본 포스트는 LG Aimers 활동에 참여하며 온라인 AI 교육을 정리한 내용입니다!
프로그램에 관심이 있으시다면 https://www.lgaimers.ai/ 를 참고해주세요!!
Gradient
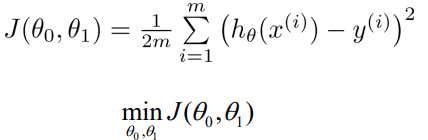
- 손실함수에서 파라미터인 을 최소로 하는 값을 찾도록 한다.
- 값을 지속적으로 변화시켜 최소로 만든다.
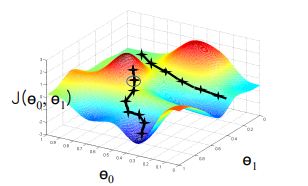
Gradient
- vector function의 partial derivative term을 가진다.
- 변화량이 가장 큰 방향으로 update한다.
Step size()
- parameter update의 변화 정도를 조절한다.
- 학습 이전에 설정하는 hyperparameter
- 값이 작다면 수렴형태가 안정적으로 수렴한다. 하지만 수렴하는 속도가 느려진다.
- 값이 크다면 overshoot이 발생하여 수렴하지 않고 발산하는 형태가 된다. 즉, error의 loss가 늘어나게 된다.
Theta()
- lernable parameter
- 구하고자 하는 모델의 학습 파라미터
Batch Gradient Descent
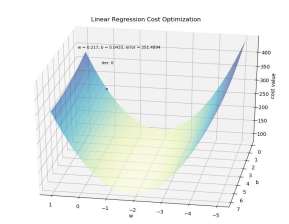
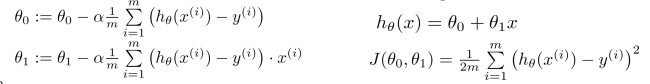
- local optimum에 취약하지만 어느 정도 수렴이 된다.
- 파라미터를 업데이트하는 과정에서 전체 샘플 m를 모두 고려 해야된다.
Stochastic Gradient Descent
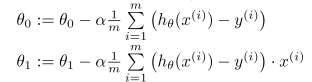
- batch gradient descent에서 m의 값을 1로 바꾼 것
- batch보다 빠르게 iterative하지만, 각 sample을 모두 계산하기 때문에 noise에 민감하다는 단점이 있다.
Limitation
Local Optimum
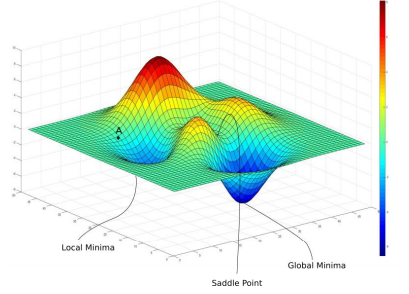
- 파라미터의 초기 point에 따라 local minimum에 도달할 가능성이 있다.
- saddle point에도 도달할 수 있다.
Avoid local minimum
Momentum
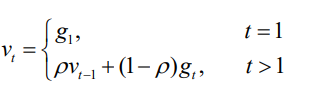
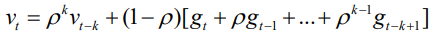
- 과거에 Gradient가 update 되던 방향 및 속도를 어느 정도 반영하여 현재 포인트에서 Gradient가 0이 되더라도 계속해서 학습을 진행할 수 있는 동력을 제공하게 되는 것
- 현재 시점에서 멀수록 작은 값이 곱해진다. 가까운 거리의 값은 비중이 높아진다.
Nesterov Momentum
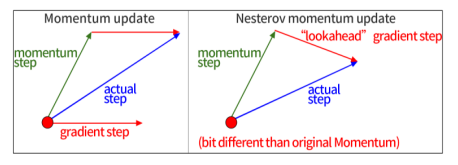
- 기존의 방식과 다르게 gradient를 먼저 평가하고 update를 해준다.
- lookahead gradient gradient step을 이용한다.
AdaGrad
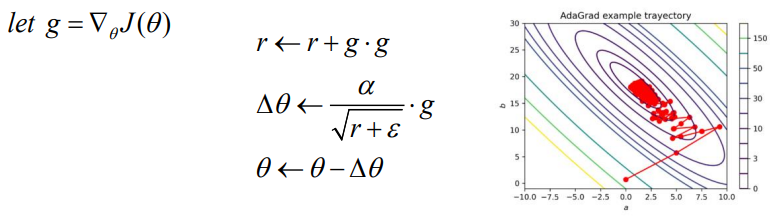
- 각 방향으로의 learning rate를 적응적으로 조절하여 학습 효율을 높이는 방식
- r은 gradient의 제곱이 더해지며 값이 커진다. 이러한 r이 분모에 위치하여 의 값이 점점 작아지도록 하는 방식으로 조절한다.
- 학습이 아직 덜 된 상태여서 r값이 작다면 의 값은 큰 값이 될 것이다.
- gradient의 값이 계속 누적됨에 따라 learning rate 값이 굉장히 작아지게 된다는 단점이 존재한다.
RMSProp
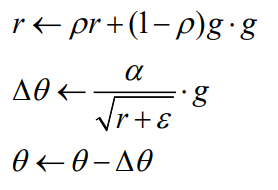
- learning rate 값이 작아지게 되어 학습이 일어나지 않는 것을 발전시킨 방법
- gradient의 제곱 값을 더하는 것이 아닌 값을 곱하는 것으로 r값에 대해 과거의 비중에 따라 조절을 할 수 있는 방식이다.
Adam(Addaptive moment estimation)
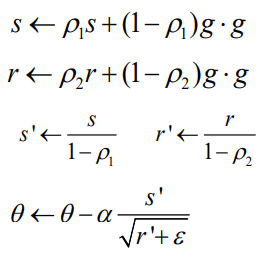
- RMSProp + momentum 방식
- Algorithm
- 첫번째 모멘텀을 계산한다.
- RMSProp을 이용하여 두번째 momentum을 계산한다.
- bias를 correction한다.
- parameter를 update한다.
Learning rate scheduling
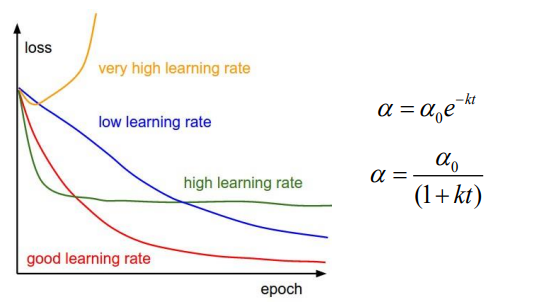
- hyperparameter 를 학습 과정에 따라서 조절을 한다.
- learning rate가 작다면 수렴 속도는 늦지만 loss를 줄일 수 있다.
- learning rate가 크다면 수렴 속도는 빠르지만 loss가 상대적으로 클 수 있거나 줄지 않을 수 있다.
Avoid overfitting
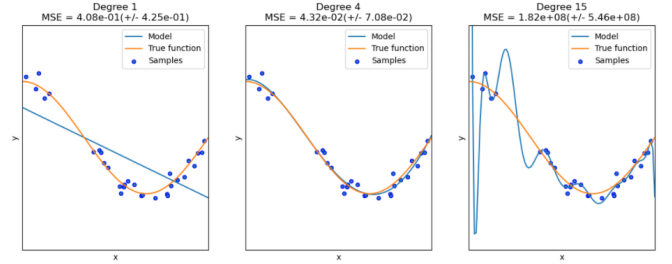
- overfitting은 model이 지나치게 복잡해서 학습 parameter의 숫자가 많아 제한된 학습 샘플에 너무 과하게 학습되기 때문에 발생한다.
- 입력 feature의 많은 것이 항상 좋은 것은 아니다.
- 각 feature들은 상호적으로 dependent 할 수 있기 때문이다.
- mse와 같은 loss를 확인하는 방식은 outlier, noise에 민감하기 때문에 조절을 잘 해야한다.
Regularization

- 복잡한 모델을 사용하더라도, 모델의 복잡도에 대한 패널티를 부여하여 overfitting을 방지하는 방식
- 값이 중요하지 않다면 0으로 처리하여 패널티를 줄이고, overfitting을 방지할 수 있다.

안녕하세요 :) Data/AI 공부 중인 한국외대 컴퓨터공학부 조권휘입니다.