0. 들어가며
최근 이상 기후 현상에 의해 국지성 호우와 같은 기상재해가 빈번해지고, 그로 인한 피해도 상당해지고 있다. 기상재해로 인한 피해들은 사전에 미리 알고 대비할 수 있다면 그 피해를 줄일 수 있을 것이다. 우리 팀은 기상재해 예측에 아주 조금이라도 보탬이 되고자 예측 모델을 만들기로 했고, '구름 레이더 합성자료'를 통해 날씨 예측 모델을 만들어보기로 했다. 특정 시점을 기준으로 특정 시점의 1시간 전까지의 5분 간격의 사진(총 12장)을 모델에 fit하면 특정 시점의 1시간 후의 사진(1장)을 predict해내는 모델을 만들기로 했다. 예를 들어 2023년 9월 11일 15시 00분을 기준으로 한다면, 모델에 15시 00분, 14시 55분, 14시 50분, ..., 14시 05분의 사진을 fit하면, 16시의 사진이 뿅하고 predict되는 것이다.
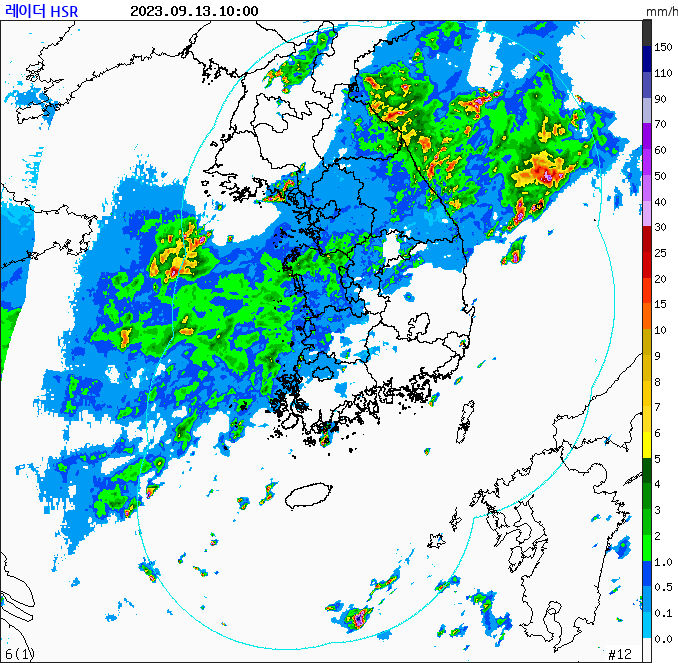
구름 레이더 합성자료는 이런 거다. 위성을 통해 관측한 실제 구름 사진이 아닌, 구름과 강도(강수량)을 측정하여 이렇게 그래픽으로 나타낸 사진이다. 대한민국의 여러 기상 관측소 각각에서 레이더 범위 안의 구름을 관측하고 그걸 다 합성해서 레이더 합성자료라고 한다.
1. 데이터 수집
날씨 데이터는 역시 아무래도 기상청에서 가져와야 한다. 기상청에서 자료를 긁어올 수 있는 방법이 있는지 공공데이터포털부터해서 여러 사이트를 뒤적거린 결과, 기상청 API 허브에서 '레이더' -> '레이더 강수량' -> '레이더합성자료 다운로드' API를 이용하면 된다는 걸 알아냈다. 링크를 보면 알겠지만 기상청 안에서도 데이터 허브가 일원화가 잘 안되어 있는 느낌인지라, 이 루트를 알아내는 데 꽤 애를 먹었다.
그런데 문제가 있다. API를 발급받아서 호출해서 쓰면 수월하게 데이터 수집이 이뤄질 줄 알았는데, API 일일호출시도 수에 제한이 있는 것이었다. 개인 회원은 일일 2,000개밖에 API를 호출할 수 없다. 우리 팀이 상정하고 있는 이미지 데이터 개수가 약 26만 장인데, 하루 2,000개, 우리 팀 3명이니까 하루 6,000개. 이 정도 속도로 어느 세월에 데이터를 가져오겠는가? (이과 특, 여기서 26만 나누기 6천 하고 있음)
그리고 심지어 호출 속도도 복불복이었다. 어쩔 땐 빠르게 잘 되다가도 어쩔 땐 갑자기 뚝 하고 진행이 끊기다시피 해버린다. 이대론 시작도 못해보고 끝날 수 있겠다 싶어 좌절하던 와중에 우리 팀은 길을 찾았다.
- 이미지 URL 직접 접근
기상청에서 레이더 영상(사진이라 안하고 영상이라고 한다)을 홈페이지에 띄울 때 쓰는 이미지의 URL에 직접 접근할 수 있는지, 즉 주소창에 입력했을 때, 날짜만 바꾸면 해당 날짜의 사진이 바로바로 띄워지는지 확인해보았고, 우리의 수요에 맞는 이미지 URL을 찾을 수 있었다. 수집 범위는 2020년부터 2023년까지 각각 6월에서 9월(2023년은 8월)까지다.
2. 데이터 전처리
- 분석에 불필요한 부분 삭제
위에서 본 사진을 다시 보자. 원활한 이미지 분석을 위해선 일단 이 이미지에서 딱히 모델링에 직접적으로 필요한 정보가 아닌 부분은 싹 날려줄 필요가 있다. 위쪽의 사진에 대한 메타 데이터부터, 오른쪽의 범례는 각각의 RGB가 뭘 뜻하는지 알려주는 메타 데이터이므로 분석에서는 활용이 되지 않으니 날려줘야겠다. 그리고 레이더 범위를 표시한 민트색의 선도 없애줄 필요가 있어 보인다. 영상의 테두리도 날려주자. 그럼 다음과 같은 사진이 나온다.

- 이진 처리
이렇게 처리된 유형의 사진을 입력값과 label값에 다 활용해서 모델이 완벽하게 강수량까지 예측하게 하면 좋겠지만, 성능 상의 한계가 우려되어 우리는 label 사진을 좀 더 단순화하기로 했다. 본래 사진은 구름이 24개의 범주를 가지지만, label 사진으로 활용할 땐 특정 강수량을 기준으로 그보다 아래면 일반 강수 지역, 그보다 높으면 호우 지역으로 이진 분류하기로 했다. 특정 강수량 기준을 무엇으로 잡을지도 고민이었는데, '집중호우'의 기준이 '1일 강수량이 연 강수량의 10%인 경우, 또는 한 시간에 30mm 이상의 비가 내리는 경우'인 것을 감안하여, 30mm/h를 기준으로 설정했다. 그렇게 이진 분류한 사진은 다음과 같다.
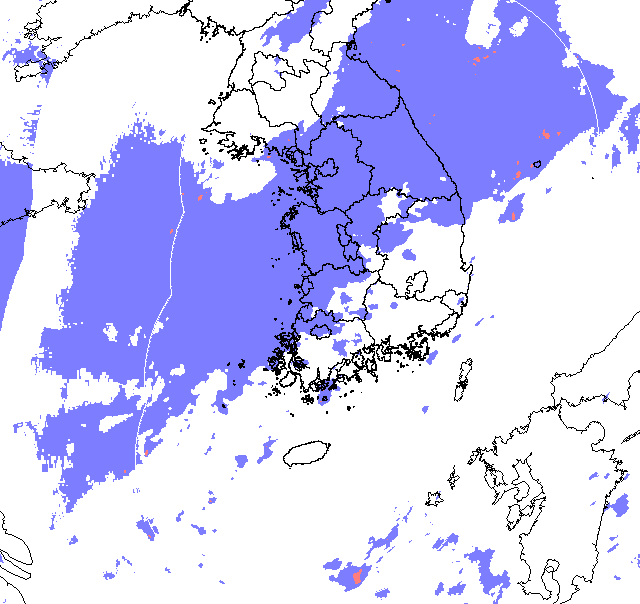
요약하면, 구름을 이진 분류하지 않은 원본(original)은 모델링하는 데에 사용했고, 구름을 이진 분류한 사진(binary)은 Label로 사용했다.
- 데이터 요약
이렇게 처리한 데이터를 그대로 모델에 넣고 수월하게 돌려볼 수 있다면 참 좋겠지만, 처리해야할 데이터가 너무 방대하다. 그래서 우리는 여기서 더 나아가 정규화를 해주기로 했다. 우선 현재는 색상을 표시하기 위해 RGB 3차원을 모두 쓰고 있는데, 그렇게 하기엔 이미지에서 사용하는 색상의 종류가 너무 적다. 즉, grayscaling을 통해 차원을 줄여도 색상 분류에는 전혀 지장이 없을 것이다. 우리는 original의 경우 지형은 100으로, 흰바탕은 0, 구름은 강수량에 따라 1~24까지의 값을 지정해줬다. binary의 경우 지형, 흰바탕은 동일하고 구름은 강수 지역(30mm/h 미만)은 1, 호우 지역(30mm/h 이상) 2로 값을 지정해줬다.
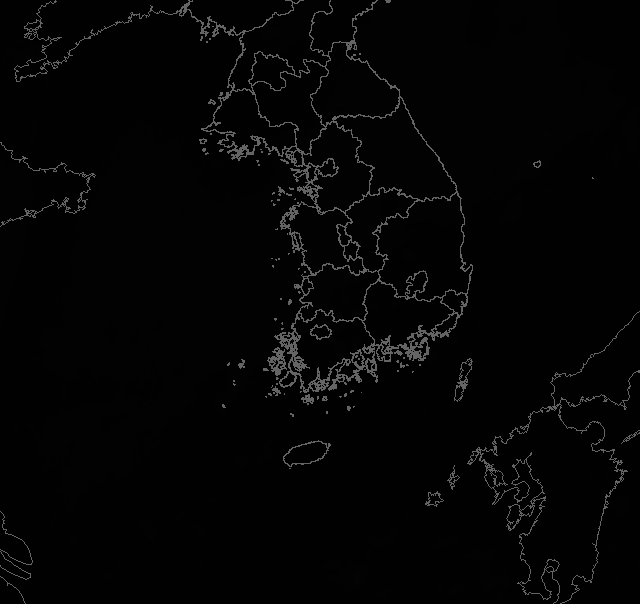
그럼 다음과 같이 지형 말곤 온통 까만 색상의 이미지 파일이 만들어진다. 그런데 png의 경우 값이 0, 1인 경우가 아닌 이상 shape이 (높이, 너비, 3)으로 고정되어서, 픽셀값으로 1이 아닌 [1, 1, 1]로 처리가 된다. 그러나 이는 모델링의 transform 단계에서 다시 '1'로 만들어 차원을 '제거'해줄 수 있다.
- 크기 줄이기
마지막으로 현재 641*625 크기의 이미지를 256*256 크기로 resizing 해준다. 단순한 데이터여서 크기를 줄여서 정보의 손실이 크게 발생하지 않을 것이라는 판단에서 줄여줬다.
여기까지 모든 모델에 공통으로 적용되는 전처리 과정이다. 이후 모델마다 사진의 사이즈를 다르게 한다는 식으로 전처리가 더 들어가기도 하지만, 그것 역시 transform 단계에서 수월하게 처리할 수 있다.
