Types of ML output
- Regression : 수학적으로 value를 예측
- Classification : n label을 예측
- Clustering : 다른 예시들과 가장 유사한 것을 예측
- Sequence Prediction : 다음 올 것을 예측
Continuous output
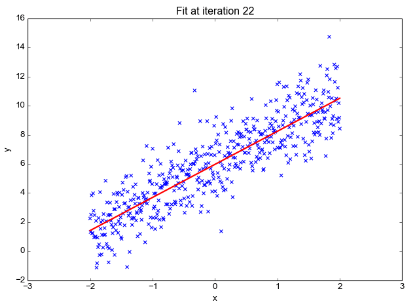
- input이 주어지면 수치형의 output을 반환한다.
- ex) linear regressor
Classification
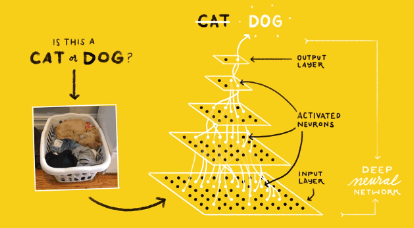
- input의 class를 output으로 반환해준다.
Probability Estimation
- 0과 1 사이의 숫자를 output으로 반환한다.
- output은 확률을 의미한다.
Types of ML algorithms
Regression
- 오차를 척도로 변수 사이의 관계를 반복적으로 modeling
- 통계학을 기반으로 한 방식
- ex) ordinary least squares regression, Logistic regression..
Instance - Based
- 학습된 사례들을 기억하는 것으로, 시스템이 훈련 데이터를 기억함으로써 학습한다.
- 새로운 데이터의 경우, 학습된 데이터와 새로운 데이터의 유사도를 측정한 뒤 클래스를 분류한다.
- ex) K-Nearest Neighbor, SVM, LVQ...
Regularization
- penalty를 주는 방식의 확장
- 다른 방식들에 대한 간단한 수정을 거친 것이다.
Decision Trees
- 특정 기준에 따라 데이터를 구분하는 모델
- 분류, 회귀문제에 다 사용되며, 빠르고 정확한 편이여서 ML에서 가장 선호되는 알고리즘이다.
- ex) Conditional Decision Trees
Bayesian
- bayesian 정리를 적용하는 방식
- 정리를 한 뒤 비슷한 feature끼리 분류를 진행한다.
- ex) Naive Bayes
Clustering
- class를 분류하는 방식
- centroid 방식과 hierarchial 방식이 존재한다.
- K-means, K-medians, Mean-shift, DBSCAN 등의 알고리즘이 존재한다.
Association Rules
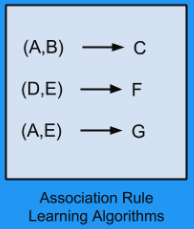
- 변수사이의 발견할 수 있는 관계를 가장 잘 설명하는 규칙을 추출
- ex) brute force, apriori algorithm, FP-growth algorithm
Support
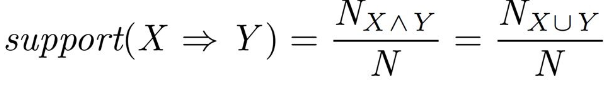
- 전체 경우의 수에서 X, Y가 같이 나오는 비율
Confidence
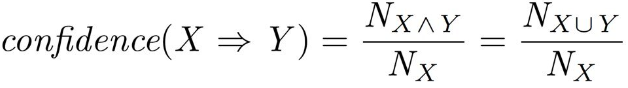
- X가 나온 경우 중 X, Y가 함께 나오는 비율
Lift
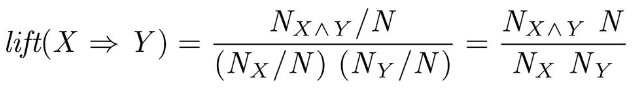
- X, Y가 같이 나오는 비율을 X가 나올 비율과 Y가 나올 비율의 곱으로 나눈 값
Artificial Neural Networks
- 뇌의 생물학적 신경망 구조, 성능을 모방한 모델
- 회귀, 분류 이외에도 대부분 모든 유형에 적용 가능
- ex) perceptron
Deep Learning
- Artificial Neural Networks에서 발전한 모델
- 훨씬 크고 복잡한 neural network를 가지며, semi-supervised learning 방식으로 진행하기도 한다.
- ex) Multi-layered perceptron, CNN..
Dimensionality Reduction
- clustering algorithm에서 성능 향상을 위해 사용하기도 한다.
- data를 조금 더 simple하게 만들어준다.
- ex) PCA...
Ensemble
- 여러 분류기로 구성된 모델로, 결합되어 전체 예측을 진행한다.
- ex) Boosting..
Ensemble Method
Stacking
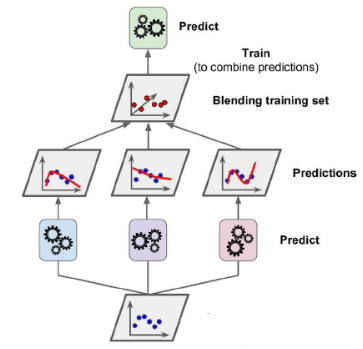
출처 : https://casa-de-feel.tistory.com/8
- 개별적인 여러 알고리즘을 결합하여 결과를 도출
- 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다.
- 교차 검증 기반으로 과적합을 개선
Voting
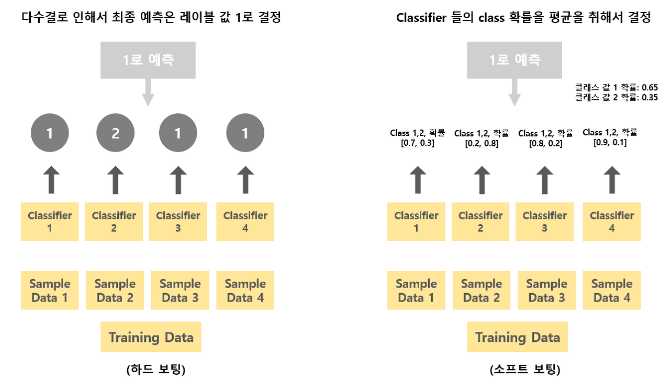
- 서로 다른 알고리즘으로 예측하고, 예측한 결과를 투표로 최종 예측 결과를 선정
1) Hard voting
- 다수결의 원칙으로, 다수의 분류기가 예측한 값을 최종 결과값으로 선정
2) Soft voting
- 각 예측 결과의 확률의 평균값이 높은 레이블 값을 최종 결과값으로 선정
Bagging (Bootstrap Aggregation)
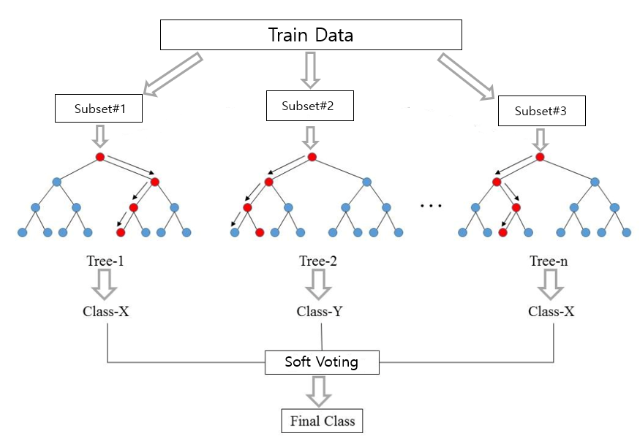
- 여러개의 분류기를 만들어 voting으로 최종 결정하는 방식
Boosting
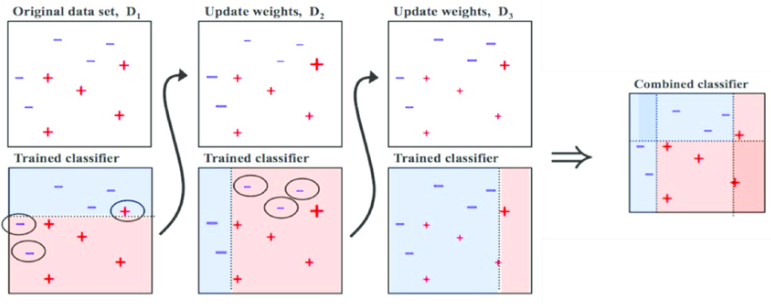
출처: Medium (Boosting and Bagging explained with examples)
- 여러 개의 약한 학습기를 순차적으로 학습, 예측하며 잘못 예측한 방식에 대해 가중치를 부여하고, 오류를 개선하며 점진적으로 학습하는 방식
- AdaBoost, GBM
XGBoost : GBM 기반으로, 느린 수행 시간 해결 및 과적합 규제 등을 통해 개선된 방식
- 빠른 수행시간, 과적합 규제, 내장 교차 검증, 결측값 자체 처리, 조기 중단 등의 장점 존재
LightGBM : GBM에서 leaf tree 분할 방식을 사용
- XGBoost보다 더욱 빠른 학습이 가능하고 더 작은 메모리를 사용하며 범주형 변수 자동 변환, 분할이 가능하지만 적은 데이터를 적용할 경우 과적합 가능성이 크다.

안녕하세요 :) Data/AI 공부 중인 한국외대 컴퓨터공학부 조권휘입니다.