kafka
Apache Kafka(아파치 카프카)란 무엇인가?
위의 링크를 보고 공부하는 것을 추천한다.
- Kafka는 LinkedIn에서 개발한 분산 스트리밍 플랫폼, 오픈 소스 메시지 브로커
- 메시징, 메트릭 수집, 로그 수집, 스트림 처리 등 다양한 용도로 사용 가능
특징
- 빠르다
- 수 천개의 데이터 소스로 부터 초당 수백 메가바이트의 데이터를 입력 받아도 안정적으로 처리 가능
- 확장가능
- 메시지를 파티션으로 분리햐여 분산 저장, 처리할 수 있어 클러스터로 구성하여 확장 가능
- 안정적이다
- 클러스터에 파티션 복제하여 장애 내구성을 가짐
구조
- 발행/구독(Pub/Sub) 모델
- Kafka는 발행-구독(Pub/Sub)모델을 기반으로 동작
- 발행-구독 모델은 발행자(Producer)가 메시지를 특정 수신자에게 직접 보내는 방식이 아니라
- 주제(topic)에 맞게 브로커에게 전달하면 구독자(Consumer)가 브로커에 요청해서 가져가는 방식
- 발행자는 메시지를 topic으로 카테고리화
- 구독자는 topic에 맞는 메시지를 브로커에게 요청
- 발행자와 구독자는 서로 알지 못함
Broker
- Kafka Broker는 Kafka에서 데이터를 저장하고 전송하는 서버이다.
- Kafka는 일반적으로 클러스터로 배포되며, 클러스터의 각 브로커는 메시지를 수신하고 저장하는 역할을 한다.
- 클러스터로 구성된 메시지 큐
- 메시지는 클러스터에 파티션 단위로 나누어 관리/복제 됨
- 파일 시스템에 메시지를 저장하므로 유실이 없고 복구 가능
- 하드디스크의 순차적 읽기 기능을 이용하여 속도를 유지
- 구독자가 메시지를 가져가도 바로 삭제하지 않음
- 기본 설정은 7일간 저장하고 삭제
- Kafka 브로커는 높은 가용성, 데이터 보존 및 데이터 복제를 지원합니다.
Producer
- Kafka Producer는 데이터를 Kafka Broker로 보내는 클라이언트이다.
- Producer는 Kafka Broker로 데이터를 보내는 메시지를 작성하고 전송한다.
- 메세지를 생산하는 주체
- 메세지를 만들고 브로커(Broker)에게 토픽(Topic)으로 분류된 메시지를 전달
- Kafka Producer는 대규모 데이터 스트림을 생성하는 애플리케이션에서 사용된다.
- 발행자는 구독자의 존재를 알지 못함
Consumer
- Kafka Consumer는 Kafka Broker에서 데이터를 읽는 클라이언트이다.
- Consumer는 Broker로부터 메시지를 수신하고 처리한다.
- 발행자의 존재를 알지 못함
- 원하는 토픽을 구독하여 스스로 조절해가면서 소비할 수 있음
- 원하는 토픽의 각 파티션에 존재하는 오프셋의 위치를 기억하고 관리하여 데이터의 중복을 관리
- 오프셋 관리를 통해 발행자, 구독자에 장애가 발생해도 마지막으로 읽었던 위치에서 부터 다시 구독 가능
- fail-over에 대한 신뢰가 존재
- Kafka Consumer는 대규모 데이터 스트림을 처리하는 애플리케이션에서 사용된다.
결론
- 이렇게 Kafka는 분산 시스템에서 대규모의 데이터 스트림을 처리하는데 적합한 메시지 큐이다.
- Broker는 데이터를 저장하고 전송하는 역할을 하며, Producer는 데이터를 생성하고 Broker로 전송하고, Consumer는 Broker로부터 데이터를 수신하고 처리한다.
Topic - Partion
Topic
- 메시지는 topic으로 분류
- topic은 발행자가 스트림을 발행하는 단위
- 스트림의 발행과 구독은 topic단위로 처리
Partion
- 하나의 topic은 여러 개의 파티션으로 저장할 수 있음
- 1개의 토픽은 여러 개의 파티션으로 저장되고, 하나의 파티션은 여러개의 로그로 기록
- 1:N = Topic:Partition, 1:N = Partition:Log
- 하나의 토픽을 여러 파티션으로 나누면 메세지 분산 처리로 처리량을 높일 수 있고, 분산 저장을 통해 오류가 발생할 때 데이터를 복구할 수 있음
- 파티션의 크기는 운영 중에 동적으로 줄일 수 없기 때문에 파티션 개수를 설정할 때 주의해야 함
Linux 환경에서 kafka 실행
준비물
centos 8로 이루어진 가상 머신 3대 준비
설치
- wget https://downloads.apache.org/kafka/3.4.0/kafka_2.13-3.4.0.tgz
- tar -xzvf kafka_2.13-3.4.0.tgz
- mv kafka_2.13-3.4.0 /opt/kafka
- 카프카는 자바 언어를 기반으로 프로그래밍 되어있음.
- 자바의 코틀린, 스칼라 중 스칼라 버전을 다운 받음.
- 그렇기 때문에 자바도 설치해야함.
- yum -y install java-1.8.0-openjdk-devel.x86_64
호스트 이름 설정
- 각 컴퓨터
- vi /etc/hostname
- 브로커는 broker
- 프로듀서는 producer
- 컨슈머는 consumer
- vi /etc/hostname
- 모든 컴퓨터
- vi /etc/hosts
- [브로커 IP] broker
- [프로듀서 IP] producer
- [컨슈머 IP] consumer
- vi /etc/hosts
broker 세팅
- 일단 같은 ip의 broker 가상 머신을 putty로 터미널 2개 열기
- 첫번째 세션
- systemctl stop firewalld
- 방화벽 해제
- /opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
- kafka를 실행시켜주기 위한 zookeeper 실행
- systemctl stop firewalld
- 두번째 세션
- vi /opt/kafka/config/server.properties
- 38번 라인 advertised.listeners 주석 해제
- advertised.listeners=PLAINTEXT://브로커IP:9092 이런 식으로
- /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
- vi /opt/kafka/config/server.properties
Zookeeper
- 왜 zookeeper(사육사)일까?
- Hadoop부터해서 Spark, Hive Flume, HBase, Ambari, Sqoop들이 다 동물 아이콘이다.
- 이런 동물 빅 데이터 플랫폼을 관리한다고 해서 Zookeeper라고 한다!
- 이런 프로그램들은 전부 하나로 동작하는게 아닌, 최소 3대로 클러스터링 해놓는데, 1번이 뻗으면 2번을 대표로 시키고, 2번이 뻗으면 3번을 대표로 시키는 식이다.
- Zookeeper가 kafka를 관리함.
- zookeeper 없으면 kafka 실행 못함.
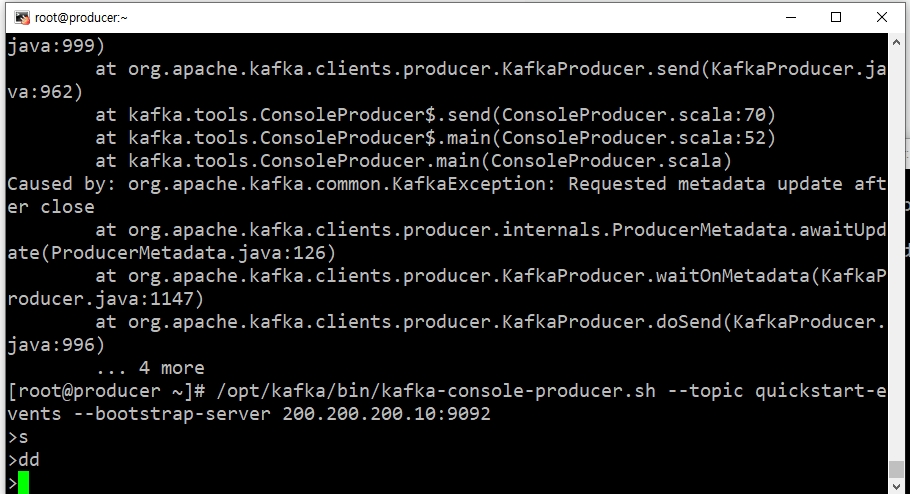
- producer가 메세지를 보내면 broker의 큐에 담긴다.
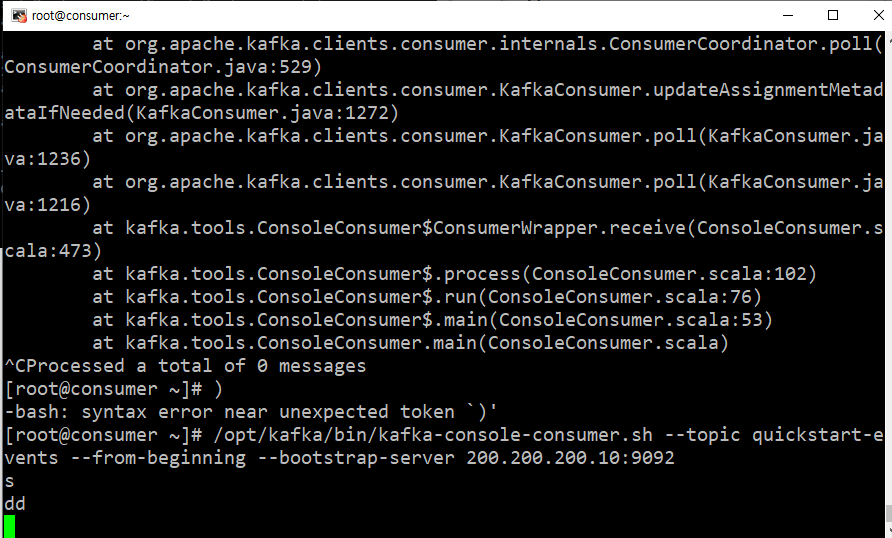
- consumer는 broker의 큐에 담겨져 있는 메세지를 빼온다.
python으로 kafka
설치
- pip install kafka-python
코드
broker
- 위에 Linux 환경에 켜놓은 broker 사용
producer
# producer.py
from kafka import KafkaProducer
import time
producer = KafkaProducer(
bootstrap_servers=['리눅스에 켜놓은 broker의 ip:9092']
)
start = time.time()
for i in range(100):
producer.send('test', value="test".encode("utf-8"))
# test라는 topic으로 test라는 내용의 메세지를 보냄.
producer.flush()
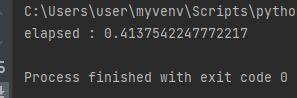
print("elapsed :", time.time() - start)consumer
# consumer.py
from kafka import KafkaConsumer
from json import loads
consumer = KafkaConsumer(
'test',
bootstrap_servers=['리눅스에 켜놓은 broker의 ip:9092']
)
# test라는 토픽으로 모든 메세지를 가져오겠다.
print('[begin] get consumer list')
for message in consumer:
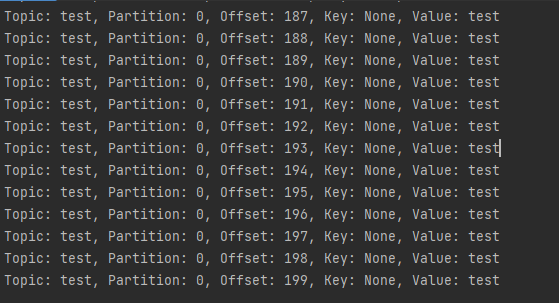
print("Topic: %s, Partition: %d, Offset: %d, Key: %s, Value: %s" % ( message.topic, message.partition, message.offset, message.key, message.value.decode('utf-8') ))
print('[end] get consumer list')- 요즘은 json으로 데이터를 주고 받기 때문에, json으로 데이터를 주고 받아보자.
결과
json 으로 주고 받기
코드
broker
- 위에 Linux 환경에 켜놓은 broker 사용
producer
# producer.py
from kafka import KafkaProducer
from json import dumps
import time
producer = KafkaProducer(
acks=0,
compression_type='gzip',
bootstrap_servers=['192.168.100.201:9092'],
value_serializer=lambda x: dumps(x).encode('utf-8')
)
start = time.time()
for i in range(100):
data = {'str' : 'result'+str(i)}
producer.send('test', value=data)
producer.flush()
print("elapsed :", time.time() - start)consumer
# consumer.py
from kafka import KafkaConsumer
consumer = KafkaConsumer(
'test',
bootstrap_servers=['192.168.100.100:9092'],
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='my-group',
value_deserializer=lambda x: x.decode('utf-8'),
consumer_timeout_ms=10000
)
print('[begin] get consumer list')
for message in consumer:
print("Topic: %s, Partition: %d, Offset: %d, Key: %s, Value: %s" % (
message.topic, message.partition, message.offset, message.key, message.value))
print('[end] get consumer list')
- producer의 결과
-
consumer의 결과
-
producer가 topic에 해당하는 메시지를 큐에 집어넣으면 consumer가 원하는 topic의 메시지들을 꺼내서 볼 수 있다.

항상 성장하는 개발자 최동혁입니다.