코로나와 주식, 그리고 Granger Test
0. 들어가며
주식 시세 정보는 아주 대표적인 시계열 데이터이다. 그 중에서도 한국 주식 시장을 아주 대표하는 200개의 기업 KOSPI의 데이터는 더더욱 뭔가 매우 대표적인 대표성을 대표한다고 볼 수 있겠다.
하지만, 주식은 시계열 데이터라면 으레 띄고 있을 것으로 예상되는 온갖 성질들을 갖가지 방법으로 피해다니는 녀석이다. 추세(Trend), 계절성(Seasonal), 주기(Cycle) 등, 이런 이론적인 시계열 분해 속성값들이 제멋대로 날뛴다는 뜻이다. 그럼에도, 혹은 그렇기에, 이런 더러운 데이터를 우리는 예측해내고 싶어 안달이 나있고, 지금도 직접 노동, 육체 노동의 선호가 갈수록 떨어져가고 있는 요즘 시대의 트렌드에 맞춰, 더더욱 많은 노동가능인구 연령대의 사람들이 주식 시장에 뛰어들고, 주식 시장을 연신 들여다보며, 요즘 경기 불황 분위기에 맞춰 '물리고' 있다.
이런 나같은 개미들을 위해 아주 미약하게나마라도 주식에 영향력을 행사할 수 있는 변수가 뭐가 있을지 고민해보게 되었다. 아니, 일단 영향력 있는 변수인지 확인해낼 방법이 뭐가 있을지부터 먼저 고민해보게 되었고, 그 결과로 시계열 데이터 분석법을 공부하게 되었다.
그렇게 알아보던 중, 오늘의 주제, 'Granger Causality Test'에 대해서 알게 되었다. 이 녀석은 시계열 상의 선형적 인과관계가 있는지 여부를 알려주는 데에 사용된다고 한다. 그 해석에 있어서 위험성이 많아 주요 핵심 분석 툴로는 잘 사용되지 않고, 보조적인 수단으로 쓰인다고 한다.
오히려 좋아. 더 편안한 마음으로 GCT를 이용해보기로 했다.
전에 코로나19의 확진자 수 변화가 주식 시세에 영향을 끼쳤을 것으로 상정하고 분석해본 적이 있었는데, 그때 사용했던 데이터를 이용해보기로 했다.
코로나 확진자가 발생한 2020년 1월 20일부터 2022년 12월 31일까지의
코로나 확진자 수 데이터와 KOSPI200 기업의 시세 정보 데이터로 GCT를 시행해보고자 했다.
코로나 확진자 수를 x, 독립 변수로 두고 각 기업의 시세들을 y라고 두고 분석을 해보기로 했다. 엥? 독립 변수 하나에 종속 변수 200개요..? 물론 한 번에 분석을 돌리는 건 아니다. GCT는 x 하나, y 하나 이렇게 단일 분석만 가능하니, 확진자 수랑 현대건설 한 번 돌리고, 확진자 수랑 카카오 한 번 돌리고, 이런 식으로 200번의 분석을 진행해보기로 했다. 그리드 서치(Grid Search) 비슷하게 말이다.
하나하나 다 돌려보고 그 중 인과관계가 유의하게 존재한다고 나오는 기업들을 추려내서, 그 기업들에 대한 메타 데이터를 찾아보면 뭔가 재밌는 공통점을 찾을 수 있지 않을까? 하는 가설에 입각해 분석을 시작했다.
분석에 사용된 라이브러리는 다음과 같다.
import pandas as pd
import numpy as np
from statsmodels.tsa.stattools import adfuller, kpss # 정상성
from statsmodels.tsa.stattools import grangercausalitytests #GCT1. 데이터셋 준비
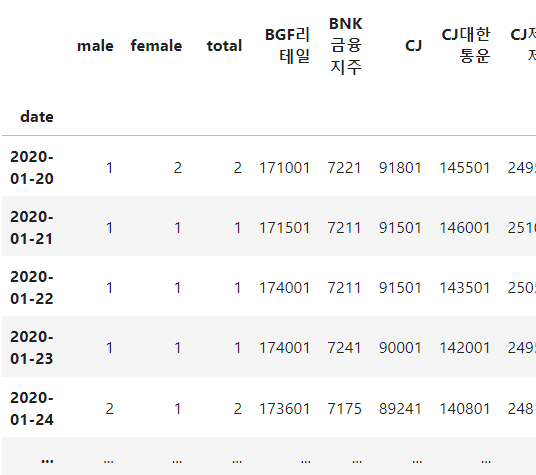
대충 이런 형태로 데이터셋을 만들어줬다. 2020년 1월 20일부터 남자 확진자 수(male), 여자 확진자 수(female), 총 확진자 수(total), 그리고 KOSPI 200 기업들의 각 날짜별 종가. 그런데 KOSPI 200 기업 중 신생 기업들이 몇 기업 존재한다. 즉, 2020년 1월 20일에 존재하지 않았던 기업들이 존재하는데, 이 기업들은 신생 기업이라는 특성이 다른 변수들의 영향력을 약화시킬 심산이 크다고 판단하여 모두 제거해줬다. 그렇게 16개의 기업을 제거해주고, 184개의 기업이 살아남았다.
2. GCT를 위하여
GCT를 하기 위해선 일단 비교 대상인 두 변수 모두 정상성을 띄고 있어야 한다. 정상성이란, 추세를 띄거나, 계절성을 띄거나 하는 등 어떤 규칙성이 보이지 않아야 한다는 것이다. 정상성이 보이지 않을 경우, 정상성을 띄는 데이터로 만들어 줄 수 있는데, 크게 두 가지 방법을 사용한다. 차분을 해주거나, 로그를 씌워주거나. 차분이란, 당일의 데이터값에서 특정 시점의 데이터값을 빼주는 것을 말한다. 오늘 데이터에서 어제 데이터를 빼주는 식이다. 로그를 씌워주는 건 데이터의 불균형을 해소하기 위한 방법으로 쓰인다.
우리 데이터들은 정상성을 띄고 있을까? 정상성을 수치적으로 확인해볼 수 있는 ADF, KPSS 두 테스트를 각각의 변수에 다 실행해본 결과, 역시나 그 어떤 변수도 정상성을 띄지 않았다.
정상성을 띄지 않는 데이터는, 보통의 경우 차분 한 번만 해줘도 정상성을 띄게 되지만, 우리 데이터는 차분을 두 번을 해줘도 정상성이 나타나지 않는 경우가 부지기수였다. 특히나 코로나 확진자 수 데이터부터 상황이 좋아보이지 않아서 차분과 로그 두 방법을 모두 사용해주기로 했다. 로그를 먼저 씌워주고, 차분을 해줬다. 그렇게 정상성을 띄는 데이터로 만들어줬다.
GCT를 위하여.
3. Granger Causality Test
정상성을 만들어주고, 총 확진자 수 'total'를 독립 변수로 두고, 나머지 기업들의 종가 데이터를 종속 변수로 둬서 하나하나 GCT를 돌려준 결과, 총 11개의 기업 데이터와 선형적 인과관계가 있는 것으로 나타났다.

결과는 개인적으로 놀라웠다. 앞전의 분석에서 '상관관계'를 파악했을 때, 그렇게 높지 않은 상관관계를 가졌던 기업들이었기 때문이다. 앞서도 얘기했듯이 해석에 주의가 필요하고 선형적 인과관계의 유무를 판단하는 테스트이므로, 강도는 생각보다 중요치 않구나 싶었다.
4. 마치며
이렇게 GCT 결과로 얻어낸 유의 집단 각각과 total 변수를 다시 ARIMA 모델을 이용해서 학습하고 적합도(rmse 등)를 확인해보면 어떤 결과가 나올지를 재검정해야 의미가 있는지 알 수 있을 것 같다. 이래서 GCT가 부차적인 도구로 사용되는 것이군? (아 물론, ARIMA로 돌려도 유의한 결과는 나오지 않을 것이다. SARIMA를 돌려도, SARIMAX를 돌려도. 그것이 주식 데이터니까. 음.)
데이터 출처 : 네이버 증권, 공공데이터포털
import pandas as pd
import numpy as np
from statsmodels.tsa.stattools import adfuller, kpss
from statsmodels.tsa.stattools import grangercausalitytests
>
def stationary_test(df, target_column):
target_series = df[target_column].dropna()
adf_result = adfuller(target_series)
adf_p_value = adf_result[1]
kpss_result = kpss(target_series)
kpss_p_value = kpss_result[1]
if adf_p_value < 0.05 and kpss_p_value > 0.05:
return True
else:
return False
>
def check_granger_causality(result):
ans = False
for i in range(1, len(result)+1):
mean = 0
for key in result[i][0].keys():
mean += result[i][0][key][1]
if mean / 4 < 0.05:
ans = True
else:
ans = False
return ans
>
df = pd.read_csv(
'./data/covid_finance.csv',
index_col='date',
parse_dates=True
)
target_index = '2023-01-01'
index_position = df.index.get_loc(target_index)
train_df = df.iloc[:index_position, :]
test_df = df.iloc[index_position:, :]
train_df = train_df + 1
test_df = test_df + 1
>
train_df_1d_log = pd.DataFrame()
for col in train_df.columns:
train_df_1d_log[col] = np.log1p(train_df[col]).diff()
train_df_1d_log = train_df_1d_log.dropna()
>
x_columns = []
>
for col in train_df_1d_log.columns[3:]:
check_stationary = stationary_test(train_df_1d_log, col)
if not check_stationary:
continue
result = grangercausalitytests(
train_df[[col, 'total']],
maxlag=5,
verbose=False
)
check = check_granger_causality(result)
if check:
x_columns.append(col)
>
print(x_columns)
좋은 내용 감사합니다 멋지네요! 저도 금융 개발 공부하는 중인데, https://quantpro.co.kr/ 해당 사이트 퀀트 내용 어떤지 의견주시면 감사하겠습니다!