
0. 들어가며
고양이. 귀엽다. 강아지. 역시 귀엽다. 마음껏 사랑을 표현할 수 있는 우리 인간들의 영원할 반려 개체들. 사진도 마음껏 찍어놓을 수 있다. 동거묘, 동거견이 있을 경우, 우리들의 폰 갤러리는 그들의 사진과 사랑으로 가득할 것이다. 그러다 문득, 우리의 동거묘, 동거견과 비슷하게 생긴 친구들이 있는지 알아보고 싶은 마음이 생긴다. 방법은 간단하다. 구글 이미지 검색창에 사진 한 장 띡 업로드해주면 바로 우리들의 구글구글이 그와 유사한 사진들을 뿅뿅 찾아다 준다. 그런데 사진 검색은 어떤 과정을 통해 이뤄지는 것일까? 갑자기 궁금증이 생겨난다.
사진 검색의 아이디어의 핵심은 간단(?)하다. 사진을 수치화하는 것이다. 무수히 많은 양의 사진들을 미리 수치화해놓고, 내가 검색창에 올려놓고 싶어하는 사진 또한 수치화한 후, 미리 수치화해놓은 무수히 많은 양의 사진들과 쭉~ 비교해보고 그 중 가장 유사한 수치값을 가지고 있는 사진을 뽑아다주면 된다.
와~ 정말 간단하네요~ 시간은 엄청 오래 걸릴 거 같긴 하지만요!
그렇다, 무수히 많은 양의 모든 사진들과 일일이 검색 때마다 비교하려면, 매번 많은 시간과 트래픽이 소모될 것이다. 하지만 우리의 닝겐들은 이 문제를 이미 해결해놓은 데에 성공했다. 오늘은 도대체 사진을 어떻게 수치화한다는 것이냐에 대한 궁금증과 어떻게 빠르게 이 과정들을 처리해낼 것이냐 하는 궁금증을 간단하게 딥러닝을 통해 모델을 만들어보고 데이터베이스 사이트에 사진을 업로드해보고 검색 서비스를 만들어보는 것까지 실습해보면서 풀어보도록 하겠다.
1. 모델 생성
데이터 및 CNN에 대한 기초 설명은 위의 링크를 참고해주길 바란다. 우린 이 데이터를 수치화, 아니, 벡터화해서 사용할 것이다. 벡터화하는 과정에 딥러닝 모델을 만들어야 하는데, 아니 선생님, 딥러닝을 훌륭하게 해내는 모델을 어느 세월에 우리가 만들고 있나요? 그렇다, 우린 괜한 세월을 들일 필요가 없다. 이미 우리보다 똑똑한(적어도 딥러닝 계열 쪽으로는) 분들이 열심히 만들어놓은 모델을 쓰면 된다. 그 분들이 만들어둔 모델 아키텍처, 가중치를 그대로 끌고 와서, 모델 학습을 진행하는 동안 약간의 변경만 해주면 된다.
1) Colab, 파이참, 그리고 Cloud Storage
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')'넌 고양이니 개니?'에서 했던대로, 이번에도 Colab을 쓸 것이다. Colab의 성능 좋은 gpu를 쓰기 위해선 데이터/모델 변수들을 Colab device 환경으로 보내줄 필요가 있다. 그때 쓰기 위해 torch.device 객체를 먼저 생성해두자.
구글 드라이브에 마운트하고, cats_and_dogs에 접근할 수 있는지까지 확인하자.
그리고 파이참을 미리 준비해두자. 나~중에 쓸 건데, 나중에 없다는 걸 확인하고 파이참 다운로드 하려면 아무래도 '진'이 빠져서 너무 힘들어질 수 있기 때문이다. 커뮤니티 에디션, 즉 무료 버전으로 깔아두면 된다.
Cloud Storage는 비정형 데이터를 올려두고 외부에서 접근이 용이하게 설정해놓을 수 있는 사이트이다. 고양이와 개 사진 파일을 업로드해놓자. '넌 고양이니 개니' 사이트에서 만들어둔 디렉토리 아키텍처대로 업로드해놓으면 될 것이다.
2) 데이터 생성
import torch
from torch.utils.data import Dataset
import pandas as pd
from torchvision.io import read_image
from torchvision.models import ResNet18_Weights
from torch.utils.data import DataLoader
class CustomImageDataset(Dataset):
def __init__(self, img_dir, transform=None):
self.img_dir = img_dir
self.img_labels = pd.read_csv(f"{img_dir}/label.csv")
self.transform = transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = f"{self.img_dir}/{self.img_labels.iloc[idx, 0]}"
img = read_image(img_path)
if self.transform:
img = self.transform(img)
label = self.img_labels.iloc[idx, 1]
return img, label
weights = ResNet18_Weights.IMAGENET1K_V1
transform = weights.transforms(antialias=True)
train_dataset = CustomImageDataset('./cats_and_dogs/train', transform=transform)
val_dataset = CustomImageDataset('./cats_and_dogs/val', transform=transform)
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=64)
label_dict = {'0': 'cat', '1': 'dog'}이전 링크에서 했던 것처럼 train_dataloader, val_dataloader를 만들어주자. 이때, 우리는 이번엔 우리보다 똑똑하신(아마도) 분들이 만들어 둔 가중치(weights), 전처리 과정(transform)을 가져와 사용하기로 했으니, ResNet18_Weights의 IMAGENET1K_V1 weights 값으로서 가져오고, 이 weights에서 사용한 transform 과정을 transform 값으로 가져와주자.
transforms의 파라미터로 antialias=True가 들어가 있는데, 이 뜻은 높은 해당도의 사진을 낮출 때 일어날 수 있는 왜곡 현상을 최소화해주겠다는 뜻이다. 이 파라미터를 사용하지 않으면, 학습 과정에서 오류 메세지가 생겨 당혹스러워질 수 있다.
from matplotlib import pyplot as plt
def plot_batch(batch, label_dict, cmap=None):
img_tensor_batch = batch[0][:8]
label_batch = batch[1][:8]
fig, axes = plt.subplots(2, 4, figsize=(12, 6))
for i, ax in enumerate(axes.flat):
img_tensor = img_tensor_batch[i]
img_array = img_tensor.numpy().transpose(1, 2, 0)
ax.imshow(img_array, cmap=cmap)
ax.set_title(f"{label_dict[str(label_batch[i].item())]}")
for batch in train_dataloader:
plot_batch(batch, label_dict)
breakbatch를 하나 뽑아 앞의 8개의 사진들로 그래프를 만드는 코드이다. 이 코드로 dataloader가 잘 만들어졌는지 확인해주자. 전처리가 된 후의 사진이므로 크기도 일정하고 화질이 살짝 발화된 느낌일 것이다.
3) 모델 생성 함수
from collections import defaultdict
import numpy as np
from tqdm import tqdm
from sklearn.metrics import f1_score
def get_mean(metrics):
return round(sum(metrics) / len(metrics), 4)
def train_model(model):
model.train()
for x_train, y_train in tqdm(train_dataloader):
x_train = x_train.to(device)
y_train = y_train.to(device)
outputs = model(x_train)
loss = criterion(outputs, y_train)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
def validate_model(model):
model.eval()
f1_score_list = []
for x_val, y_val in tqdm(val_dataloader):
x_val = x_val.to(device)
y_val = y_val.to(device)
with torch.no_grad():
outputs = model(x_val)
pred = torch.argmax(outputs, dim=1)
f1_score_val = f1_score(pred.cpu().numpy(), y_val.cpu().numpy(), average="weighted")
f1_score_list.append(f1_score_val)
return get_mean(f1_score_list)
def train_validate_model(model):
savedir = "./drive/MyDrive/cats_and_dogs"
for epoch in range(epochs):
train_model(model)
val_f1_score = validate_model(model)
torch.save(
model.state_dict(),
f"{savedir}/resnet18_finetune_{epoch + 1}_{round(val_f1_score, 4)}.pth"
)저번 모델 학습 함수와 차이는 모델 성능 측정 지표를 accuracy_score에서 f1_score로 바꾼 것과, 매 에포크마다 모델의 가중치값을 따로 파일(.pth)로 만들어줬다는 것이다.
우선 accuracy를 f1_score로 바꾼 것은 모델의 성능을 더 엄밀히 보고자 함이다. 데이터가 불균형할 경우, 그러니까 cats와 dogs의 비율이 8:2, 9:1 정도 될 경우, 모든 예측을 데이터가 많은 쪽으로 해버려도 데이터를 정확히 맞힐 확률(accuracy)은 각각 80%, 90%가 된다. 이 경우, dogs에 대한 예측 정확도는 0%인데도, accuracy가 좋으니 좋은 모델이라고 해버리는 우를 범할 수 있다. 이런 문제를 보안하기 위한 성능 측정 지표가 바로 f1-score이다. 정밀도, 재현률 따위를 계산해서 조합 평균낸 값인데, 데이터가 불균형해도, 데이터가 적은 쪽에 대한 적중률까지 고려할 수 있는 지표이다. 본 분석에서 사용된 cats_and_dogs는 완벽히 5:5 비율의 균형적인 데이터긴 하지만, 어디 이 모델 함수를 cats_and_dogs 데이터에만 쓸 것인가? 미리미리 더 좋은 걸로 바꿔놓아야지!
그리고 매 에포크마다 f1_score를 측정해서, 모델 가중치를 파일로 저장해놓은 이유는, 이렇게 해야 매번 모델 학습을 새로 진행할 필요 없이, 새로 더미 모델을 만들어 가중치값만 불러와 적용시키는 것으로 귀찮은 공정을 시원하게 해결해버릴 수 있기 때문이다. 또한, 에포크를 돌때마다 항상 더 좋은 모델이 되는 것이 아니기 때문에, 에포크를 돌면서 완성된 중간중간의 모델 중 성능 측정 지표가 가장 좋은 것을 '간편하게' 다시 가져와 쓸 수 있기 때문이다.
4) 모델 학습
from torchvision.models import resnet18
model = resnet18(weights=weights)
for param in model.parameters():
param.requires_grad = False
# for param in model.layer4.parameters():
# param.requires_grad = True
model.fc = torch.nn.Linear(in_features=512, out_features=2)
model = model.to(device)
learning_rate = 0.001
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
criterion = torch.nn.CrossEntropyLoss()
epochs = 10
train_validate_model(model)ResNet18_Weights는 당연하게도 resnet18 모델을 이용하는 데에 쓰이는 가중치이다. weights 파라미터로 적용시켜준 후, 밑에 for문을 다 생략하고 돌려도 물론 상관 없다. 하지만...
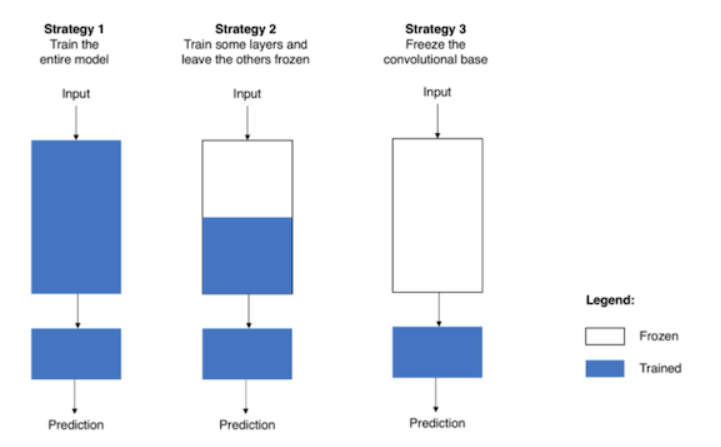
for문을 다 생략하고 돌릴 경우, 위 사진의 Strategy1 전략으로 학습을 수행하게 된다. 이럴 경우, 모든 가중치값들에 대한 학습을 진행하게 되는데, 미리 잘 정립되어있는 가중치를 건드려버리게 되는 것이다. 모든 가중치값을 건드리다 보니 학습 속도도 느려지고. 그렇기에 현업에선 전략1을 잘 쓰지 않는다. 현업에선 전략2나 전략3을 쓰는데, 둘 다 가중치의 일부만 업데이트되게 설정을 해놓고 학습을 돌리는 전략이다. 가중치를 고정해놓는 것을 얼려둔다고(frozen) 표현한다. 데이터가 충분할 경우 보통 전략2를 사용하고 데이터가 적을 경우 전략3을 사용한다. 둘의 차이는 가중치를 얼마나 건드리냐인데, 전략2의 경우 그래도 일부라도 레이어를 건드리고, 전략3의 경우 맨 마지막 출력층(보통 Fully Connected 하는)만 건드린다.
우리 코드에선 전략2를 사용했다. 일단 모든 파라미터에 대해서 param.requires_grad = False 로 고정을 하고 model.layer4.parameters()의 파라미터들만 다시 param.requires_grad = True 로 고정을 푼 것이다. 그리고 model.fc = torch.nn.Linear(in_features=512, out_features=2)를 통해 fc층의 out_features를 데이터의 범주 수에 맞게 조정해준 '새로운' 모델 파라미터를 끼워넣어줌으로써 파라미터 고정(지옥)에서 벗어났다.
여기서 전략3으로 전략을 바꾸고 싶으면 어떻게 하면 되겠는가? layer4 파라미터 고정 해제 for문을 없애주면 된다. 전략1로 전략을 바꾸려면? 굳이 말 안해도 우린 알 수 있다.
우리 학습 데이터는 총 8,000개로 그 양이 그리 많은 편이 아니다. 고로 전략3을 사용하기로 한다. 이렇게 만들어 준 후, 모델을 colab 환경에 보내줘야 한다. to(device) 메서드로 이를 이행해주자.
하이퍼 파라미터에 대한 설명은 이전 링크를 참고하자. 자, 이제 코드를 실행해서 모델 파일(.pth)가 생성되는 것을 확인해보자. 그리고 그 중 가장 f1_score가 높은 모델 파일 하나를 찜해놓아라.
2. 임베딩 벡터
1) 모델 불러오기
model = resnet18()
model.fc = torch.nn.Linear(in_features=512, out_features=2)
weight_path = '모델 파일 경로'
weight = torch.load(weight_path, map_location=device)
model.load_state_dict(weight)
model = model.to(device)
model.eval()더미 모델을 하나 만들어 주고, fc의 out_features만 범주 개수에 맞게 조절해준 다음, weight 값을 다시 적용시켜주면 된다. 아까 만든 10개의 모델 파일 중 f1_score가 가장 높은 모델 파일의 경로를 weight_path에 넣어주고, 코드를 돌려주자. 각각에 대한 설명은 생략한다.
2) 임베딩 벡터화
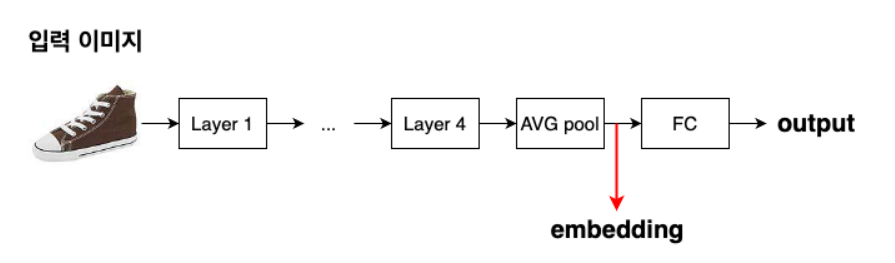

임베딩 벡터란 딥러닝 '전진파 학습'을 거치며 만들어진 배열이라고 이해하면 될 것이다. 우리 분석에서 사용될 임베딩 벡터는 원래는 3(rgb 차원)*224(세로 픽셀)*224(가로 픽셀) 이었던 이중 배열을 512크기의 배열로 추상화해 만들어진 배열이다. 맨 마지막에 0이냐 1이냐 값을 내기 직전의 배열. 뭐 물론 꼭 이때의 배열을 사용하지 않으니 자유롭게 어떤 단계에서의 배열을 쓸지 정해도 된다. 하지만, 가장 추상화가 많이 이뤄졌으며 그 크기도 무난하므로 나는 이때의 배열을 임베딩 벡터로 사용하겠다. 아무튼 이제 이 형식의 벡터끼리 연산을 진행하고 유사도를 측정하고 다 하는 것이다.
intercepted_embeddings = []
def hook_fn(module, input, output):
embedding = torch.flatten(output, start_dim=1)
intercepted_embeddings.append(embedding)
model.avgpool.register_forward_hook(hook_fn)먼저 임베딩을 hook해오는 함수를 만들어주자. 그리고 그 함수를 hook 해올 층에 걸어주자. avgpool은 model을 열어 확인해보면 fc 바로 이전의 layer이다.
import csv
with open('csv파일 저장할 위치/embeddings.csv', 'w') as fw:
writer = csv.writer(fw)
writer.writerow(['path', 'embedding', 'label'])
for images, labels, paths in train_dataloader:
intercepted_embeddings = []
with torch.no_grad():
images = images.to(device)
outputs = model(images)
embeddings = intercepted_embeddings[0]
for path, embedding, label in zip(paths, embeddings, labels):
embedding = embedding.cpu().tolist()
writer.writerow([path, embedding, label.item()])
for images, labels, paths in val_dataloader:
intercepted_embeddings = []
with torch.no_grad():
images = images.to(device)
outputs = model(images)
embeddings = intercepted_embeddings[0]
for path, embedding, label in zip(paths, embeddings, labels):
embedding = embedding.cpu().tolist()
writer.writerow([path, embedding, label.item()])이렇게 만들어진 파일 경로, 임베딩 값, 라벨을 csv에 저장해주자. model이 eval(), 즉 평가모드이므로 학습은 이뤄지지 않고 평가만 이뤄진다. 평가가 이뤄질 때 intercepted_embeddings에 임베딩 값이 들어가고 그 값을 넣어준 후, 다음 batch 때 intercepted_embeddings를 다시 비워주고 반복이다. train, val 안 가리고 모두 임베딩화하여 넣어주자. 이렇게 만들어준 csv 파일을 데이터베이스 사이트에 올려주면, 검색 데이터베이스를 완성할 수 있다. 아니 그런데 선생님, 데이터베이스 온라인 사이트는 또 언제 만들어주고 있는 답니까... 그런 사이트가 있다 해도 돈을 줘야 하지 않나요...? 아니? 무료로 쓸 수 있는, 우리 데이터 양이면 충분히 무료로 쓸 수 있는 사이트가 있다구!
3) pinecone
pinecone이라는 사이트를 이용하자. 가서 가입해주고 create index 눌러서 index 생성해주자. 이때 dimension은 임베딩의 차원(우리의 경우 512가 되겠다)으로 설정해주자. 나머지는 모두 기본 설정으로 해주면 되는데, Metric은 유사도 판정을 무엇을 기준으로 할 것이냐를 설정해주는 것이다. Cosine이 기본값인데, 코사인 유사도는 실제로도 많이 쓰이는 지표인 만큼 그대로 사용해주면 되겠다. 완전 일치하는 사진이 아닌 유사한 데이터를 긁어옴으로써 연산량이 크게 줄어든다고 한다. index를 완성해준 다음에, 우리의 작업 환경과 pinecone 사이트를 연결해주면 되는데, 완성해주고 해당 인덱스의 connect를 눌러보면 다음과 같이 뜰 것이다.
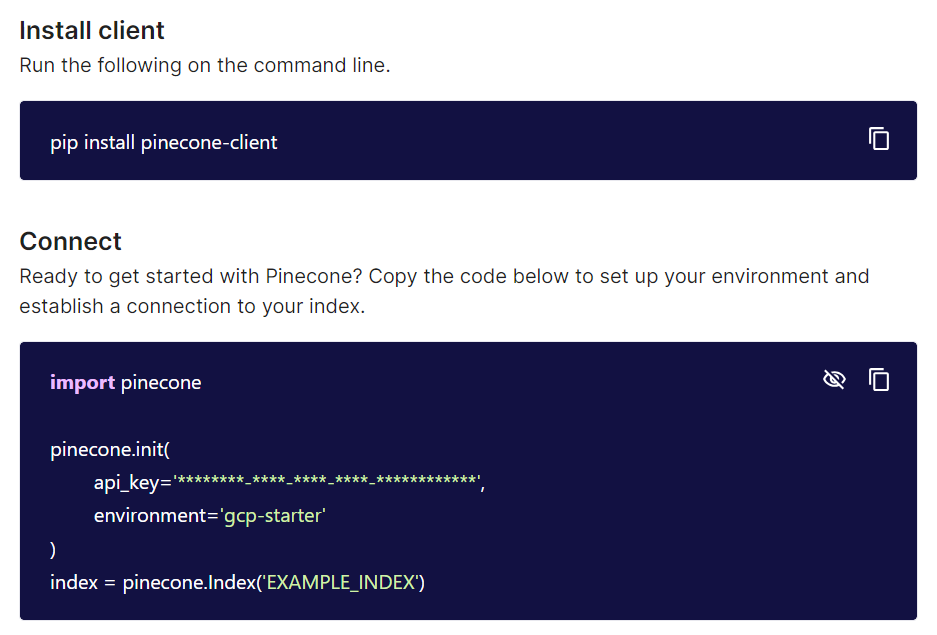
그대로 복붙해주면 된다. 이때 저 api_key는 보호 처리되어 있는데 복붙이 가능한가 싶겠지만, 오른쪽의 눈 모양을 눌러주면 api_key도 보인다. index는 index 생성할 때 만들어준 index 이름 갖다 붙여 넣어주면 된다. 아니 그런데 선생님, 코드 상에 직접 api_key를 적어두기엔 좀 그러할 거 같은데... 무슨 방법이 없나요? 방법이 있다.
from getpass import getpass
pinecone_api_key = getpass('pinecone api key')해당 코드를 실행하면 입력창이 뜨는데, 거기에 입력해주면 코드 블록에 보이지 않게 개인 정보를 입력해 넣을 수 있다. 이제 연결도 됐으니, csv 파일을 데이터프레임화 해서, 그걸 그대로 pinecone 데이터베이스에 업로드해보자.
import pandas as pd
df = pd.read_csv('embeddings.csv파일 저장한 위치')
batch_size = 32
for i in range(0, len(df), batch_size):
batch_df = df[i:i+batch_size]
vectors = []
for j in range(len(batch_df)):
row = batch_df.iloc[j]
_id = str(row.name)
embedding = eval(row['embedding'])
path = row['path']
label = int(row['label'])
metadata = {
'path': path,
'label': label
}
vectors.append((_id, embedding, metadata))
response = index.upsert(vectors)upsert 메서드는 해당 id에 값이 없을 경우 insert, 있을 경우 upload를 하는 메서드이다. 이제 여기까지 했다면 벡터 데이터베이스 구축까지 완성된 것이다. 그럼 '본격적으로' 이미지 검색 온라인을 배포해볼 것인데, 이때 우리는 streamlit을 사용하기로 한다.
3. 이미지 검색 사이트
파이참을 열자. 그리고 다음과 같이 디렉토리(폴더)를 만들어주자.
cats_and_dogs_streamlit
├── .streamlit
│ ├── .gitignore
│ └── secrets.toml
├── data
│ ├── .gitignore
│ └── 모델 파일
├── app.py
└── model.py모델 파일은 지금껏 썼던 pth 파일 그대로 써주면 되고, secrets.toml엔 중요 정보들 넣어주면 된다. .gitignore를 통해 어차피 나중에 깃헙에 올린다 해도 무시되기 때문에 안심하고 넣어주자.
PINECONE_KEY='~'
PINECONE_REGION='~'
CS_URL='~'app.py이 main 파일이다. model.py에는 우리가 지금껏 만든 임베딩 작업에 필요한 모델 함수 등을 class 형식으로 입력해넣어주면 된다.
import torch
from torchvision.models import resnet18, ResNet18_Weights
class EmbeddingExtractor:
def __init__(self, weight_path=None):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model = resnet18()
self.model.fc = torch.nn.Linear(in_features=512, out_features=2)
# load weight
self.weight = torch.load(weight_path, map_location=self.device)
self.model.load_state_dict(self.weight)
self.model = self.model.to(self.device)
self.model.eval()
# preprocess logic
self.transform = ResNet18_Weights.IMAGENET1K_V1.transforms()
self.intercepted_embedding = None
def _hook_fn(module, input, output):
embedding = torch.flatten(output, start_dim=1).cpu().tolist()[0]
self.intercepted_embedding = embedding
self.hook_handler = self.model.avgpool.register_forward_hook(_hook_fn)
def extract_features(self, image):
image_tensor = self.transform(image).to(self.device)
with torch.no_grad():
outputs = self.model(image_tensor.unsqueeze(0))
probs = torch.nn.functional.softmax(outputs[0], dim=0)
pred = torch.argmax(probs).item()
return pred, self.intercepted_embedding그리고 app.py에는 streamlit 디자인 코드를 넣어주면 된다. streamlit을 어떻게 디자인하는지는 타 게시글을 참고하길 바란다.
import streamlit as st
from model import EmbeddingExtractor
from PIL import Image
import pinecone
st.title("Cats and Dogs Image Search")
@st.cache_resource
def load_model():
return EmbeddingExtractor(weight_path=모델 파일 이름)
@st.cache_resource
def init_pinecone_index():
pinecone.init(
api_key=st.secrets['PINECONE_KEY'],
environment=st.secrets['PINECONE_REGION']
)
index = pinecone.Index(index 이름)
return index
def image_search(label, embedding, k=5):
result = index.query(
vector=embedding,
top_k=k,
# label이 일치하는 사진을 가져오게 함으로써 검색에 소요되는 시간을 대폭 줄일 수 있다.
filter={
'label': label
},
include_metadata=True
)
# 쿼리와 일치하는 데이터 중에서 metadata의 path 정보를 긁어오는 코드
return [x['metadata']['path'] for x in result['matches']]
with st.spinner('Loading model...'):
model = load_model()
index = init_pinecone_index()
uploaded_file = st.file_uploader(label='Upload Image', type=['jpg', 'jpeg', 'png'])
if uploaded_file is not None:
image = Image.open(uploaded_file)
st.subheader('Query Image')
st.image(image)
with st.spinner('Search Similar Images...'):
label, embedding = model.extract_features(image)
image_paths = image_search(label, embedding, k=10)
image_paths = [x.replace('./cats_and_dogs/', st.secrets['CS_URL']) for x in image_paths]
st.subheader('Similar Images')
st.image(image_paths)load_model()을 통해 model.py 코드를 불러오고, init_pinecone_index()를 통해 pinecone과 연결을 시켜준다. 그리고 image_search()를 통해 쿼리를 날려주면 k개의 비슷한 이미지의 경로를 불러온다. 그럼 이 경로를 그대로 이미지화해주면 되는데, 여기서 'CS_URL'이 보일 것이다. 아까 secrets.toml 코드 작성할 때 무심코 넘어갔던 바로 그 url인데, 실제 이미지 파일을 미리 업로드해둔 사이트의 주소이다. 맨 처음 클라우드 스토리지에 이미지 파일을 업로드해뒀다면, 그 링크를 가져와서 여기에 넣으면 된다. 그리고 저장되어 있는 path에서 cats_and_dogs 대신 집어넣으면 바로 연결이 될 수 있게 replace 해주면 된다.
이렇게 코드를 완성했으면 streamlit run app.py를 터미널 창에 입력해보고 잘 실행되는지 확인해보자. 파일을 업로드 할 수 있는 창이 뜰 거고, 그 곳에 고양이나 강아지 사진을 넣으면 그 사진과 비슷한 top_k개, 즉 10장의 사진이 쭉 뜰 것이다.
streamlit 온라인에 실제로 배포할 수 있는데, 이 방법은 타 게시글을 참고하길 바란다. 전혀 어렵지 않다. 깃헙에 폴더를 업로드하고, streamlit 사이트에서 깃헙에 연결만 해주면 된다.
4. 마치며
생성ai 어쩌고 하면서 요즘 나오는 이미지, 텍스트, 사운드, 비디오 등등 대부분의 분야에서 이 임베딩 벡터화 기법이 활용되고 있다. 이미지를 벡터화한 후, 이 벡터와 유사한 텍스트를 긁어오고, 이 텍스트를 조정해주고 다시 벡터화한 후, 이 벡터와 일치하는 이미지를 긁어오고. 느낌 알겠는가? 물론 초대기업들은 매우 커다란 모델로 매우 커다란 데이터를 만지다 보니 방구석에서 우리가 이 과정들을 그대로 재현해내기는 아무래도 한계가 있지만, 단지 기초냐 응용이냐의 차이일 뿐, 우리가 전혀 이해하지 못할 영역의 무언가는 아니다. 이제 우리는 딥러닝 엔지니어링을 못할지언정, 딥러닝 엔지니어들이 뭐라고 하는지 대충은 알아들을 수 있는 수준에 도달했다. 험난한 미래 잘 견뎌나가보자
