Artificial Intelligence
- 기계가 보여주는 인간의 지능
- 인간의 task를 computer가 수행하는 것
- 인간이 수행하는 것보다 더 잘 수행하는 것
1) Object recognition
2) Speech recognicion / sound detection
3) Natural language Processing
4) Creative
5) Prediction
6) Translation
7) Restoration / Transformation
Machine Learning
- 일련의 데이터에서 패턴을 찾기 위해 경험을 통해 학습할 수 있는 시스템을 통해 인공지능을 달성하는 접근 방식
- 시스템에 필요한 학습을 위해 data를 수집
- 데이터로부터 패턴을 학습
- 이전에 보지 못한 새로운 데이터를 분류
Deep Learning
- 머신러닝을 향상시키기 위한 기술
- 패턴의 패턴을 학습하기 위해 인간의 뇌 형태와 유사하게 layer를 설정
ML 시스템을 학습하기 위한 data는 어떻게 고르는가?
Features / Attributes
- 학습하려는 것들의 properties
Examples
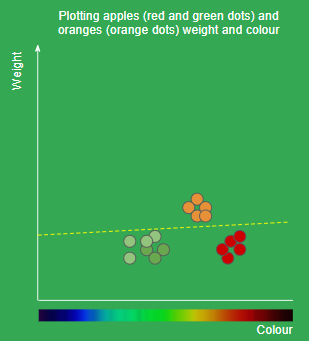
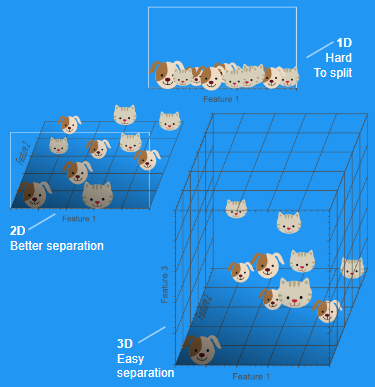
- 2개의 feature이 있을 때 2차원의 공간에서 항목을 나눠서 표현할 수 있다.
- 영역을 분할하여 분류하였을 때, 새로운 point가 존재하면 해당 point를 분류할 수 있다.
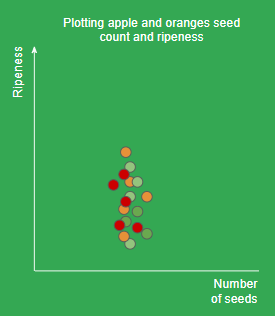
- 하지만 위의 그림과 같이 data들을 분리할 수 없는 경우가 존재한다.
- 이러한 경우에는 차원을 늘려서 생각을 해보면 된다.

- 2차원 공간에서 3차원 공간으로 확장하였을 때 data를 의미있게 나누는 것을 확인해볼 수 있다.
- 대부분의 ML 문제는 더욱 고차원의 문제로 연결된다.
- 수백만 개의 image recognition 같은 경우 훨씬 고차원의 영역으로 넘어가게 된다.
Dimensionality
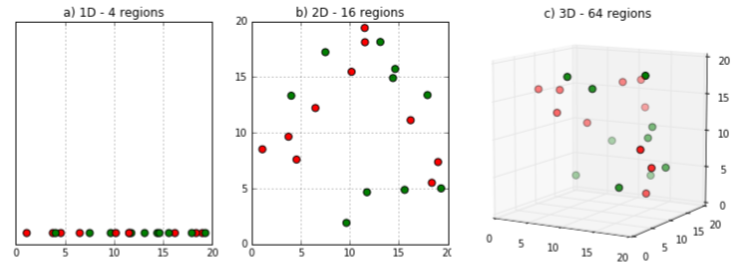
- 차원을 확장한다면 data points를 분리하는 것이 더욱 쉬워질 것이다.
- 하지만 차원을 너무 많이 확장한다면, 이는 overfitting이 발생할 것이다.
- 즉, overfitting이 발생하지 않는 정도의 적절한 차원확장을 찾는 것이 중요하다.
Curse of Dimension
- 학습을 위한 차원이 증가할수록 성능이 저하되는 현상
- 차원이 증가할수록 빈 공간이 많아지고, data point 간의 거리가 멀어진다.
- 빈 공간은 컴퓨터에서 0으로 채워진 공간이고, 이는 정보가 없는 공간이기 때문에 학습을 시켰을 때 모델의 성능이 저하된다.
- KNN과 같은 알고리즘에 치명적으로 성능이 저하되는 경우를 볼 수 있다.
How to Reduce the Curse of Dimensions
1) PCA : 분산을 이용하여 차원을 축소하는 방식
2) Random Projection : KN 행렬이라면 NM 행렬을 곱하여 K*M 행렬로 바꾸는 것, N차원을 M차원으로 변환
3) Feture Selection : 중요하고 의미 있는 feature만 이용하여 차원을 축소
4) SVD : PCA와 유사한 행렬 분해 기법을 사용
5) t-SNE : 고차원의 데이터를 시각화하는데 사용
How ML systems are trained
Superviesd Learning
- Label이 존재하는 data를 이용하여 학습을 진행하는 방식
- 주어진 데이터와 label로부터 모델을 학습시켜 새로운 데이터를 입력으로 받았을 때 label을 예측
Unsupervised Learning
- Labeling이 되지 않은 data set을 이용하여 학습을 진행
- data의 특징으로부터 unknown pattern을 학습
Reinforcement Learning
- Reward / Punishment를 이용하여 시행착오를 통한 학습
- program이 수백만 개 경우의 수를 시도해보고, 가장 좋은 방식으로 학습을 진행한다.
Neural Networks
- 인간의 뇌는 약 860억 개의 "뉴런"이 서로 상호연결되어 있다.
- 이러한 형상을 모방하여 ML에서 학습을 진행하도록 하였다.
Artificial Neuron (perceptron)
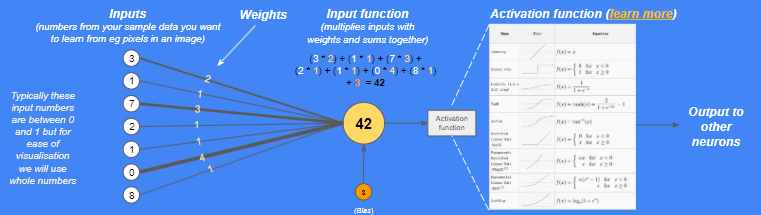
-
뉴런에는 weight(가중치)가 부여된 input(input*weight)이 더해진다.
-
total에 bias가 더해진다.
-
weight와 bias는 학습 중에 정의된다.
-
result > threshold라면 활성화가 되며 output을 제공한다.
Multi layered perceptron
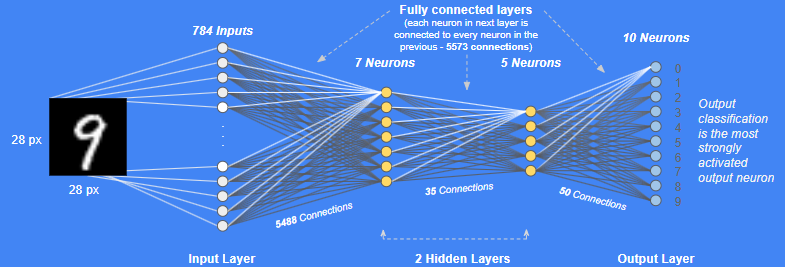
- 1개의 layer가 아닌 다중 layer로 구성이 된다.
- 각 layer는 fully connected가 되어있다.
Deep Neural Networks
- DNN은 input과 output 사이의 수많은 "hidden layer"로 구성이 되어있다.
- 각 layer는 이전 layer의 학습된 것 보다 고수준의 학습을 진행한다.
- hidden layer는 일반적으로 저차원으로 구성이 되며, input data에 overfit하지 않게 일반화를 시킨다.
Sigmoid vs ReLU
1. Sigmoid
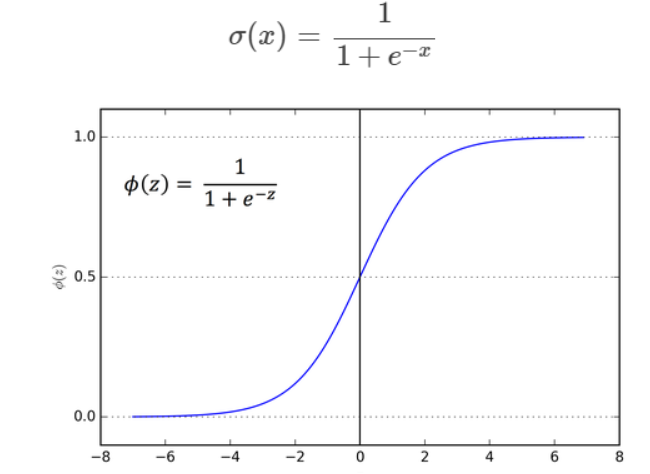
- binary classification 에 적절함 activation function
- 일정 값을 기준으로 0인지 1인지 구분함으로써 분류하는 방식
- sigmoid는 0<n<1 사이의 값만 다루므로 결국 chain rule을 이용해 계속 값을 곱해나간다고 했을 때, 결과 값이 0에 수렴할 수 밖에 없다는 한계를 가지고 있다.
2. ReLU
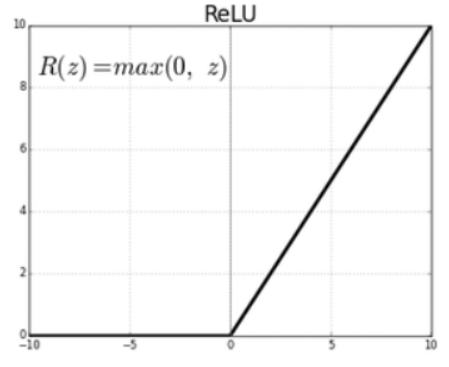
- 0보다 작은 값이 나온 경우 0을 반환하고, 0보다 큰 값이 나온 경우 그 값을 그대로 반환하는 activation function.
- ReLU(a) = max(0, a)
Convolutional Neural Networks

1. Filtering
1) Line up the feature, the image patch.
2) Multiply each image pixel by the corresponding feature pixel.
3) Add them up.
4) Divide by the total number of pixels in the feature.
→ 하나의 image가 filtered image들의 stack이 된다.
Stride
- filter가 얼마나 움직이는지를 정의, Convolution 연산 속도와 연관
Padding
- feature map 크기에 맞게 input feature map의 상하좌우 끝에 0으로 채워 feature map의 size를 증가시키는 방식
2. Pooling
- CNN의 차원은 매우 고차원이므로, filter에 사용된 parameter 수를 줄여 overfitting을 방지하기 위해 사용한다.
- Pick a window size (usually 2 or 3).
- Pick a stride (usually 2).
- Walk your window across your filtered images.
- From each window, take the maximum value.
→ similar pattern, but smaller.
- Max Pooling layer : Max value로 pooling
- Average Pooling layer : Average value로 pooling
- Global Pooling layer : 1차원의 vector로 pooling
Normalization
- 음수의 값을 0으로 변환
- ReLU function 등을 이용하여 변환
Deep Stacked

- 위의 Convolution, ReLU, Pooling layer를 계속해서 쌓아가며, 이전 단계의 output이 다음 단계의 input이 되도록 한다.
- 여러 번 이러한 단계를 반복하며 진행한다.
Fully connected layer

- 2차원 배열 형태를 1차원 배열로 변환
- Activation Function을 활성화
- Softmax로 분류
Backpropagation
- Error = Right answer - actual answer
- Gradient descent algorithm을 이용하여 error를 최소화하며 이전 변수의 값을 최신화하는 방식
- Chain rule을 이용하여 각 매개변수의 gradient를 계산
ResNet
- CNN이 이미지 인식 분야에서 뛰어난 성능을 보여주고, layer를 깊이 쌓으며 성능 향상을 진행
- 하지만, layer를 깊게 쌓으면 gradient vanishing / exploding이 발생하고, 성능이 떨어진다.
Gradient Vanishing / Exploding : 역전파로 얻어지는 기울기가 너무 작아지거나 커지는 현상
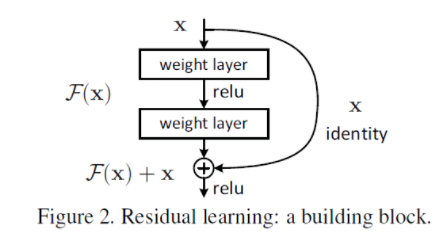
- 기존 CNN은 input x를 입력하여 가중치 layer를 거친 뒤 output은 F(x)
- Resnet은 F(x)에 input을 더한 F(x)+x를 output으로 반환
