본 포스트는 LG Aimers 활동에 참여하며 온라인 AI 교육을 정리한 내용입니다!
프로그램에 관심이 있으시다면 https://www.lgaimers.ai/ 를 참고해주세요!!
Linear Classification
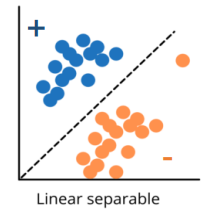
- 모델의 출력이 discrete한 값을 가진다.
- 구성된 linear model은 입력 feature에서 coordinate에서 hyper plane으로 사용하게 된다.
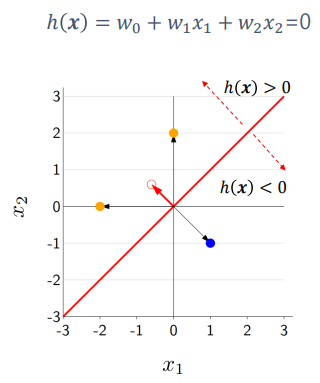
- hyper plane은 h(x) = 0 인 방정식을 가지게 된다.
- 단순하며 해석 가능성이 있고, 일반적으로 안정적인 성능을 보인다.
- 에서 d차원의 공간에 입력 feature vector가 있는 것이다.
- binary classification : yes/no
- 간단하고 해석 가능성이 높다.
Linear classification model
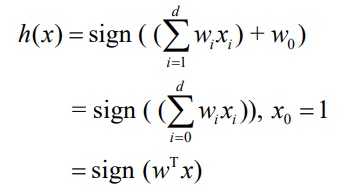
- 입력 변수와 parameter의 곱으로 score를 계산
- score를 계산한 뒤 sign 함수를 적용한다.
- sign(x)
- if x > 0 : 1
- if x < 0 : -1
Score and margin
score
- 결정 과정에서 model이 얼마나 confident한 지 측정 가능
margin
- score에 y값을 곱하여 계산
- 서로 같은 부호의 값을 곱하면 positive의 값을 가지게 될 것이고, 서로 다른 값을 곱하면 negative의 값을 가지게 된다.
- 이러한 방식으로 정답이 맞는지를 판별할 수 있다.
Zero-one loss
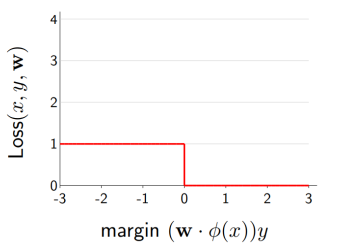
- 답이면 0, 아니면 1인 loss function
- 함수를 미분하였을 때 값이 0이 되는 문제가 있다.
Hinge loss
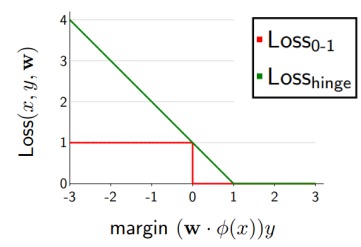
- 1-margin과 0 중 큰 값을 선택하게 된다.
- margin이 positive값, 즉 정답이라면 loss가 0이 된다.
- margin이 negative값, 즉 오답이라면 loss가 커지게 된다.
Cross-entropy loss
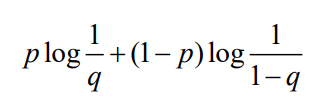
- classification에서 가장 많이 사용하는 loss function
- 두 개의 서로 다른 pmf를 가지는 확률 함수 사이에 서로 다른 정도를 표현하는 K-L divergence에 의해 표현된다.
- 계산한 model의 score 값은 실수 값인 반면 cross-entropy 값은 확률 값을 서로 비교하는 값이다.
Mapping
- score 값을 classification하기 위해 mapping을 해야한다.
- 이 때 sigmoid 함수를 이용하여 mapping을 진행한다.
Sigmoid
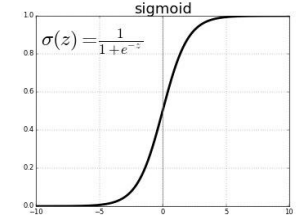
- score값을 sigmoid 함수에 대입하면 (0,1) 범위의 값으로 변환할 수 있다.
Multiclass Classification
- n 차원 coordinate 상의 signal space에서 입력 feature를 plotting한 다음 해당 feature들을 적절하게 구분할 수 있는 hyper plane을 찾아야한다.
One-VS-All
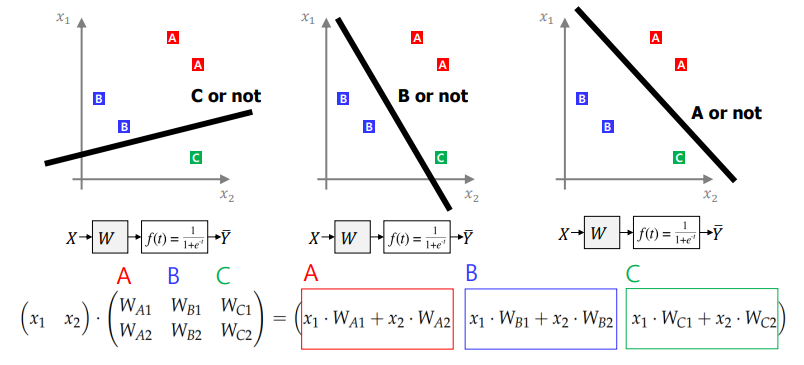
- binary classification을 이용하여 multiclass classification을 수행한다.
- 각 label을 위한 model parameter들을 내적 연산을 하여 score값을 얻을 수 있게 된다.
One Hot Encoding
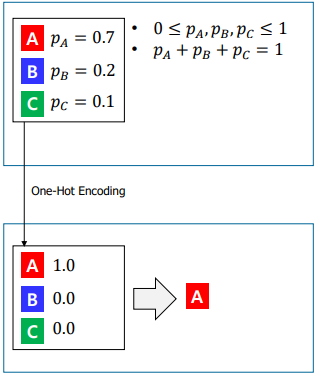
- 두 개의 서로 다른 표 사이에 거리를 가깝게 하면서 학습
- label을 지정하는 문제에서 각 vector마다 해당하는 위치에 1을 signaling을 함으로써 label의 정보를 기록한다.

안녕하세요 :) Data/AI 공부 중인 한국외대 컴퓨터공학부 조권휘입니다.