참가 목표
-
에이블스쿨을 통해 들었던 수업 내용 써먹기
-
새로운 것 하나 시도하기
대회 분석
-
가입일, 음성사서함 이용 건수, 상담 전화 건수, 시간대별 통화 정보 등을 이용해 고객의 전화 해지 여부를 예측하는 머신러닝 분류 문제이다.
-
점수는 테스트 결과에 대한 F1-macro score를 사용한다.
F1-macro score
F1-score
- 우선 분류문제에 대한 모델의 성능을 나타낼 수 있는 대표적 지표이다.
- 이전에 정리해 둔 것이 있다.
macro
- 평균을 구하는 하나의 방법 중, 평균의 평균을 구한것을 macro라고 한다.
- 예를들어 다음과 같을 때
- recall-A : 0.3, 데이터 개수 60개
- recall-B : 0.5 , 데이터 개수 10개
- recall-C : 0.4, 데이터 개수 30개
각각의 평균을 클래스 수로 나눈 것이 macro 평균이다.
macro-avg = (0.3 + 0.5 + 0.4) / 3 = 0.4
micro
- micro는 역시 평균을 구하는 방법으로, 각 데이터의 개수대로 평균을 낸 것이다.
micro-avg = (0.3 * 60) + (0.5 * 10) + (0.4 * 30) / (60 + 10 + 30) = 0.35- macro에 비해 데이터가 더 많은 쪽으로 치우친다.
EDA
y-data profiling
- EDA 과정을 매우 쉽고 간편하게 할 수 있는 ydata profiling을 시도해보았다.
전화해지여부(target)
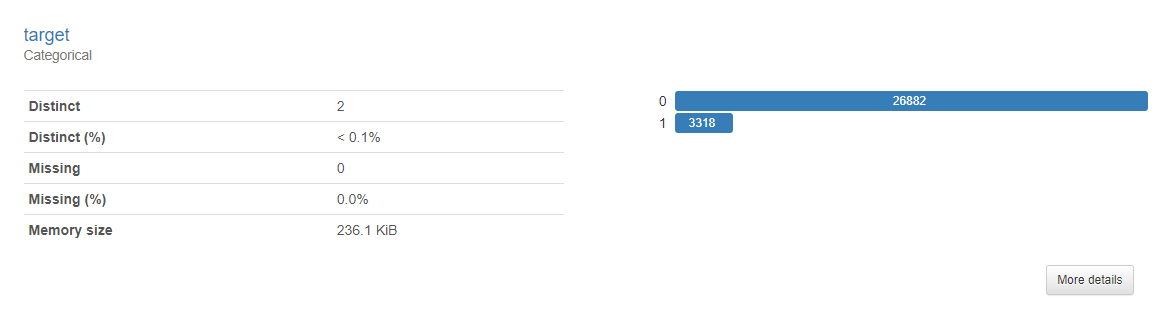
- 먼저 전화해지 여부인데, 해지하지 않은 사람(0)이 더 많은 불균형 클래스임을 알 수 있다.
- 1에 대한 검출도를 높이기 위해서는 오버샘플링 또는 언더샘플링 고려가 필요해보인다.
가입일, 음성사서함이용수
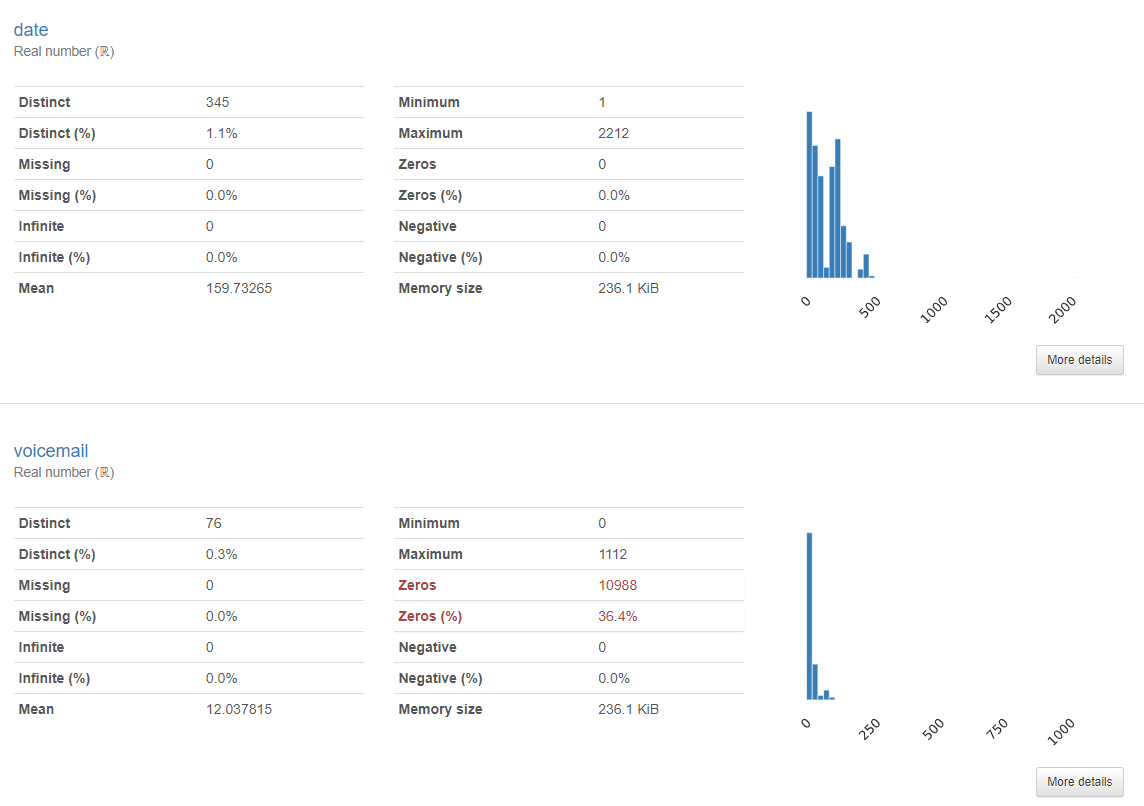
- 데이터가 왼쪽으로 치우친 형태를 보인다. 특히 음성서함은 상당수의 데이터가 0에 위치해있다.
가입일
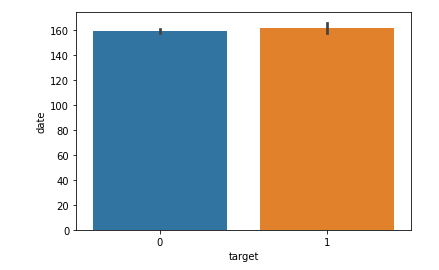
- 가입일에 대한 barplot을 확인했을 때 유의한 가입일에 따라 유의한 차이가 있어보이지는 않았다.
음성사서함이용수
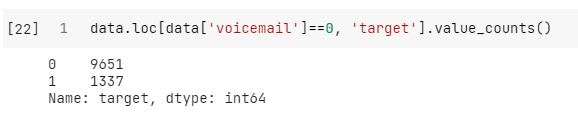
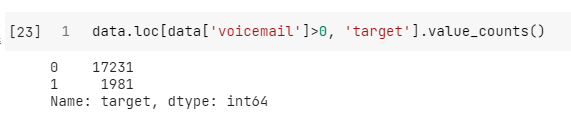
- value_counts로 확인해 봤을 때는, 음성사서함을 하나도 이용하지 않았을 때 해지하는 비율이 다소 높은 경향을 보였다.
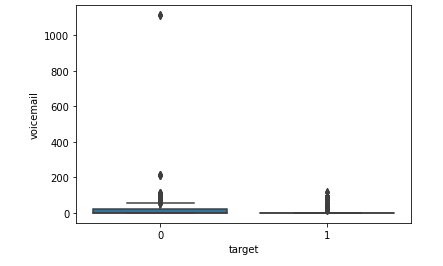
- box plot은 다음과 같다.
- 이건 뒤늦게 알게된 사실인데, 음성사서함의 대부분의 이용횟수는 200회 미만이고, 딱 9개의 데이터만 200을 넘는 값을 가지고 있었다. 이를 이상치로 간주하고, 나머지 값의 최대치 근처로 조정을 한 뒤 모델링을 진행했으면 조금이라도 성능이 상승하지 않았을까 하는 아쉬움이 있다.
통화관련 데이터
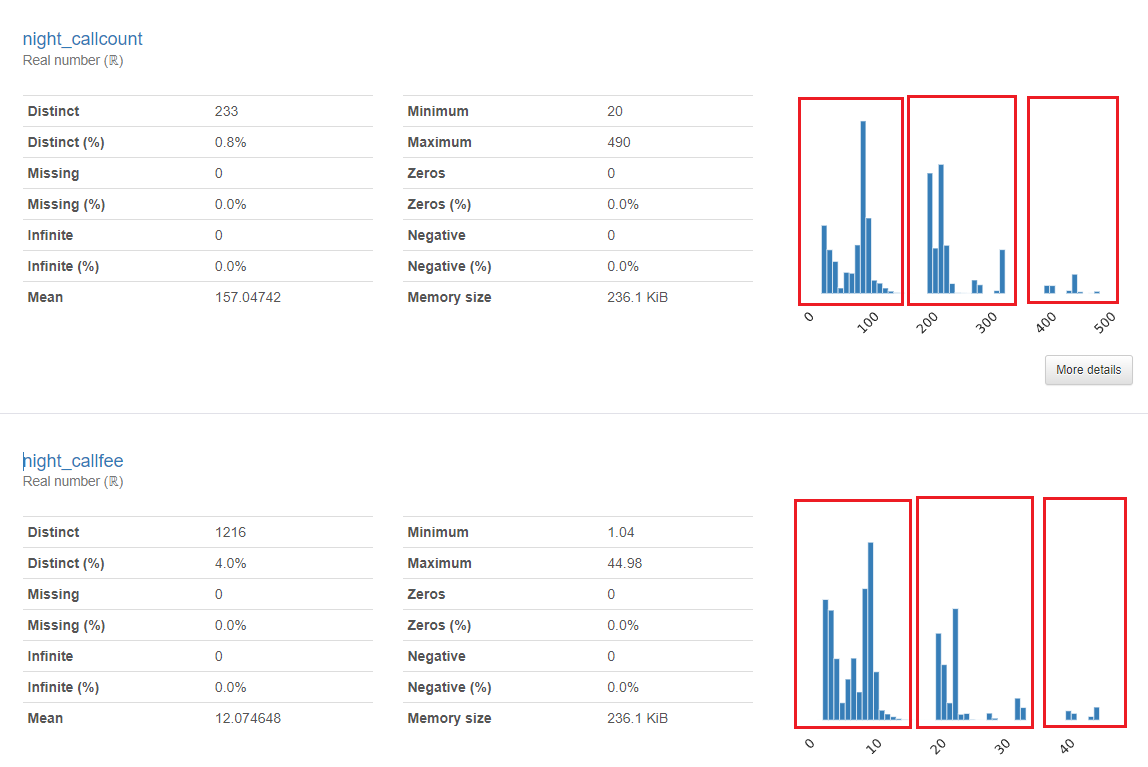
- 대체로 특정 구간별로 데이터가 나뉘는 듯한 모습을 보였다.
- 이를 범주화하는 것도 충분히 가능한 시도라고 생각하지만, 비슷한 성격을 띄는 새로운 변수를 추가해보는 것을 시도하였다.
데이터 전처리
Feature 생성
- 통화관련 데이터에서 보였던 데이터가 구간별로 나뉘는 현상이 요금제와 관련이 있지 않을까 추측하였다.
- 범주를 나누기보다는 통화 시간당 요금을 새로운 특징이라고 생성하였다. (둘 다 시도해보면 좋을 것 같지만 시간 관계상 하나만 시도)
같은 시간을 통화 하더라도 돈을 더 많이 낸 사람이 이탈하는 비율이 높지 않을까? 라는 가정이다.
오버샘플링 (SMOTE)
- 앞서 EDA 단계에서 불균형 클래스임을 파악했으므로, 오퍼샘플링을 통해 클래스 수를 맞추려고 시도했다.
- 기존에 머신러닝을 배우면서 한번도 오버샘플링을 시도해본적이 없었는데 배울 수 있는 기회가 생겨서 좋았다.
imblanced learn
-
scikit-learn을 이용한 머신러닝을 하고 있다면, imbalanced-learn 패키지를 이용하여 쉽게 언더샘플링, 오버샘플링 기법을 적용할 수 있다.
-
코랩을 사용한다면 별도로 설치가 필요하며,
import imblearn으로 사용할 수 있다.
!pip install -U imbalanced-learn
from imblearn.over_sampling import SMOTE
# SMOTE
smote = SMOTE()
x_res, y_res = smote.fit_resample(x, y)
# SMOTE - x_train에만 적용
smote = SMOTE()
x_train_res, y_train_res = smote.fit_resample(x_train, y_train)데이터 분리
- 데이터를 학습용 데이터와 검증용 데이터로 분리하는 작업을 거쳤다.
- 처음에는 오버샘플링을 적용한 뒤, 분리하였으나 테스트 데이터 역시 불균형 상태일 가능성이 높으므로 먼저 학습용과 검증용을 분리한 뒤, 학습용에만 오버샘플링을 적용하는 방식도 진행하였다.
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = \
train_test_split(x_train, y_train, test_size=0.2, stratify=y_train)- 학습용, 검증용이 동일한 분포를 갖도록 하기 위해 stratify를 적용하였다.
모델링
CatBoost
- 마찬가지로 기존에 사용해 본 적이 없던 CatBoost 모델을 사용해보았다. CatBoost는 XGBoost와 동일하게 트리 기반의 Boosting 학습 방법을 이용하는 모델로, 이전 모델의 outputs을 다음 모델의 Inputs으로 넣어 잔차(오차)를 줄여나가는 방법을 이용한다.
- XGBoost와의 가장 큰 차이점은 XGBoost는 모든 학습데이터를 이용하여 오차를 줄여나가지만, Catboost는 학습데이터에서 랜덤하게 정해진 순서에 따라 데이터를 샘플링하여 사용한다. 때문에 과대적합의 위험이 비교적 적다는 장점이 있다.
- scikit learn에서 제공하지 않는 모델이므로 별도 설치가 필요하다.
!pip install catboost
from catboost import CatBoostClassifier
params = {
'learning_rate' : 0.29,
'iterations' : 500,
'max_depth' : 12,
'l2_leaf_reg' : 3,
'id_type' : 'Iter',
'od_wait' : 100,
'use_best_model' : True,
'eval_metric' : 'F1'
}
model = CatBoostClassifier(**params)
model.fit(x_train_res, y_train_res, eval_set=(x_val, y_val))
y_pred= model.predict(x_test)- 모델링 당시에는 몰라서 F1-Score를 로스 함수로 지정하였으나, sklearn의 f1-macro 함수를 불러와 커스텀 로스 함수로 지정하면 eval_metric으로 사용할 수 있다.
베이지안 최적화(Bayesian Optimization)
Optimizing the inbound process with a machine learning model
- 쿠팡에서 머신러닝을 통해 문제를 해결하는 과정을 담은 칼럼을 개제하여 읽어보았더니, Bayesian Search라는 방법을 사용했다는 것을 알게되었다.
- 기존에 Grid Search, Random Search만 사용해보았기에 이것도 시도해보게 되었다.
베이지안 서치 수행 과정
참고자료
BAYESIAN OPTIMIZATION 개요: 딥러닝 모델의 효과적인 HYPERPARAMETER 탐색 방법론 (1)
Scikit-learn hyperparameter search wrapper
[ML] 베이지안 최적화 (Bayesian Optimization)
- 원리를 다루고 싶었지만, 내용이 너무 어려운 것 같아 추후에 별도로 강의를 들어야 할 것 같다. 대신 어떤 과정을 거쳐서 베이지안 최적화가 이루어지는지 정도를 다루고자 한다.
1. 설정값 입력
- 베이지안 서치에 필요한 설정값을 입력한다.
- 입력값(x) : learning_rage, max_depth, l2_leaf_reg, interations 등 찾고자 하는 하이퍼파라미터를 입력한다.
- 입력값의 탐색 구간
- 목적함수(f(x)) : 베이지안 서치는 목적함수(f(x))의 출력값이 최대가 되도록하는 x를 찾는 과정이다. 즉 목적함수로는 평가지표 (accuracy, f1-macro 등)를 지정하면 된다.
- 평가 횟수
2. 초기값 랜덤 샘플링
- RandomSearch와 동일하게 입력값을 랜덤하게 샘플링하여 정한다.
- 내가 베이지안 서치를 잘 이해한게 맞다면, 원래 이 과정에서 n번까지 랜덤한 샘플링 입력값으로 목적함수의 결과를 구하는데, 인자로 설정하는 방법을 못찾아서 이 과정을 어떻게 진행하는지 모르겠다.
3. Surrogate Model로 확률적 추정
- 초기 입력값에 대한 목적함수 결과를 구했다면, Surrogate Model이라는 확률적 추정을 하는 모델을 통해 다음 입력값을 결정하고 정한 평가 횟수 N에 도달할 때 까지 평가를 이어나간다.
코드
- scikit-learn이 베이지안 최적화를 제공하지는 않지만, 거의 동일한 문법으로 사용할 수 있도록 해주는
scikit-optimize패키지가 있다.
! pip install scikit-optimize
from catboost import CatBoostClassifier
from skopt import BayesSearchCV
from skopt.space import Real, Integer
model = CatBoostClassifier(task_type="GPU", devices='0:1')
params = {
'l2_leaf_reg' : Integer(2, 30)
'learning_rate' : Real(0.01, 10, 'log-uniform')
'iterations' : Integer(50, 1001),
'max_depth' : Integer(3, 12)
}
bayes = BayesSearchCV(model,
search_spaces=params,
scoring='f1_macro',
cv=5,
verbose=True,
n_jobs=-1,
n_iter=30)- 사용시 주의할 점은 기존의
range()나np.linspace()대신 패키지에서 제공하는 클래스를 사용해야 한다.
예측
Feature Importance
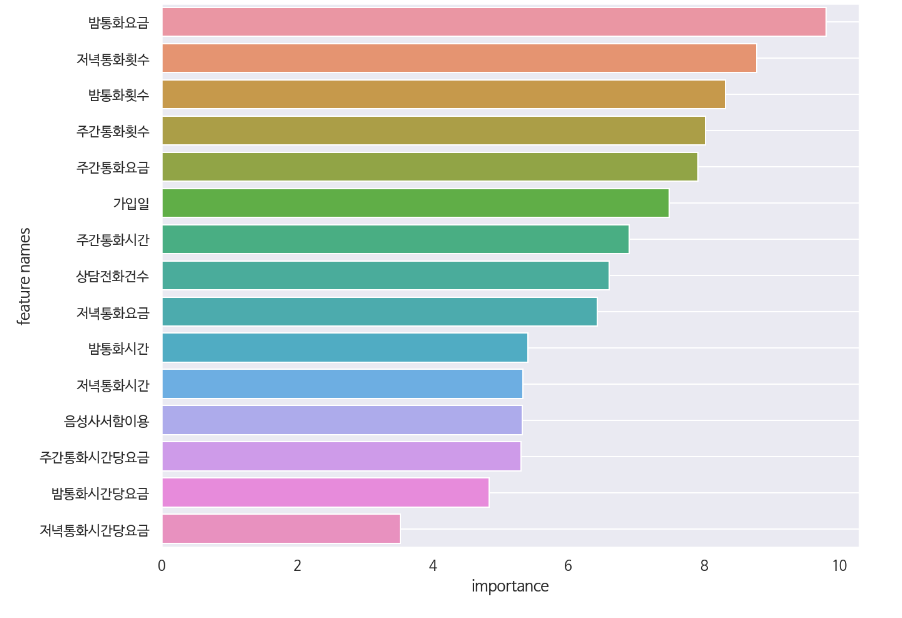
- 새로 추가한 컬럼의 중요도가 제일 낮은 것으로 나타났다.
- 생각외로 중요할 것이라 생각한 음성사서함 이용의 중요도가 낮게 나왔는데, 이상치를 적절히 처리하고 모델링을 했다면 중요도가 조금 더 높게 나오지 않았을까 조심스럽게 예측해본다.
테스트 점수

- test-score는 0.8024로 540여며의 참가자 중 171등을 기록했다.
소감
-
기존에 경진대회를 참여해본 경험이 없기 때문에, 가볍게 그냥 참가하는 것에 의의를 두려고 했다. 그런데 하다보니 새로운 모델, 새로운 기법을 이것저것 적용해보고 하면서 예상보다 많은 시간을 투자하게 되었다. 대신 그만큼 나쁘지 않은 결과가 나온 것 같아 만족스럽다.
-
다음에 또 개인 경진대회에 참가하게 된다면 AutoML을 통해 모델링 과정은 최소화하고, 대신 데이터 탐색, 전처리에 많은 시간을 투자해보고 싶다.
-
또는 딥러닝 모델을 사용해보는 것도 좋은 시도가 될 것 같다.
