본 포스트는 LG Aimers 활동에 참여하며 온라인 AI 교육을 정리한 내용입니다!
프로그램에 관심이 있으시다면 https://www.lgaimers.ai/ 를 참고해주세요!!
Linear Classification
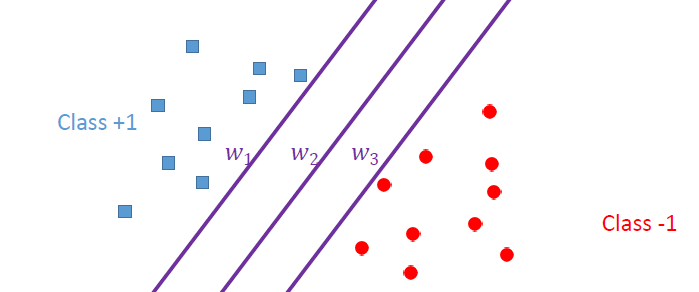
- 위와 같은 상황에서 와 같은 hyper plane을 그릴 수 있을 것이다.
- 모두 loss는 비슷하지만, 각 hyper plane 사이에 margin이 크기 때문에 새로운 data가 들어왔을 때 잘못된 판단을 할 가능성이 존재한다.
- positive / negative sample 사이 중간의 적당한 위치에 hyper plane을 배치해야한다.
Support Vector Machine(SVM)
- Margin을 정의하여 hyper plane을 결정한다.
- positive/negative sample중 hyper plane과 가장 가까운 점들 사이의 공간을 최대 margin으로 확보한다.
Support vector
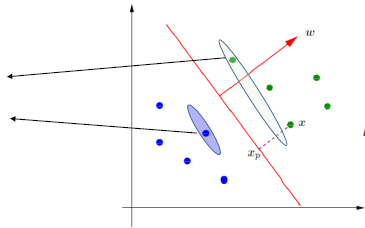
- hyper plane과 가장 가까운 거리에 위치한 positive / negative sample
- 성능을 정하는 가장 민감한 data
Margin
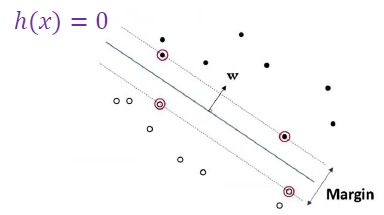
- hyper plane과 가장 가까운 instance의 2배가 margin이 된다.
- hyper plane
SVM Optimization
- SVM에서 margin을 최적화해야한다.
- Hard margin SVM : sample이 분리되어있다고 가정
- Soft margin SVM : 약간의 오차를 허용
- Nonlinear transform & kernel trick : 선형 모델이 아닌 것으로 생각하여 문제를 해결
Hard margin SVM
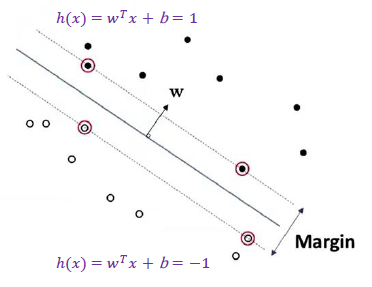
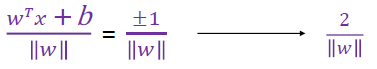
- sample이 linear seperate 되어 있다고 가정한다.
- positive / negative sample 사이의 거리는 동일하다고 생각하기 때문에 2배를 해주면 maximum margin이 된다.
- 를 최소화 → margin 최대화
SVM Primal problem
- 을 최소화 하도록 한다.
- 이는 constrain 문제로 바뀌게 된다.
Kernel Trick
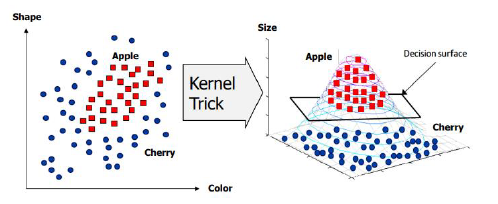
- linearly separable하지 않은 data sample들이 있다고 할 때, 그 차수를 높여 linearly Separable하게 만드는 과정
Polynomial Kernel
Gaussian radial Basis Function (RBF)
Hyperbolic Tangent
Artifical Neural Network(ANN)
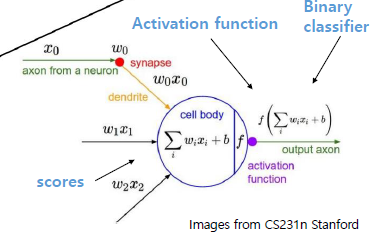
- nonlinear classification model을 제공
- Deep Neural Network의 기본
- 인간의 뇌 신경을 모사한 형태로 모델이 만들어졌다.
- score를 계산하고 활성화 함수를 통해 output이 나온다.
- 여러개의 계층을 쌓아감으로써 복잡한 모델을 만들고 복잡한 data를 분류할 수 있도록 한다.
- image recognition, Computer vision 등 많은 연구에 활용이 된다.
Activation Function
- sigmoid
- z 값에 따라 gradient 값이 작아지기 때문에 학습량이 작아지는 문제점 존재
- ReLU
- Leaky ReLU
Multilayer Perceptron (MLP)
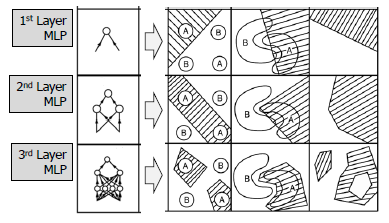
- 계층을 쌓아가면서 XOR 문제와 같은 문제를 해결할 수 있도록 한다.
Gradient Vanishing Problem

- model 학습 과정중 parameter를 chain rule을 통해 학습을 진행한다.
- 계층이 깊어질수록 gradient값이 줄어들어 깊은 layer에 대해서는 학습이 제대로 되지 않는 상황
Breakthrough Back Propagation
- vanishing gradient 문제를 해결하기 위한 optimization 방식
- CNN과 같은 방식을 통해 vanishing gradient를 해결한다.
Convolutional Neural network (CNN)
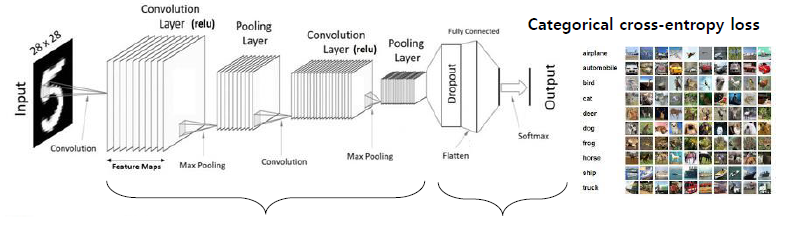
- ANN에서 고도화 되어서 이미지, 비디오와 같은 고차원의 신호를 다루는데 활용한다.

안녕하세요 :) Data/AI 공부 중인 한국외대 컴퓨터공학부 조권휘입니다.