
참가 목표
-
에이블 스쿨 언어지능 딥러닝 과정에 앞서 예습하기
-
기존에 경험해본적 없던 NLP 분야에 대해 배우기
-
새로운 것 하나 시도하기
사전 학습
-
대회를 약 10일 정도 앞두고 같은 반 에이블러 분들과 함께 스터디가 결성되었다. 자연어 처리에 대한 깊은 경험이 없는 사람이 많아 대회 시작 전까지 하루 평균 3시간 정도를 투자해 교재와 강의를 들으며 사전학습을 하였다.
-
대회를 진행함에 있어서는 큰 도움이 되지는 못했지만, 사전 학습 덕분에 에이블 스쿨의 언어지능 딥러닝 과정에서 강의를 잘 따라갈 수 있는 발판이 되어주었다.
-
개인적으로 단순히 교안만 보는 것으로는 이해가 안되거나, 이해했다고 착각한 개념이 많았는데 에이블스쿨 과정 중에 직접 실습해보고 나서야 비로소 이해되는 것들이 많았다. (실습의 중요성..)

- 교안으로는 입문자들에게 바이블처럼 여겨진다는 딥 러닝을 이용한 자연어 처리 입문 교재를 이용하였다. 시간이 없어서 필요한 부분만 쏙쏙 골라 읽고 실습도 꽤 많이 건너 뛰었는데, 차근차근 완독을 할 계획이다.
대회 분석
- 한국어로 작성된 기사를 100자 이내로 요약하는 대회이다.
평가지표
- 성능 점수는 요약 모델의 성능 평가에 주로 쓰이는 ROUGE-1, 2, L을 사용한다. 처음에는 어려워보였지만 F1-Score와 비슷한 개념이었다.
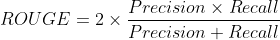
- 여기서 Precision과 Racall을 계산하는데 unigram을 사용할 것인지, bigram을 사용할 것인지에 따라 ROUGE-1, 2 등을 나눌 수 있다.
ROUGE-1
-
unigram을 사용하여 계산하는 방법이다.
-
과제 설명에는 mecab 형태소 분석기를 이용한 기준으로 n-gram을 검사한다고 하였으나 편의상 띄어쓰기로 구분하겠다.
-
y = 코로나19 예방접종 후 이상반응으로 신고된 사망자를 살펴보면 연령대가 낮을수록 2차 접종 후 신고율이 높은 양상을 보이고 있다. -
pred = 코로나19 예방접종 후 이상반응으로 신고된 사망자를 살펴보면 연령대가 높을수록 신고율이 높았고 아스트라제네카 백신이 화이자 백신보다 신고율이 높았다.
- 적중 :
코로나19예방접종후이상반응으로신고된사망자살펴보면연령대가신고율이- 9개 - 예측 실패 :
낮을수록2차접종높은양상을보이고있다- 7개 - 오예측 :
높을수록높았고아스트라제네카백신이화이자백신보다높았다- 7개
- Recall : 전체 정답 중 적중한 개수 ( 9 / 16 )
- Precision : 예측한 요약 중 적중한 개수 ( 9 / 16 )
- Recall과 Precision이 같으므로 F1-score도 9 / 16이다. (0.5625)
ROUGE-2
-
bigram을 사용하여 계산하는 방법이다.
-
일일히 계산하는 과정은 생략하겠으나
코로나19 예방접종예방접종 후후 이상반응으로와 같은 bigram으로 정답과 예측을 비교한다.
ROUGE-L
-
LCS(Longest Common Sequence) 기법을 이용하여 가장 길게 매칭되는 문자열을 찾아 Recall과 Precision을 계산한다.
-
무조건 연속해야 하는 것이 아니고, 순서까지만 일치하면 된다. 예를 들어 y와 pred의 LCS는 다음과 같다.
코로나19 예방접종 후 이상반응으로 신고된 사망자를 살펴보면 연령대가 신고율이- 이외의 문자열은 모두 틀린것으로 처리하여 F1-score를 계산한다.
새롭게 시도한 것들
- PyTorch와 카카오가 공개한 koGPT pretrained 모델을 이용한 베이스라인이 주어졌다.
- PyTorch도 처음 다뤄보는 것이기 때문에 직접 모델링을 수행한 것이 아니었다. 때문에 새롭게 시도해본 것들 위주로 작성해보려 한다.
문서 잘라보기
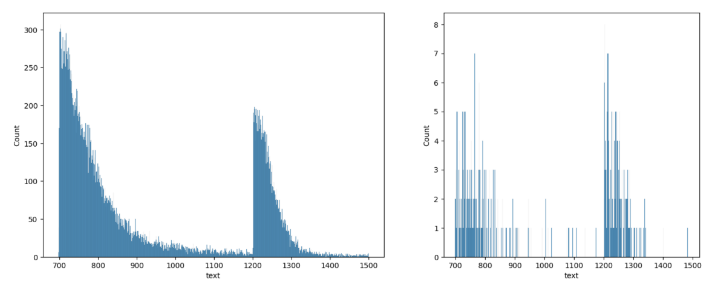
- 학습데이터, 테스트 데이터의 문서 길이 분포를 살펴보았을 때, 약 1200을 전후로 나뉘는 것을 확인할 수 있었다.
- 이걸 쪼개서 따로따로 학습 및 예측을 진행하는 것을 시도해 보았다.
- 이를 위해 문서 길이가 1200 미만인 데이터를 short, 1200 이상인 데이터를 long으로 구분하였다.
학습 데이터 줄여보기
- koGPT는 거대한 모델이기 때문에 코랩 프로환경에서 아슬아슬하게 돌아가는 수준이었고, 학습에도 에포크 당 2시간이 넘게 걸리는 수준이었다.
- 즉 5~6 에포크를 학습하는 것만으로 9.99 달러 어치의 컴퓨팅 자원을 소비해야하는데, 이것이 별로 바람직하지 못하다 생각하여 학습 데이터를 줄여보는 것을 시도하였다.
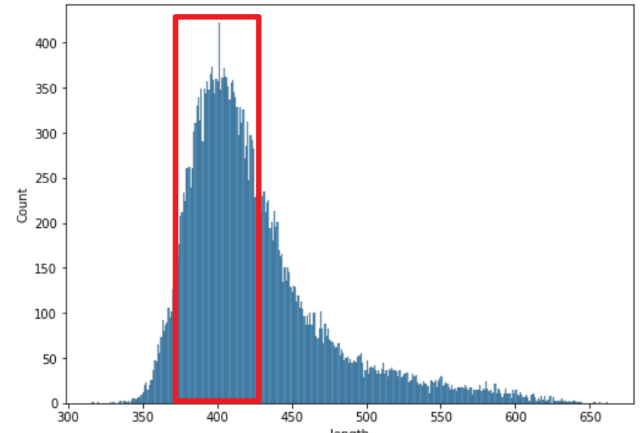
-
처음에는 최대 문자열 길이를 정해 turncating 하였으나, 성능이 좋지 않아 특정 길이를 갖는 토큰을 선택하여 학습하였다.
-
토큰에 채워지는 패딩을 줄이는 쪽으로 생각하여 빨간박스 안에 들어오는 데이터만을 남기고 나머지는 제거하였다.
-
결과적으로 한 에포크에 20여분 정도로 학습 시간이 줄어 10~20 에포크의 학습도 시도해 볼 수 있었다.
문제해결 : pd.DataFrame -> Torch Datasets
-
토치 모델에 데이터를 넣으려면 Datasets 객체로 변환해야하는데, 문제는 토큰을 데이터 프레임으로 변환하는 과정을 거치다 보니, 일부 리스트를 통채로 하나의 문자열로 인식하여 에러가 발생하였다.
-
이를 해결하기 위해 read_csv에서 converters 옵션을 이용해 DataFrame을 로드할 때, 각 열마다 문자열을 리스트로 변환해주는 함수를 적용하도록 하였다.
import ast
def converter(x):
# 문자열을 받아 리스트로 변환
return ast.literal_eval(x)
converters={'input_ids': converter,
'attention_mask' : converter,
'labels' : converter}
# 토큰 csv 파일을 불러옵니다.
train_df = pd.read_csv(f'{ROOT}/train_token_cut.csv', converters=converters)Warmup, ReduceLR 써보기
-
기존에 Tensorflow에서 사용했던 Warmup과 ReduceLRonpleatu 콜백 함수를 사용하였다.
-
Warmup은 처음부터 높은 learning_rate를 주지 않고 몇 에포크에 걸쳐 서서히 증가시키는 방법이다. 팀원의 결과에서, 학습률이 높았을 때 높은 성능을 보였기 때문에 1e-4라는 높은 learning rate를 주고 Warmup과 함께 사용하였다.
-
ReduceLR은 학습이 일정 수준동안 진행되지 않을 때(tr_loss가 줄어들지 않을 때) learning rate를 감소 시키는 방법이다.
-
Torch 문법을 몰라 적용에 어려움을 겪었는데, 에이블러 팀원들의 도움을 받아 코드를 제공받거나 문법적인 도움을 얻을 수 있었다.
learning_rate = 1e-4
optimizer = torch.optim.AdamW(peft_model_s.parameters(), lr=learning_rate)
scaler = torch.cuda.amp.GradScaler()
# ReduceLR
scheduler2 = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=100, threshold=0.0001, threshold_mode='rel', cooldown=total_steps//NUM_EPOCHS, min_lr=1e-6, verbose=True)- 베이스 라인으로 제공받은 학습 코드에 해당 콜백 함수가 업데이트 되도록 추가하였다.
def training_step(model, batch, optimizer, scaler):
global count
optimizer.zero_grad()
with torch.cuda.amp.autocast():
outputs = model(
input_ids = batch['input_ids'],
attention_mask = batch['attention_mask'],
labels = batch['labels'],
)
step_loss = outputs[0]
scaler.scale(step_loss).backward()
scaler.step(optimizer)
scaler.update()
# Warmup
scheduler1.step()
if count > warmup_step:
# ReduceLR
scheduler2.step(step_loss)
count += 1
return step_loss.detach()소감
-
총 58개 팀 중 17등으로 아쉽게 수상에는 실패하였다.
-
또한 내가 제출한 답안의 성능이 제일 좋았던 것이 아니기 때문에 점수 면에서는 팀에 별 보탬이 되지 않은 것 같아 아쉬웠다. 대신 토큰을 DataFrame으로 변환하고 다시 불러오는 코드나, 문법 교정을 하는 후처리 코드등을 작성해 공유함으로써 최대한 팀원들에게 도움이 되려고 노력하였다.
-
개인적인 성과는 baseline을 그대로 돌렸을 때보다는 좋은 score를 뽑아내었다는 것이다.
