심플하게 딥러닝 기법으로 학습한 모델로 이미지를 분류해내는 과정을 적어보고자 한다.
1. 데이터 및 분석 환경 준비
1) 데이터 준비
데이터 출처 : Cats and Dogs
우선 데이터가 필요하다. 데이터는 학습에 사용할 사진 여러장과 각 장의 라벨 정보가 담긴 csv파일이 필요하다. train에 사용할 데이터, test에 사용할 데이터 나눠서 준비해보도록 하자. 고양이와 개 사진을 분류하기 위해 고양이, 개 사진을 준비한다면 디렉터리(폴더) 구조는 다음과 같을 것이다.
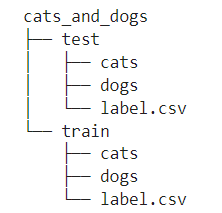
본 분석에선 train의 cats, dogs 사진 각각 4,000장, test의 cats, dogs 사진 각각 1,000장, 총 10,000개의 사진 데이터를 준비했다.
2) 분석 환경 준비
자 이제 늘 해왔듯이 Jupyter Notebook(or Jupyter Lab)을 켜보자. 아니, 켜지 마라. 성능이 준수한 딥러닝 모델을 만들기 위해선 이제부터 당신의 로컬 컴퓨터, 노트북 같은 것따위론 어림없을 수 있기 때문이다. 로컬 성능에 자신이 있다면, 주피터 환경에서 작업해도 괜찮지만, 그게 아니라면 Colab을 이용하자. Colab에서 데이터를 다루기 위해선, 구글 드라이브에 데이터를 업로드해줘야 하는데, 이게 꽤 시간이 걸릴 수 있다.
구글 드라이브를 다운로드해주면, 로컬 환경에 구글 드라이브와 연동된 드라이브가 하나 만들어지는 걸 확인할 수 있을 것이다. 거기에 데이터를 올려주면, 데이터를 웹 구글 드라이브에 직빵으로 업로드하는 것보다는 더 빠르게 업로드를 완료할 수 있을 것이다. 완료했다면,
from google.colab import drive
drive.mount('/content/drive')다음 코드를 Colab에서 실행해주자. 그럼,
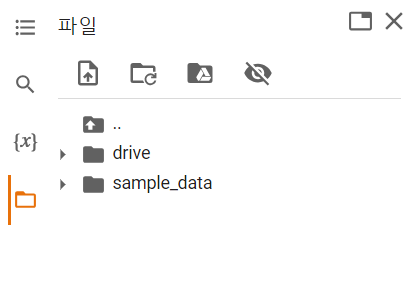
해당 사진처럼 디렉토리 목록에 drive 목록이 추가된 걸 확인할 수 있을 것이다.
2. 데이터 생성
1) 라이브러리
import pandas as pd
from torchvision.io import read_image
from torchvision.transforms import transforms, Resize, RandomCrop,
RandomHorizontalFlip, RandomRotation,
ConvertImageDtype데이터 '소환'을 위해 우선 다음과 같은 라이브러리가 필요하다. 우리의 친구 pandas는 label.csv 파일을 가져오기 위해, read_image는 사진 파일을 RGB 숫자 정보가 담긴 배열 형태로 바꾸기 위해, transforms는 사진에 일정 조작을 가하기 위해 필요하다.
2) CustomImageDataset
딥러닝을 위해 torch 프레임워크를 사용할 건데, torch를 쓰기 위해선 아래 형식과 같은 CustomImageDataset Class가 필요하다.
class CustomImageDataset():
def __init__(self, img_dir, transform=None):
self.img_dir = img_dir
self.img_labels = pd.read_csv(f'{img_dir}/label.csv')
self.transform = transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = f'{self.img_dir}/{self.img_labels.iloc[idx, 0]}'
img = read_image(img_path)
if self.transform:
img = self.transform(img)
label = self.img_labels.iloc[idx, 1]
return img, label생성자로 img_dir, 즉 이미지의 주소값('./drive/MyDrive/cats_and_dogs/train')과 주소값의 labels, 그리고 이미지 변환 파라미터 정보를 담을 transform 변수를 가져와 생성해주자.
그리고 이미지의 크기(데이터 개수)를 리턴해주는 len 함수와 주소값과 이미지 주소('cats/cat_0001.jpg')로 불러온 이미지를 read_image하여 리턴해주는 getitem 함수를 만들어주자.
그런데 각각의 의미를 하나하나 파악하려고 하기보단, 프레임워크를 사용하기 위해서 지켜줘야 하는 일종의 규칙이라고 생각하고 '복붙'해 써주면 되겠다.
3) transform
desired_size = 256
transform = transforms.Compose([
Resize(size=desired_size, antialias=True),
RandomRotation(degrees=(-45, 45)),
RandomCrop(size=desired_size),
RandomHorizontalFlip(),
ConvertImageDtype(torch.float)
])
train_dataset = CustomImageDataset(
img_dir='./drive/MyDrive/cats_and_dogs/train',
transform=transform
)
val_dataset = CustomImageDataset(
img_dir='./drive/MyDrive/cats_and_dogs/test',
transform=transform
)이제 이미지 파일을 변환해줄 transform 파라미터 정보를 담은 변수를 만들어줘야 한다. 일단 desired_size는 이미지 파일 가로/세로 크기를 말한다. desired_size가 256이면 256*256 크기로 사진을 맞추겠다는 뜻이다. desired_size는 Resize, RandomCrop 함수에 쓰인다.
Resize는 가로/세로 중 짧은 곳의 크기를 desired_size로 바꾸고, 다른 곳의 크기를 원 비율에 맞게 바꿔준다는 뜻이다. 512*700 크기의 이미지가 있다면, 짧은 곳인 512를 256으로 줄이고, 700도 원 비율에 맞게 1/2해준 350으로 바꿔준다는 뜻이다.
RandomCrop은 원 이미지의 아무 곳이나 랜덤하게 기준으로 잡고 256*256로 Crop, 즉 잘라준다는 뜻이다. 이 외에 RandomRotation은 이미지의 각도를 조정해준다는 뜻이고, RandomHorizontalFlip은 좌우반전을 랜덤하게 시켜준다는 뜻이다.
ConvertImageDtype은 read_image로 불러온 수치값들의 타입을 바꿔주는 건데, X와 y의 dtype을 맞춰주는 데에 사용한다. 여기선 X가 int, y가 float 타입인데 X를 float타입으로 바꿔준다.
transform 파라미터로는 이 외에도 다양한 함수들을 쓸 수 있는데, 잘 찾아서 용도에 맞게 활용해보도록 하자. 이제 transfrom 파라미터를 적용하여 train, val(test) 데이터셋 객체를 생성해주자.
4) DataLoader
from torch.utils.data import DataLoader
batch_size = 500
train_dataloader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True
)
val_dataloader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=True
)생성한 데이터셋으로 DataLoader 함수를 실행해서 tensor 타입의 데이터로 만들어주면 되는데, 이때 batch 라는 용어가 등장한다. batch는 데이터 학습을 한 번 할 때마다 몇 개의 데이터를 이용할지 정해주는 개념이라고 생각하면 된다. 현재는 500으로 설정을 했는데, 8000개 중에 500개씩 랜덤하게 가져와(Shuffle=True) 학습을 시켜주겠다는 의미이다. batch 사이즈는 GPU든 CPU든 데이터 학습을 돌리는 데에 쓰는 메모리 장치의 성능의 '절반' 정도를 쓰는 수준으로 맞춰주면 된다. 즉, 아직 모델 학습을 실행 안한 지금 단계에선 최적의 batch 사이즈를 알 수 없고, 돌려보면서 맞춰보면 된다는 것이다. 보통은 2의 지수승을 개수로 맞춘다고 하는데, 나는 깔끔하게 딱 떨어지는 걸 좋아해서 500으로 맞췄다.
3. 모델 생성
1) SimpleCNN
import torch
from torch import nn
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(
in_channels=3, out_channels=8,
kernel_size=3, padding='same'
)
self.conv2 = nn.Conv2d(
in_channels=8, out_channels=16,
kernel_size=3, padding='same'
)
self.activation = nn.ReLU()
self.pool = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(in_features=65536, out_features=10)
def forward(self, x):
x = self.activation(self.conv1(x))
x = self.pool(x)
x = self.activation(self.conv2(x))
x = self.pool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return xCNN(Convolutional Neural Network) 모델을 이해하기 위해선 몇 가지 용어들에 대해서 알아둬야 한다. 우선 CNN 뿐만 아니라 모든 딥러닝 모델에서 공동으로 채택하고 있는 '신경망 구조'에 대한 이해가 필요하다.
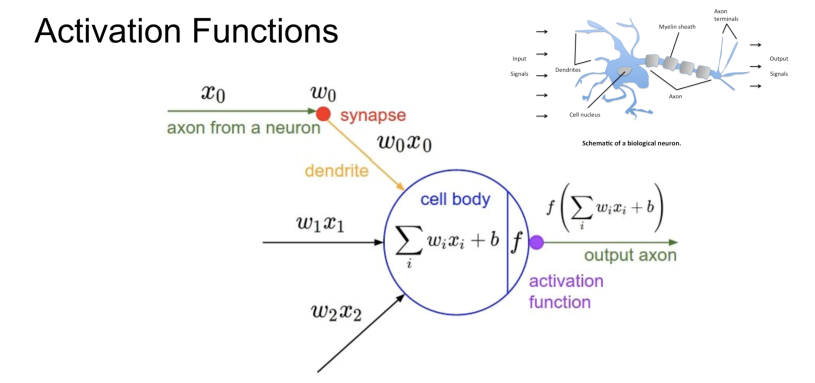
인간의 신경세포(뉴런)는 전기 신호를 입력 받아서 몇 가지 조작을 거친 후 조건에 맞다면 다음 신경세포에 가공한 전기 신호를 출력하는 구조로 이루어져 있다고 한다. 이 구조를 본따서 통상의 딥러닝 모델이 만들어졌는데, 먼저 어떠한 기준에 따라 랜덤하게 초기화된 독립 변수들의 여러 가중치(weight)값을 입력으로 받는데, 입력을 받을 때에 일정한 식(보통은 선형회귀식)을 거쳐 가중치값들을 계산해주고 이를 더한 값을 활성화함수를 통과시켜주면서, 출력을 하는 형태를 띄게 된다. 이렇게 독립 변수 각각에 대한 가중치가 구해지면, 원래의 값과 에러를 계산해 그 차이가 발생한 지점의 가중치를 조절해준다. 그리고 이를 반복하면서 가중치를 조절하면서 최적의 가중치로 모델을 수정해나가는 게 통상의 딥러닝 모델이 만들어지는 방식이다. 이를 BackPropagation, 즉 역전파 방식이라고 한다.
CNN 또한 이 방식을 채용하는데, 이미지 파일을 조작해주는 방식에서 특징적이다. Convolution 기법을 채택하는데, 이 방식은 이미지에 Kernel이라는 필터를 Padding(간격)에 맞춰 적용하거나, Pooling이라는 방식을 이용하는 등 이미지의 특징을 뽑아내는 방식이다. 각각에 대한 자세한 설명은 타 게시글에 넘기겠다.
그럼 class의 구조를 살펴보자. class의 구조는 간단하다. 생성자를 통해 함수를 만들고 forward를 통해 데이터를 '전진파'로 통과시키겠다 뜻이다. 즉, __init__에서 함수를 만들어 그 함수로 forward에서 작업하겠다는 의미이다. 다른 건 다 알겠는데, activation의 ReLU가 뭔지 추가로 설명하겠다. ReLU는 활성화함수의 일종으로 값이 0보다 작으면 0을, 1보다 크면 1을 곱하게 하는 비선형 함수이다. 이 활성화함수를 씀으로써 역전파 가중치 조절로 인해 발생하던 이른바 '기울기 소실' 문제가 상당 부분 해결이 되었는데, 이에 대한 설명은 역시 타 게시글을 참고하시길!
2) 하이퍼 파라미터(Hyper Parameter)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SimpleCNN().to(device)
learning_rate = 0.001
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
criterion = torch.nn.CrossEntropyLoss()
epochs = 10모델도 만들었고 이제 본격적으로 모델 학습을 진행해볼 건데, 그 전에 몇 가지 하이퍼 파라미터를 설정해줘야 한다. 간단하게 설명하자면, learning_rate는 역전파 알고리즘을 통해 기울기를 조절할 때, 기울기를 어느 정도 조절할 건지 설정해주기 위한 값이다. 작을수록 미세하게 조절해주겠다는 의미이다. epochs는 모델 학습을 몇 번을 돌려줄 건지 설정해주는 값이다. criterion는 학습된 모델의 Loss(오차)가 몇인지 판단할 지표를 설정해주는 것이다. 여기선 Cross Entropy를 썼다. optimizer는 기울기 하강을 할 때 쓸 기법을 설정해주는 것인데, 자세한 건 생략하지만 현재는 'Adam'이라는 기법이 굉장히 잘 쓰이며, 성능적으로도 우수하다는 정도만 알아두면 되겠다.
여기에 Colab이라서 추가된 게 있는데, Colab에서 제공하는 gpu 가속을 쓰기 위해서 device라는 메서드를 사용해줘야 한다. 원래는 'cpu' 즉 로컬의 cpu를 사용하는 게 기본인데, 이렇게 되면 처음에도 언급했듯 정말 느리며, Colab을 사용하는 의미가 없다. 아무튼 위 코드처럼 설정해주면 Colab의 gpu를 사용해서 더 빠르게 학습을 수행할 수 있다.
4. 모델 학습
import numpy as np
from tqdm import tqdm
from sklearn.metrics import accuracy_score
from collections import defaultdict
from matplotlib import pyplot as plt
def get_mean(metrics):
return round(sum(metrics) / len(metrics), 4)
def train_model(model):
model.train()
loss_list = []
acc_list = []
for x_train, y_train in tqdm(train_dataloader):
x_train = x_train.to(device)
y_train = y_train.to(device)
outputs = model(x_train)
loss = criterion(outputs, y_train)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
pred = torch.argmax(outputs, dim=1)
acc = ((y_train == pred).sum() / len(y_train)).item()
acc_list.append(acc)
return get_mean(loss_list), get_mean(acc_list)
def validate_model(model):
model.eval()
loss_list = []
acc_list = []
for x_val, y_val in tqdm(val_dataloader):
x_val = x_val.to(device)
y_val = y_val.to(device)
with torch.no_grad():
outputs = model(x_val)
loss = criterion(outputs, y_val)
loss_list.append(loss.item())
pred = torch.argmax(outputs, dim=1)
acc = ((y_val == pred).sum() / len(y_val)).item()
acc_list.append(acc)
return get_mean(loss_list), get_mean(acc_list)
def train_validate_model(model):
logs = defaultdict(list)
for epoch in range(epochs):
train_loss, train_acc = train_model(model)
val_loss, val_acc = validate_model(model)
logs["train_loss"].append(train_loss)
logs["train_acc"].append(train_acc)
logs["val_loss"].append(val_loss)
logs["val_acc"].append(val_acc)
print(f"epoch {epoch + 1}
train - loss: {train_loss} acc: {train_acc}
val - loss: {val_loss} acc: {val_acc}")
return logs
def plot_logs(logs):
fig = plt.figure(figsize=(10, 4))
ax0 = fig.add_subplot(1, 2, 1)
ax0.plot(logs["train_loss"], label="train")
ax0.plot(logs["val_loss"], label="val")
ax0.legend()
ax0.set_title("loss")
ax1 = fig.add_subplot(1, 2, 2)
ax1.plot(logs["train_acc"], label="train")
ax1.plot(logs["val_acc"], label="val")
ax1.legend()
ax1.set_title("accuracy")
plt.legend()갑자기 이게 왠 코드의 향연인가 싶겠지만, 당황하지 않고 하나하나 해석해보면 전혀 어렵지 않다. 학습하고 나서 loss 계산하고 정확도(accuracy) 계산한 걸 logs 변수에 저장해서 그걸 시각화하겠다! 그것 뿐이다. 이 함수를 이용해 모델을 학습해주자.
5. 결과
logs = train_validate_model(model)
나와 파라미터를 똑같이 설정했다면, 이렇게 얼추 30~40분 정도 시간이 걸릴 것이다.
plot_logs(logs)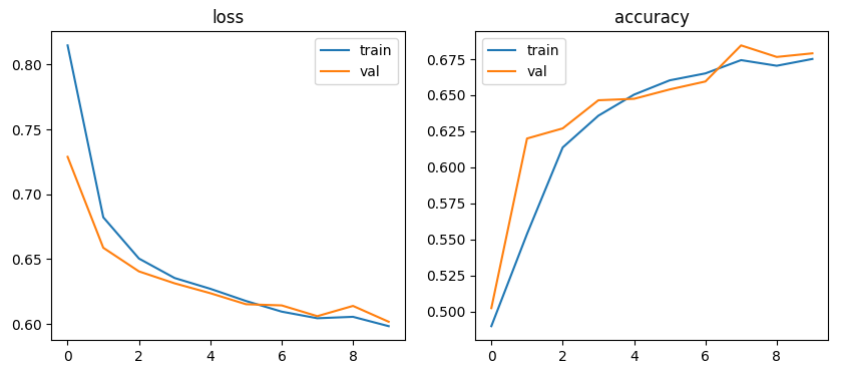
정확도는 그래프에서 보는 것처럼 0.67 정도로 나올 것이다. desired_size를 낮추면, 즉 이미지 파일의 크기를 줄이면 정확도는 더 낮아지는데, 이처럼 다른 파라미터들을 만져주면서 성능(정확도)를 조절해줄 수 있다. 최적의 성능을 만들기 위해 통상의 기준을 활용해줄 수도 있고, Grid Searching 해볼 수도 있으며, 다른 모델의 파라미터를 애용해볼 수도 있다.
6. 마치며
미래의 데이터 전쟁은 본격 이론이 아닌 소재 싸움이 될 것으로 보인다. 누가누가 더 짱짱센 성능을 발휘할 수 있을 것인가 싸움. 그런 의미에서 LK99 초전도체 이슈가 내 마음을 설레게 했었고 많은 아쉬움을 남긴 것 같다.

잘 봤습니다. 좋은 글 감사합니다.