D. Sensitivity Analysis of FTP Parameters
잘게 자르는 것과 더 많은 레이어를 사용하는 것은 성능을 더 올리지만 메모리 사용량을 늘리고 통신 부하를 늘린다. 하지만 잘게 자르는 것은 병렬성을 더 준다. 그래서 통신 대역폭이 충분하다면 잘게 자르는 것이 scalability와 분배에 있어 유리할 것이다.
VI. Conclusion
이후 연구할 만 한 주제: 동적이고 heterogeneous[?]한 분산 기법, locality를 고려한 스케쥴링, 에너지 효율 최적화, 크고 heterogeneous한 IoT 클러스터에서의 평가.
