프로그래머스
1.[프로그래머스] 문자열 압축

문자열 압축데이터 처리 전문가가 되고 싶은 "어피치"는 문자열을 압축하는 방법에 대해 공부를 하고 있습니다. 최근에 대량의 데이터 처리를 위한 간단한 비손실 압축 방법에 대해 공부를 하고 있는데, 문자열에서 같은 값이 연속해서 나타나는 것을 그 문자의 개수와 반복되는
2.[프로그래머스] 소수 찾기
소수 찾기한자리 숫자가 적힌 종이 조각이 흩어져있습니다. 흩어진 종이 조각을 붙여 소수를 몇 개 만들 수 있는지 알아내려 합니다.각 종이 조각에 적힌 숫자가 적힌 문자열 numbers가 주어졌을 때, 종이 조각으로 만들 수 있는 소수가 몇 개인지 return 하도록 s
3.[프로그래머스] 거리두기 확인하기
거리두기 확인하기개발자를 희망하는 죠르디가 카카오에 면접을 보러 왔습니다.코로나 바이러스 감염 예방을 위해 응시자들은 거리를 둬서 대기를 해야하는데 개발 직군 면접인 만큼아래와 같은 규칙으로 대기실에 거리를 두고 앉도록 안내하고 있습니다.1\. 대기실은 5개이며, 각
4.[프로그래머스] 메뉴 리뉴얼
메뉴 리뉴얼레스토랑을 운영하던 스카피는 코로나19로 인한 불경기를 극복하고자 메뉴를 새로 구성하려고 고민하고 있습니다.기존에는 단품으로만 제공하던 메뉴를 조합해서 코스요리 형태로 재구성해서 새로운 메뉴를 제공하기로 결정했습니다. 어떤 단품메뉴들을 조합해서 코스요리 메뉴
5.[프로그래머스] 멀쩡한 사각형
멀쩡한 사각형가로 길이가 Wcm, 세로 길이가 Hcm인 직사각형 종이가 있습니다. 종이에는 가로, 세로 방향과 평행하게 격자 형태로 선이 그어져 있으며, 모든 격자칸은 1cm x 1cm 크기입니다. 이 종이를 격자 선을 따라 1cm × 1cm의 정사각형으로 잘라 사용할
6.[프로그래머스] 오픈채팅방
오픈채팅방카카오톡 오픈채팅방에서는 친구가 아닌 사람들과 대화를 할 수 있는데, 본래 닉네임이 아닌 가상의 닉네임을 사용하여 채팅방에 들어갈 수 있다.신입사원인 김크루는 카카오톡 오픈 채팅방을 개설한 사람을 위해, 다양한 사람들이 들어오고, 나가는 것을 지켜볼 수 있는
7.[프로그래머스] 전화번호 목록
전화번호 목록전화번호부에 적힌 전화번호 중, 한 번호가 다른 번호의 접두어인 경우가 있는지 확인하려 합니다.전화번호가 다음과 같을 경우, 구조대 전화번호는 영석이의 전화번호의 접두사입니다.구조대 : 119박준영 : 97 674 223지영석 : 11 9552 4421전화
8.[프로그래머스] N으로 표현
N으로 표현아래와 같이 5와 사칙연산만으로 12를 표현할 수 있습니다.12 = 5 + 5 + (5 / 5) + (5 / 5)12 = 55 / 5 + 5 / 512 = (55 + 5) / 55를 사용한 횟수는 각각 6,5,4 입니다. 그리고 이중 가장 작은 경우는 4입니
9.[프로그래머스] 가장 비싼 상품 구하기
가장 비싼 상품 구하기
10.[프로그래머스] 가격이 제일 비싼 식품의 정보 출력하기
가격이 제일 비싼 식품의 정보 출력하기
11.[프로그래머스] 최대값 구하기
최댓값 구하기
12.[프로그래머스] 최솟값 구하기
최솟값 구하기
13.[프로그래머스] 동물 수 구하기
동물 수 구하기
14.[프로그래머스] 중복 제거하기
중복 제거하기
15.[프로그래머스] 서울에 위치한 식당 목록 출력하기
서울에 위치한 식당 목록 출력하기
16.[프로그래머스] 점 찍기
x좌표와 y좌표로 나뉘는데, x좌표를 기준으로 삼았다.거리가 d이기 때문에, x 좌표는 0부터 d까지이다.그렇기 때문에, x를 k만큼씩 증가시키면서 y의 최대값을 정수형으로 구하고, k로 나누어서 y의 개수를 더해주었다. 1을 더해주는 것은 0좌표까지 생각해야되기 때문
17.[프로그래머스] 파괴되지 않은 건물
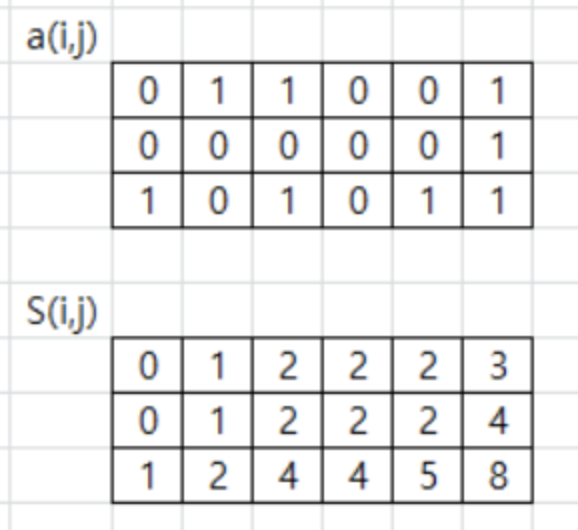
skill의 최대 개수는 250,000이고, 배열은 최대 1000 X 1000 배열이다.skill은 무조건 루프를 돌아야 하기 때문에 $O(n^2)$으로 풀게 되면 안된다.그래서 생각난 것이 부분 배열 합이다.2차원배열에서 부분 배열의 합을 구하는 방법을 알아보자. 이
18.[프로그래머스] 디펜스 게임
일단 enemy 배열을 돌면서 k를 생각하지 않고 n으로만 계속 디펜스 한다. 1.1 막으면서 막은 수는 heap에 넣어준다. (최대 힙) 1.2 최대 힙으로 넣는 이유는 n값이 전부 동나서 k없이 막을 수 없을 경우 지금까지 막아온 최댓값과 현재 막아야 하는 enem
19.[프로그래머스] 귤 고르기
귤 배열을 전부 Count를 이용해서 중복되는 갯수 새기dict로 형 변환value값을 기준으로 내림차순 정렬루프를 돌면서 k값을 깎아가며 상자 포장하기 4.1 k가 0보다 작거나 같아지면 상자 하나가 완성된 것이기 때문에 몇 종류로 포장했는지 returnsorted의
20.[프로그래머스] 우박수열 정적분
주어지는 배열 ranges에서 원소 a는 시작지점, b는 끝 점으로 부터의 offset이다.1.1 만약 a가 2, b가 -3인데 우박수열 끝 점의 x좌표가 6이라면 2, 3이다.1.2 끝인 6에서부터 -3만큼 떨어진 지점이 최종 범위인것이다.각 지점의 등변사다리꼴을 전
21.[프로그래머스] 롤케이크 자르기
전체 토핑을 딕셔너리로 만든다.토핑을 하나씩 지나갈때마다 전체 토핑 딕셔너리에서 1개씩 빼주고 brother 딕셔너리에 추가해준다. 2.1 만약 전체 토핑에서 뺏을 때 0인 경우 삭제시켜준다.2.2 전체 토핑의 길이와 brother 딕셔너리의 길이가 같다면 서로 종류의
22.[프로그래머스] 택배상자
보조 컨테이너는 stack으로 구현order를 보고 만약 stack에 존재하는 box라면 stack에 가장 끝부분과 비교한다.만약 같다면 pop을 하고 아니라면 더이상 상자를 못 싣기 때문에 끝낸다.만약 stack에 존재하지 않는 box라면 현재 start 인덱스부터
23.[프로그래머스] 연속 부분 수열 합의 개수
먼저 루프를 돌면서 기준 숫자 하나를 정한다.길이가 2인 연속되는 숫자의 합을 구하고 set()에 넣는다길이가 3인 ~길이가 4인 ~그렇게 elements의 길이만큼 루프를 돌면서 계속 한개씩 추가시켜주면서 길이가 1,2,3....,len(elements) 의 합들을
24.[프로그래머스] 할인 행사
want에 해당하는 갯수를 매핑해서 dict로 만든다.그리고 discount 배열을 돌면서 한번 돌 때마다, 그 부분을 기준으로 10개를 Counter를 이용해서 dict로 만든다.만약 만든 dict와 want dict와 같다면 전부 할인을 받을 수 있는것이며, 같지
25.[프로그래머스] 두 큐 합 같게 만들기
각 큐의 합을 비교하면서 큰 큐에서는 빼서 작은 큐에 값을 넣어준다.여기서 각 큐의 합은 sum 함수가 아닌 처음에 구해놓은 값에서 빼거나 더할때마다 사칙연산 해주는 식으로 해야 시간초과가 뜨지 않는다.반복문을 멈추는 조건은 각 큐 중 가장 길이가 긴 값에 서로의 큐를
26.[프로그래머스] 양궁대회
일단 info의 범위가 11개다.중복 조합, 즉 완전 탐색으로 푼다면?$nH_r = {n+r-1}C{n-1}$11개 중에 10개가 최악의 경우이기 때문에${11}H{10} = {20}C\_{10} = 184756$그리고 그 안에서 루프가 11만큼 더 돌더라도 18475
27.[프로그래머스] 주차 요금 계산
차가 들어오고 나갈때마다 다른 defaultdict에 누적시간을 더해준다.나감 처리를 안한 차가 있을수도 있으니, 나간 차는 dict에서 삭제한다.모든 처리를 하고, 남아있는 차가 있으면 23:59분에 나감으로 시간을 누적시켜준다.누적되어 있는 시간을 기준으로 기본 시
28.[프로그래머스] k진수에서 소수 개수 구하기
10진수 -> n진수 바꾸는 코드n으로 계속 나누면서 나머지 값을 넣어주기마지막에 뒤집기에라토스테네스의 체 사용각 수마다 제곱근을 이용해야함.
29.[프로그래머스] 피로도
사실 이거는 데이터 자체가 작아서 무조건 완전탐색이다.dfs로 풀긴 했는데 permutation이 이 문제의 취지에 좀 더 적합하다고 생각한다.처음에는 heap으로 접근을 했는데 9번 테케 하나를 통과 못해서 뒤엎게 되었다.dfs로 permutation을 구현하는 식으
30.[프로그래머스] n^2 배열 자르기
몫과 나머지를 이용해서 배열에 들어갈 숫자를 계산해준다.n^2의 데이터 사이즈가 1000만의 제곱이기 때문에 무조건 2중 루프나 n^2의 범위를 넘기면 안된다우리가 필요한 것은 left부터 right 사이의 배열값이기 때문에 index를 이용해 수학적 규칙을 찾으면 된
31.[프로그래머스] 교점에 별 만들기
문제 가장 밑에 교점을 구하는 공식이 있다.line의 데이터 범위는 1000개 이기 때문에 완전 탐색으로 교점을 찾아도 괜찮다.교점을 전부 찾은 후, 가로의 길이와 세로의 길이를 구한다세로의 길이 중 가장 큰 값을 기준 0 으로 삼고 행으로 index 값을 바꾼다가로의
32.[프로그래머스] 전력망을 둘로 나누기
그래프화 시킨 후 하나씩 끊어가며 bfs 돌리기차이가 가장 작은 값 리턴
33.[프로그래머스] 빛의 경로 사이클
빛의 경로는 어디서 출발을 하든 같은 경로라면 같은 케이스라고 본다.그렇기 때문에 빛이 한번 지나간 곳을 지나면 그것은 같은 케이스 일 수 밖에 없다이유는 왼쪽에서 오른쪽으로 빛이 들어왔으면, 그것의 다음 경로는 무조건 서로 같을 수 밖에 없기 때문이다.그래서 3차원
34.[프로그래머스] 테이블 해시 함수
문제에서 말한대로 람다 값으로 col - 1 번째 기준 오름차순 정렬, 같다면 0번째 인덱스로 내림차순 정렬한다.그 후, 정렬된 데이터를 기준으로 begin 부터 end 까지 슬라이싱 해준다.정렬 + 슬라이싱된 데이터를 기준으로 순회하며 i로 나눈 나머지 값들을 계속해
35.[프로그래머스] 모음 사전
itertools의 product는 데카르트 곱이다.모든 경우의 수를 문자열로 만들어주고, set 자료구조의 합집합 연산자를 이용해서 하나의 리스트로 만들어준후, 정렬을 해준다.문자열의 정렬 성질과 문제의 순서가 같다.
36.[프로그래머스] 2래 이하로 다른 비트
짝수는 무조건 뒤의 수가 0이다.그렇기 때문에 1을 증가 시켜도 서로 비트가 1개밖에 차이가 나지 않아서 +1 한 수가 정답이다.홀수는?예를 들면 10001111이 있다고 치자그렇다면 1을 증가시키면 10010000으로 엄청 달라지게 된다.그래서 가장 나중에 나오는 0
37.[프로그래머스] 가장 가까운 작은 글자
딕셔너리를 이용해 푼다만약 딕셔너리에 존재하는 수면 현재 index에서 저장되어 있는 index를 뺀 수를 answer에 집어넣어준다.없다면 -1을 answer에 집어넣어준다.그리고 공통적으로 현재 index로 딕셔너리에 업데이트 해준다.
38.[프로그래머스] 크기가 작은 부분 문자열
전체 루프를 돌면서 현재 문자에서 비교해야 하는 문자열의 길이만큼 비교해준다.작으면 + 1을 해주고, 만약 비교해야 하는 문자열을 넘어가게 되면 break로 멈춘다.
39.[프로그래머스] 행렬 테두리 회전하기
row \* column 행렬을 1부터 시작해서 증가하는 식으로 만들어준다.상, 하, 좌, 우를 tmp와 tmp1을 이용해 숫자들을 교체해주면서 회전시켜준다.ans 리스트에 넣어주면서 최솟값을 전체 정답 answer에 넣어준다.
40.[프로그래머스] 괄호 회전하기
첫번째 로직문자열 슬라이싱을 이용해서 하나씩 회전시켜준다.두번째 로직먼저 닫히는 괄호들 먼저 루프를 돌면서 확인 후, 닫히는 괄호라면 stack 안에 짝이 맞는 여는 괄호가 있는지 체크한다.없거나, stack이 비어있다면 그 문자는 올바른 괄호가 아니기 때문에 answ
41.[프로그래머스] 쿼드압축 후 개수 세기
잘게 쪼개질때까지 재귀 함수를 호출해준다.4등분으로 짤라주면서 파라미터로는 arr배열과 answer 배열 그리고 시작 행, 열 index를 넣어준다.더 이상 쪼개지지 않는다면 해당 값을 return 해준다.4 방향으로 쪼개고 나온 return 값으로 비교를 한다.만약
42.[프로그래머스] 조건에 맞는 도서 리스트 출력하기
풀이 코드
43.[프로그래머스] 흉부외과 또는 일반외과 의사 목록 출력하기
풀이 코드
44.[프로그래머스] 조건에 맞는 도서 리스트 출력하기
풀이 코드
45.[프로그래머스] 3월에 태어난 여성 회원 목록 출력하기
풀이 코드
46.[프로그래머스] 과일로 만든 아이스크림 고르기
풀이 코드
47.[프로그래머스] 12세 이하인 여자 환자 목록 출력하기
48.[프로그래머스] 인기있는 아이스크림
풀이 코드
49.[프로그래머스] 서울에 위치한 식당 목록 출력하기
풀이 코드
50.[프로그래머스] 강원도에 위치한 생산공장 목록 출력하기
풀이 코드
51.[프로그래머스] 모든 레코드 조회하기
풀이 코드
52.[프로그래머스] 재구매가 일어난 상품과 회원 리스트 구하기
풀이 코드
53.[프로그래머스] 역순 정렬하기
풀이 코드
54.[프로그래머스] 오프라인/온라인 판매 데이터 통합하기
풀이 코드
55.[프로그래머스] 아픈 동물 찾기
풀이 코드
56.[프로그래머스] 어린 동물 찾기
풀이 코드
57.[프로그래머스] 동물의 아이디와 이름
풀이 코드
58.[프로그래머스] 여러 기준으로 정렬하기
풀이 코드
59.[프로그래머스] 상위 n개 레코드
60.[프로그래머스] 조건에 맞는 회원수 구하기
풀이 코드
61.[프로그래머스] 마법의 엘리베이터
중요한 키 포인트는 1의 자리 수 부터 시작할지, 가장 끝 자리 수 부터 시작할지이다.그 다음 키는 5와 9이다.5를 더해서 자리수를 넘길지, 빼서 0으로 만들지이다.여기서 생각해야할 반례가 95와 55이다.45는 45 -> 40 -> 0 : 5 + 4 = 955는 5
62.[프로그래머스] 삼각 달팽이
달팽이는 하, 우, 상 의 순서로 계속 반복함한번 방문한 곳에 부딪히거나, 범위의 끝에 가면 바로 다음 방향으로 꺾어서 진행함
63.[프로그래머스] 유사 칸토어 비트열

n에서의 총 1의 개수는 4^n임.f(n)은 f(n - 1) f(n - 1) (0 \* 5^(n - 1)) f(n - 1) f(n - 1) 이다. 2.1 여기서 f(n - 1)에서 1의 개수는 4^(n - 1)이다.2번 식을 잘 이해한 후, 몫과 나머지를 이용하여 몫
64.[프로그래머스] 튜플
set() 자료형을 얼마나 잘 알고있냐의 문제인것 같다.문자열들을 set 자료형으로 바꾸어 주고, set()의 차집합과 합집합을 이용하여 문제를 풀면 된다.
65.[프로그래머스] 괄호 변환
풀이 방법이랄것이 없다...문제가 이해가 가지 않았는데 문제에서 풀라는데로 뇌 빼고 풀었더니 맞았다.이해하고 싶지도 않고, 이런 류의 문제는 코테에서 좀 안나왔으면 좋겠다.팁은 이해하려고 하지 말고, 시키는데로 풀자..
66.[프로그래머스] 순위 검색

"-" 이거 때문에 모든 경우의 수를 전부 생각해야한다.위의 그림처럼 모든 경우의 수를 생각하면 16가지가 나온다.이 16가지를 하나의 dict에 넣어준다.key값은 언어, 직군, 경력, 소울푸드의 str을 전부 하나의 문자열로 합쳐서 넣어준다.value는 defaul
67.[프로그래머스] 광물 캐기

각 곡괭이로 캐면서 소모되는 피로도를 dict로 정리한다.예를 들어, 5번씩 캘 수 있으니, 전체 광물이 13개가 있다면, dia의 dict는 5,5,3이 되는것이다.다이아 곡괭이의 수를 일단 무시하고 캐는데 소모되는 피로도만 전부 넣어준다.마찬가지로 다른 곡괭이들도
68.[프로그래머스] 택배 배달과 수거하기
개인적으로 최근 들어 가장 어려운 level2 문제였다.이 문제의 핵심은 택배 출발 지점부터 생각하는게 아닌, 끝 지점 부터 생각하는 것이다.배달과 수거 둘 중 가장 멀리 있는 곳을 기준으로 삼아야 한다.가장 먼저 시작하기 전 가장 멀리 있는 택배물을 찾기 위해 루프를