CoDL: Efficient CPU-GPU Co-execution for Deep Learning Inference on Mobile Devices
1 Introduction
DL의 on-device 연산이 각광받고 있다. 하지만 간단한 모델에만 좋다. 다른 종류의 프로세서를 병렬적으로 사용하게 하면 좋을까? 그렇다. 1) 서버 GPU는 큰 규모일수록 CPU보다 연산을 빨리 하지만, 모바일에서는 둘이 성능이 비슷하다. 2) 모바일 환경에서는 CPU와 GPU가 메모리를 같이 쓴다.
하지만 지금 framework는 한 프로세서만 쓴다. 두 가지 문제가 있기 때문이다. 첫째는 data sharing 부하의 문제이다. 공유되는 데이터의 coherence 가 문제가 된다. 한 프로세서에서 연산한 결과가 나머지에도 공유가 되어야 하고, 결국 동기화나 맵핑, 타입 문제가 발생한다. 둘째로, 두 프로세서로 어떻게 분배하는가가 문제이다. online 방식은 불가능하다. 가볍고 정확하면서, 다른 모든 영향들도 고려하는 latency 예측 방법이 필요하다.
현재 존재하는 framework들 중에 CPU+GPU 연산을 지원하는 것들도 있지만, 위 문제를 잘 해결하지는 못했다.
이를 해결하기 위한 핵심 발견 두 가지가 있다. 첫째, 프로세서마다 성능이 잘 나오는 데이터 타입이 다르다. 둘째, latency 예측기를 정확하고 가볍게 만들려면, 순수한 black-box learning 방식이 아닌 환경에 대한 특성을 모델이 알고 있어야 한다.
그래서 두 가지 기술을 만들었다. 첫째, Hybrid-type-friendly data sharing이다. 이는 각 프로세서가 자기에게 좋은 타입의 데이터를 쓰도록 해준다. 그리고 data sharing 부하를 줄이기 위해, hybrid-dimension partitioning 과 operator chain 방식을 제안한다. 전자는 분산시키는 차원을 operator shape에 따라 다르게 결정하는 것이다. 후자는 한 chain에 있는 연산은 무조건 local data를 바탕으로 하고, data share는 필요하지 않도록 하는 것이다.
둘째, Non-linearity-and concurrency-aware latency prediction이다. 다른 방식에서는 latency의 비선형적 특징을 잘 반영하고자 너무 복잡해졌다. 그래서 여기서는 선형 모델만 쓰고, 모든 부하를 고려한다.
이후 CoDL 자랑을… 벌써부터…
2 Motivation and analysis
일단 기존의 방식을 확인함. MACE에서 CPU+GPU 방식으로 한 게 CPU, GPU 하나만 쓴 것보다 느렸다.
동일한 데이터 타입은 다른 종류의 프로세서 동시 사용에 비효율
buffer 타입은 CPU, GPU 모두에게 지원되어서 기존 uLayer에서 이거만 쓴다. 이거는 연속된 주소로 된 chunk로 데이터를 저장한다. 근데 Adreno GPU에서는 image 타입이 더 효율적이다. Image 타입은 멀티디멘션 chunk로 데이터를 저장한다. 이는 렌더링을 효율적으로 하기 위해, L1 캐시 접근을 쉽게 하기 위함이다.
Data sharing overhead는 무시할 게 아니다, 특히 작은 operator에서는
CPU+GPU 연산을 하려면 다음과 같은 과정이 필요하다.
GPU에서 나온 연산 결과가 있다. 이를 다음 레이어에 통과시키려면
1) Data transformaion. 타입을 바꿔야 한다면.
2) Data mapping. 데이터 일부를 CPU 메모리 영역에 매핑.
3) Synchronization. 서로 상태에 대한 통신.
4) Data unmapping. CPU 메모리 영역에서 매핑 해제.
특히 연산 과정이 짧을수록 이런 과정이 비중이 커진다. 실제로 해봐도 그렇더라. 그러므로 이런 부하를 줄이면서도, CPU+GPU를 같이 쓰는 게 이득일 때만 그렇게 하는 게 좋다.
균형잡힌 조각내기를 위해서는 가볍고 정확한 latency 예측기가 필요하다
현재 방식은 가벼운 모델로 예측한다. 이는 online 예측에 사용하기 좋다. 하지만 너무 부정확하다.
이는 결국 균형잡히지 않은 분배와 성능 하락으로 이어진다. 실제로 uLayer의 FLOP 기반 방식으로 하니 최적의 경우보다 4배나 느렸다. 실제 latency는 플랫폼 특성에 굉장히 많은 영향을 받는다. 그래서 정확도에 집중한 예측 모델도 있지만, 너무 무거워서 모바일 환경에서 쓸 수 없다.
따라서 둘 다 만족해야 한다. 가볍고, 정확해야 한다.
3 CoDL overview
디자인 원칙: 1) 각 프로세서의 성능을 최대로 활용해야 한다. 2) data sharing 등의 기타 부하를 최소화시켜야 한다. 3) 분배와 밸런싱을 최적으로 잘 해야 한다.
CoDL은 두 단계로 구성된다. 첫째로 offline phase이다. 이는 선형회귀 모델로 여러 요소를 반영하여 매우 간단한 수식으로 latency 예측 모델을 구성한다.
둘째로 online phase이다. 이는 두 모듈로 나뉜다. 한 모듈은 operator partitioner이다. 예측 결과를 바탕으로 두 기술을 사용하는데, 차원 분산 결정과 operator chain이다. 이후 모델의 weight를 GPU와 CPU에 쭉 뿌린다.
다른 모듈은 operator co-executer이다. 앞서 생성된 계획과 weight들의 주소를 받아서, 각 프로세서에 유리한 타입으로 변환시키고 연산을 시킨다. 마지막으로 모든 output을 합친다.
4 Hybrid-type friendly data sharing
4.1 Hybrid-dimension partitioning
Performance impact analysis
tensor를 나누는 것은 ouptut channel을 따라서도 할 수 있고, height를 따라서도 할 수 있다. 근데 data sharing은 feature map에서만 고려하게 된다. weight는 항상 그대로이니 각 모델에 뿌리고 나면 상관이 없다.
그래서 height 차원을 따라서 나누는 것이 data sharing 부하에 있어서는 유리하다. OC를 따라 나누게 되면 모든 feature map을 CPU와 GPU에 보내야 한다.
다음으로, 나누는 차원은 프로세서 활용에도 영향이 있다. H를 따라 나누는 것이 data sharing 부하는 적지만, 그렇다고 꼭 빠르다는 것은 아니다. 실제로 input이 작고 output channel이 큰 경우 OC를 따라 나누는 게 좋았다. 프로세서의 병렬성을 높이려면 tensor가 쪼개져서 다른 core에 분배되면 된다. 한 코어 안의 ALU 활용을 늘리려면, warp가 여러 쓰레드에 대해 같은 연산을 수행하므로 warp를 모두 채울만 한 쓰레드를 제공해야 한다. hieght, width가 작으면 그러지 못하여 GPU 활용도가 떨어진다.
마지막으로, 나누는 차원은 데이터 접근 부하에도 영향을 준다. 보통 붙어있는 데이터를 받는 것이 연산에 편리한데, 그래서 [H, W, IC] 형태로 데이터가 있다면 H를 바탕으로 나누는 것이 더 유리하다.
Determining the partitioning dimension
실제 수행시에는 predictor에 여러 데이터를 집어넣고서, 분배 비율을 계속 다르게 하여 넣어보면서 최적의 비율과 차원을 찾을 수 있다.
4.2 Operator chain
각 operator 이후에 계속해서 data sharing 하지 않고, chain 단위로 나눠서 계산하게 한다. [완전 DeepThings 방식인데?]
Performance impact analysis
operator chain을 잘못 지정하면 성능에 해가 된다. 두 가지 이유가 있는데, 첫째로 조각내는 비율이 이상적이지 않을 수 있다. 둘째로 chain이 길어질수록 padding이 늘어나서 잉여 연산이 늘어난다. 실제로 YOLO 모델에서 확인해보니 chain 길이가 9가 되면 연산으로 인한 latency가 늘어나서 오히려 성능이 나빠진다.
Chain searching algorithm
그래서 최적의 chain 구조를 찾으려고 알고리즘을 하나 만들었다. greedy-like이다. 이 알고리즘의 input은 chain이 없을 때의 최적의 partitioning 방법이다. output은 전체 latency를 최소로 만드는 chain들의 집합이다. 알고리즘 내용은 input의 처음부터 시작하면서 chain을 하나 만들고, partitioning ratio를 조금씩 바꿔가면서 다음 operation을 chain에 추가해본다. 그러면서 max인 chain을 기록하고 저장하는 방식이다.
5 Non-linearity-and concurrency-aware latency prediction
가볍고 정확한 latency 예측기가 필요하다는 말은 많이 했는데, 그래서 어떻게 구현하는가?
1) data-sharing overhead를 전부 포함시킨다.
2) 비선형적 latency를 해석적으로 수식화한다.
5.1 Latency composition of concurrency
실제 측정을 진행해보니 mapping, synchronization, data transformation이 주요하게 latency에 기여했다.
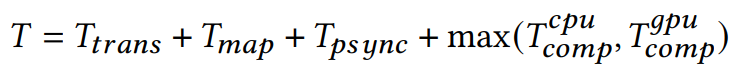
여기서 Ttrans와 Tmap은 data 크기에 따라 선형적으로 증가했다. Tpsync는 매우 변수가 많아서 upper bound인 1ms로 사용했다.
5.2 Non-linearity-extracted computing latency prediction
왜 non-linearity를 갖는지를 분석했다.
첫째, 다른 알고리즘을 사용한다. 3x3, 5x5 conv에 대해 다른 방식을 쓴다.
둘째, 다른 level에 대한 data blocking이 계단 형태의 latency response를 보여준다. GPU에서는 inter-core에서 workgroup과 warp, intra-core에서 병렬성으로 두 단계로 나뉜다. CPU에서도 비슷하게 데이터를 블럭으로 나눠서 병렬적으로 돌리는데, 여기서도 SIMD(single instruction multiple data) unit을 사용하려고 뭔가 한다.
Formulating non-linearity
위의 분석을 바탕으로 kernel 연산에 대한 non-linearity를 수식화해보았다. 대략적인 형태는 아래와 같고, 각기 다른 알고리즘에 대해 여러 복잡한 수식을 만들었다.
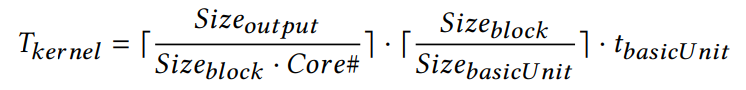
여기서 t_basicUnit 이 유일한 learned variable이다. 그리고 non-linearity가 다 제거되어 이 variable은 linear하다. 배우기도, 써먹기도 매우 쉽다.
결국 5.1에서 나온 식에서 Tcomp는 위 Tkernel의 합이 된다.
6 Implementation
MACE에 CoDL의 핵심 기능을 심었다. 그리고 해당 CoDL 기능은 컴파일해서 library로 제공한다. 즉 다른 framework에 가져다 쓰기 쉽다.
데이터 타입 관련해서는 OpenCL을 가져다 썼다.
latency 예측기는 다변수 선형회귀 모델을 썼다.
많은 샘플을 가져다가 학습시켰다.
7 Evaluation
7.1 Experiment setup
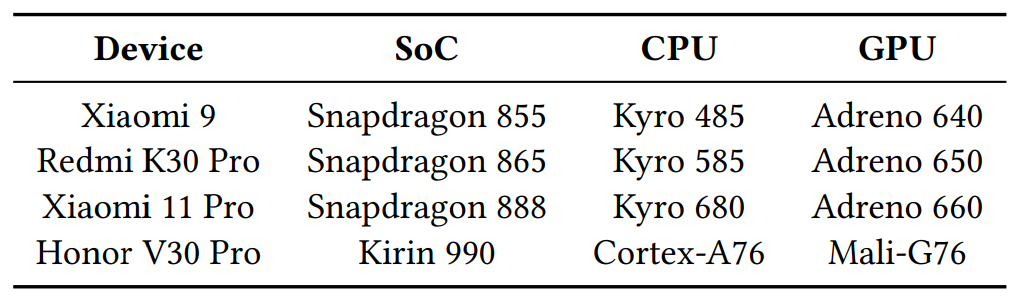
Platforms
Models
유명한 모델 다섯 개 사용함. 레이어 수 다양함. float32, 50번 돌려서 평균.
Baselines
1) uLayer-like 2) single processor i.e. MACE 3) theoretical performance upper bound
7.2 Overall performance
Snapdragon 환경: uLayer과 비교했을 때 평균 3.43x speedup. 주요한 이유로는 1) HW에 유리한 데이터 타입 사용. 2) data sharing 부하를 줄이는 기술들 3) latency 예측 잘 해서 밸런스 잘 맞춤. MACE와 비교해도 평균 1.56x speedup. 거의 optimal에 근접하기도 함.
Kirin 990 (with Mali GPU): GPU가 L1캐시가 있어서 buffer type이 더 유리함. uLayer와 비교했을 때 평균 1.49x speedup. 이유는 1) 데이터 맵핑&동기화 부하 줄음 2) 밸런스 잘 함. MACE와 비교했을 때 CPU only 2.43x, GPU only 1.41x 성능 향상.
7.3 Performance of the hybrid-dimension partitioning
각 기술이 성능 향상에 기여하는 비율 확인하기.
우선 operator chain 없이 hybrid-dimension partitioning 확인. 대부분 height를 자름. 끝으로 갈 수록 OC를 자르는 경향도 있음. 보통 위 레이어의 feature map이 크기가 크기 때문에 height로 자르는 게 data sharing 에 유리하다.
hybrid-dimension partitioning 의 유무에 따른 latency 변화도 비교해보았다. 평균 1.2x speedup. 큰 모델에 대해서 성능 향상이 두드러졌다.
7.4 Performance of the operator chain
실제로 묶인 chain의 예시 보여줌. 평균적으로 72% 이상의 operator가 chain으로 묶였다. chain 유무에 따른 성능 차이를 보아도, 평균적으로 55%를 줄인다.
7.5 Performance of the latency predictor
FLOPs-based predictor를 baseline으로 둔다. 이는 FLOP 기반으로 linear 모델을 쓴다. 근데 이거 정확도가 8.95% 밖에 안 된다. CoDL은 평균 84.03%, 85.17%, 82.96% 정확도를 보인다. 게다가 이건 기존의 무거운 blackbox predictor 성능에 근접한다.
또한 보통의 DL 커널에 대해서도 평가해보았다. 매우 높은 성능. 학습을 위한 샘플을 모으는 데도 1.5시간 정도밖에 걸리지 않았다. training은 1~2초밖에 걸리지 않았다.
7.6 System overhead
소비전력과 에너지 사용, 메모리 사용을 살펴보자.
아무래도 프로세서 둘 다 쓰니까 소모전력은 꽤 늘어난다. 데이터 타입도 HW friendly 하게 바꾸니까 HW 사용도 늘어나고, 소비전력도 늘어난다. 다만 시간이 줄어드니까 총 에너지 사용량은 소비전력만큼 늘진 않았다. 그래도 늘긴 늘었다.
메모리 사용에 있어서는 co-execution을 하려다 보니 메모리는 더 먹는다.
8 Discussion
Generality of CoDL
지금은 MACE에만 적용시켜봤지만, 다른 framework에도 적용할 수 있다. 데이터타입도 GPU에서 자주 쓰이는 방식을 살펴보고 동적으로 선택할 수 있다. 새로운 DL 모델에 대해서도, operator만 CoDL이 지원하는 것이라면 바로 predictor를 사용할 수 있다. 만약 지원하지 않는 operation이 있다면 추가적인 profiling이 필요하다.
Limitation and future work
CoDL에는 주요하게 두 가지 한계가 있다. 첫째, 두 프로세서를 다 쓰기에 하나만 쓰는 것 보다 소모전력이 더 크다. 그래서 predictor가 전력 사용도 예측하고 성능과 함께 고려할 수 있도록 할 필요가 있다. 둘째, 가벼운 DL 모델에 대해서는 성능 향상이 별로 이루어지지 않는다. 애초에 줄일 시간이 작아서 data sharing 부하가 쉽게 커져버린다.
이후의 작업으로는, 더 다양한 workload에 적용하기 위해서 predictor를 CPU, GPU 사용 비율에 따라 예측을 조정하도록 할 예정이다. 그러면 조각내는 게 더 유연해질 수 있다. 다만 이것이 꽤 어려운 문제인 게, 백그라운드 환경에서 스케쥴링과 경쟁이 복잡하다. [?]
Extended discussion
이 CoDL 방법은 CPU, GPU 하드웨어가 메모리를 공유하도록 설계되었기 때문에 가능했다. 하지만 현재 data sharing이 overhead인데, 하드웨어 level에서 data transformer까지 넣어준다면 이 overhead를 줄이는 데 큰 도움이 될 것이다. 그리고 OpenCL 구현이 더 잘 되었으면 동기화 overhead가 나아질 것이다.
9 Related work
기존 방식들을 소개하며 CoDL이 더 좋다는 말들.
영향을 받은 논문들, 그리고 같이 쓸 수 있다는 희망, 거기서 더 나아간 점들.
10 Conclusion
요약

operator 용어 의 의미를 잘 모르겠네요..;