

Data : https://www.kaggle.com/datasets/olistbr/brazilian-ecommerce
Olist라는 회사에서 공개한 2016~2018년까지 Olist의 이커머스 마켓플레이스 플랫폼의 고객 데이터셋을 분석해보았다. 각 테이블당 데이터가 꽤나 방대해서, MariaDB 기반의 Workbench라는 솔루션을 이용해 데이터베이스를 구축하고, ansi sql을 통해 쿼리를 긁어와 python으로 데이터 분석을 진행하는 식으로 작업했다.
1. ANSI SQL
ANSI SQL(American National Standards Institute Structured Query Language)은 SQL의 표준화된 버전이라고 생각하면 되겠다. SQL은 DBMS가 무엇이냐에 따라 약간씩 문법이 달라지는데, 이로 인한 불편을 해소하고자 표준화된 버전이 만들어진 것이다. 용어에서도 알 수 있듯 미국에서 만들었다.
우선 Olist의 데이터를 Workbench라는 솔루션을 이용해 MariaDB DBMS에 데이터베이스를 구축해보겠다. Workbench라는 솔루션을 다운 받아 connection을 구축하고 SCHEMAS를 만들어 테이블을 생성하기까지의 과정은 다 생략하겠다. 아래 링크를 남겨뒀으니 차근차근 따라하면 금방 사용법을 익힐 수 있을 것이다.
2. 데이터베이스 구축
1) connect
Workbench를 다운 받은 후, Workbench 안에서 자체적으로 쿼리문을 작성해 실행해볼 수도 있겠지만, 그렇게 하면 일단 실행 속도가 느리고, sql 언어만으로의 데이터 분석은 아무래도 pandas나 numpy를 이용하는 것에 비해서 제한이나 불리한 점들이 많기에, 파이썬 환경에서 쿼리문을 실행해 데이터를 불러오고 그 데이터를 dataframe화하여 데이터 분석하는 것이 여러모로 유리하다.
연동 방법은 간단하다. pymysql이라는 라이브러리를 이용해 다음과 같이 connect 함수를 실행해주면 된다.
import pymysql
conn = pymysql.connect(
host="127.0.0.1",
user="root",
password="your connect's password",
database="your schema name",
)위 코드에서 password와 database를 본인의 사양에 맞게 바꿔주자.
2) 테이블 구축
이제 연결을 했으니 데이터베이스에 데이터를 보내주는 작업을 해야하는데, 그 전에 workbench에서 미리 테이블 스키마를 만들어두어야 한다. 아마도 여러분에게 꽤나 친숙할 데이터프레임을 떠올려보자. 거기에서 일단 칼럼을 미리 만들어두고, 그 칼럼의 타입까지(값의 길이까지) 미리 선언해두어야 한다는 것이다.
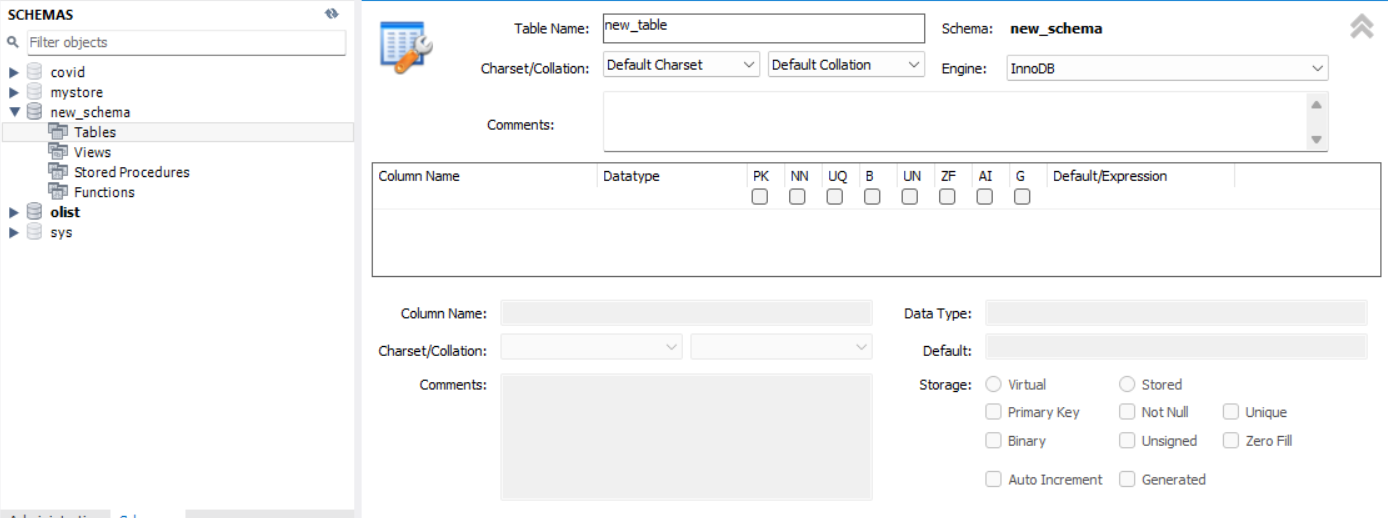
SCHEMAS(new_schema)를 생성하고 밑에 Tables를 마우스 오른쪽 버튼으로 클릭하면 메뉴창이 뜨는데 거기서 create Table를 선택해주면 다음과 같은 창이 뜬다. 여기서 밑에 Column Name과 Datatype을 선언해주어야 한다는 것이다.
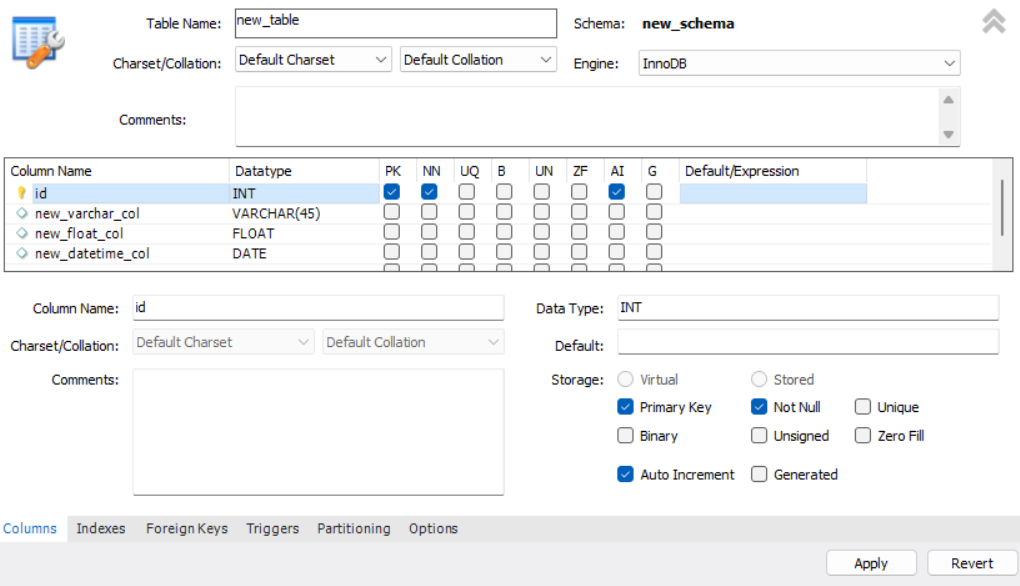
이름과 데이터타입은 사진처럼 입력해주면 된다. VARCHAR가 우리가 잘 알고 있는 string이고 VARCHAR 옆의 (45)는 데이터의 길이를 선언해준 것이다. 파이썬에선 자동으로 조절되기 때문에 크게 유념할 필요가 없는 개념인데, 이렇게 길이를 선언해줌에 따라 데이터가 갖게 되는 용량이 달라짐으로 무작정 크게 설정하기보단 적절한 값을 설정해주는 것이 좋다. 칼럼 옆의 PK니 NN이니 하는 것은 오른쪽 하단의 Storage에 그 뜻이 나와 있는데, 여기서 Auto Increment는 따로 값을 안 주면 자동으로 1부터 값을 부여해주겠다는 뜻이다. PK 설정 시 매우 유용한 설정이므로 꼭 기억해두자.
아무튼 이런 식으로 우리의 Olist 데이터가 들어갈 데이터베이스들을 다 만들어주자. 아니 선생님, 9개의 csv 파일을 다 여기다가 집어넣으라구요? 맞다. kaggle의 데이터 설명 잘 참고해서 만들어두길 바란다. 데이터베이스 처음 만드는 게 힘들지, 한 번 만들어놓고 보면 금방 손에 익어 바로바로 빠르게 진행시킬 수 있다. 겁 먹지 말고 진행시켜라.
3) Bulk_insert
위와 같이 테이블을 생성하는 걸 테이블의 스키마(구조)를 선언한다고 한다. 테이블 스키마 선언이 끝났으면, 이제 거기에 데이터를 채워넣는 작업을 하면 된다. 물론 이것도 workbench 안에서 sql문 날려서 할 수 있지만, 앞서 지적했듯 이렇게 하면 속도가 너무 느리다. 그러니 파이썬을 이용해주자. 앞서 파이썬과 workbench 연결을 완료했다면, 다음과 같이 함수를 선언해주자.
def _execute_insert(insert_sql, buffer):
with conn.cursor() as cursor:
cursor.executemany(insert_sql, buffer)
conn.commit()
def bulk_insert(data_file_path, insert_sql, batchsize=1000):
with open(data_file_path) as fr:
reader = csv.reader(fr)
buffer = []
for i, row in enumerate(reader):
row = [x if x else None for x in row]
if i == 0:
continue
buffer.append(row)
if len(buffer) == batchsize:
_execute_insert(insert_sql, buffer)
buffer = []
if buffer:
_execute_insert(insert_sql, buffer)파이썬에서 workbench로 쿼리를 날리는 원리는 간단하다. conn.cursor()를 통해 '기'를 모아서 conn.commit()으로 '에너르기파'를 쏴주면 된다. 커밋을 날린다고 아마 github를 조금 다뤄본 사람이라면 익숙한 개념일 것이다. 하지만 지금은 몰라도 괜찮다. 기를 모아, 에너르기파를 쏜다, 지금은 대충 이렇게만 이해해놓아도 충분하다.
bulk_insert 함수는 데이터를 batchsize만큼 모아 commit을 날리게 구현되어 있다. 아까 sql문을 쓰면 느리다고 한 이유가, 대용량의 데이터를 한번에 처리하게 되기 때문이었다. 이를 방지하기 위해 1000개씩 끊어서 쿼리를 날리게 구현을 했다. data_file_path의 csv 파일을 읽어와 한 줄 한 줄 buffer라는 리스트에 담아 buffer의 길이가 1000이 되었을 때 _execute_insert 함수를 실행해 데이터를 날리는 쿼리를 쏴주고 이를 반복하다가, buffer에 1000개가 안 찼지만 append가 완료됐다면 마무리로 _execute_insert 함수를 실행하는 로직이다.
insert_sql = "INSERT INTO order_payments(order_id, payment_sequential, payment_type, payment_installments, payment_value) VALUES(%s, %s, %s, %s, %s)"
bulk_insert("./olist/order_payments.csv", insert_sql)함수 선언을 완료했다면 위처럼 코드를 짜서 bulk_insert 함수를 실행해주면 된다. 여기서 insert_sql의 구조를 도식화하면 다음과 같다.
INSERT INTO 테이블(칼럼 전부) values(칼럼 개수만큼 %s)
# 단, Auto Increment 설정된 칼럼은 제외Auto Increment를 만약 설정을 안해줬다면, 해당 칼럼 값으로(보통은 PK 칼럼이다) 1, 2, 3, ... 이런 식으로 일일이 값을 설정해주어야 하는 수고로움이 생긴다.
3. 데이터 읽어오기
데이터베이스를 구축 완료했으니, 이제 데이터베이스를 긁어올 수 있어야 한다.
def read_query(read_sql):
with conn.cursor() as cursor:
cursor.execute(read_sql)
result = cursor.fetchall()
return result
read_sql = sql = """
SELECT
*
FROM
orders
"""
result = read_query(read_sql)
result읽어올 때도 데이터를 write 할 때랑 원리는 비슷하다. 다만 읽어올 땐 fetchall() 함수를 이용한다는 차이만 있을 뿐. 이렇게 쿼리를 읽어오면,
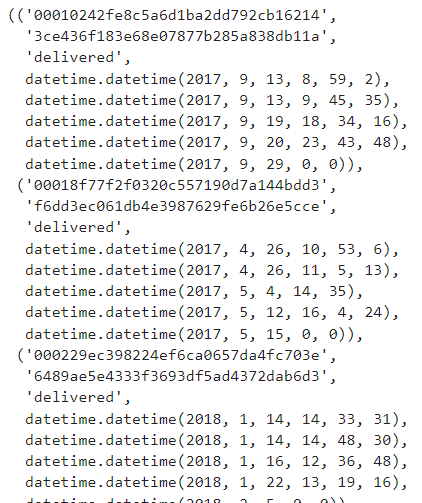
다음 사진처럼 튜플 형식으로 데이터를 긁어오는 걸 확인할 수 있을 것이다. 여기다 pd.DataFrame을 씌운다면?
import pandas as pd
df = pd.DataFrame(result)
df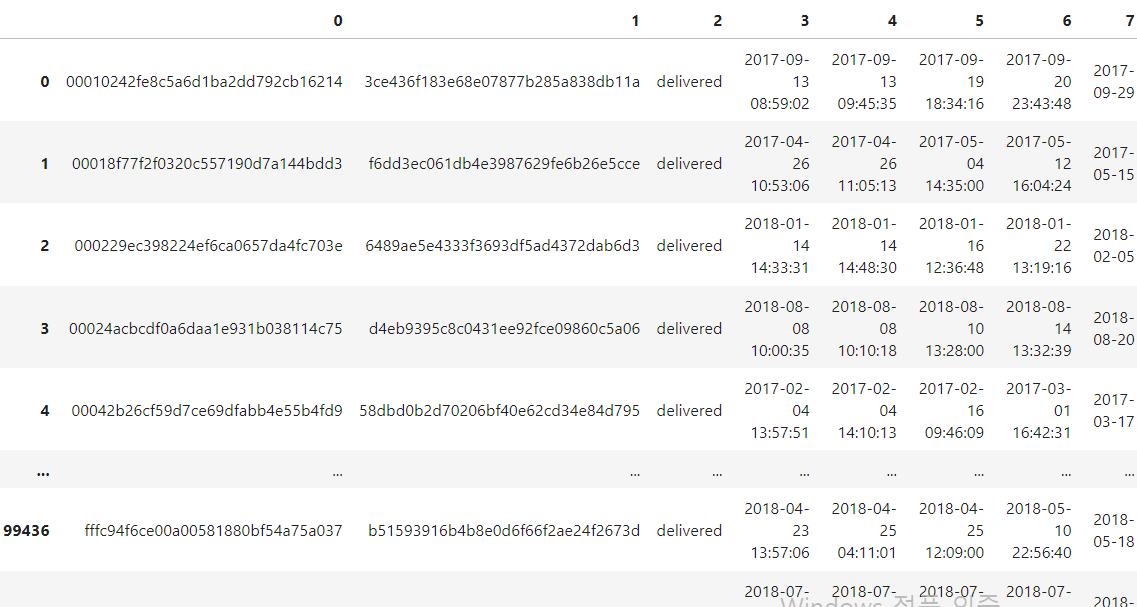
바로 우리에게 너무나도 익숙한 데이터프레임이 만들어지는 것이다! 칼럼명은 뭐... 적당히 다시 지어주도록 하자!
df.columns = ['칼럼1', 'col1', 'col2', ...]이렇게 데이터프레임으로 만들어서 그 후에 데이터 분석을 진행해줘도 되지만, 아니 사실 데이터를 몽땅 불러와서 Pandas 돌릴 거면, 그냥 pd.read_csv()로 불러오는 게 로딩은 조금 있을지언정 훨씬 간편하다. 그렇다면 현업에선 왜 굳이굳이 SQL을 사용하는 것일까? 사실, SQL의 '꽃', SQL을 쓰는 가장 큰 이유, "Join" 같은 데이터베이스 연결/병합 작업에 있어서는 데이터프레임이 아닌 SQL 수준에서 완료해주는 것이 훠얼~씬 이득이기 때문이다. 원활한 Join을 위해 Foreign Key도 설정해주는 작업이 필요한데 이건 이따가 설명하도록 하고 그럼 Join을 이용한 작업 수행의 예시에는 어떤 것이 있는지 직접 가설을 세우고 검증해보는 작업을 해보면서 알아보도록 하자.
4. 가설 검증
1) 개요
택배를 시켰다. 인고의 시간(근데 이제 이틀 정도인) 끝에 문자가 왔다. '택배가 내일 18~20시 사이에 도착 예정입니당~'. 됐다. 끝이 보이니 마음이 한결 편해졌다. 기쁜 마음으로 다음날 퇴근하고 집에 왔는데, 아직 택배가 오지 않았다. '그럴 수 있지!' 밤에라도 와주는 게 어디냐. 그렇게 시간은 20시를 지나 21시, 22시. 하지만 택배는 여전히 오지 않는다. 이게 어떻게 된 거지. 그렇다고 부랴부랴 바로 택배 기사님께 전화 때리기엔 내가 너무 삭막한 현대사회의 흙빛 미세먼지 뒤집어써가며 삶을 연명해나가는 소인배 그 자체로 보일 것 같아 망설여진다. '새벽에라도 도착하겠지.' 그렇게 불안한 마음을 안고 나도 모르는 새에 잠에 들었다 곧 깨어난다. 06시. 하지만 택배는 도착하지 않았다. 잘못 배달됐나...? 배달 완료했다는 문자도 안 왔는데... 왜...지?
위와 같은 상황에 부닥치게 되면, 아마 100이면 99는 배달 리뷰 점수 책정에 있어서 좋지 못한 점수를 주게 될 것이다. 배달 점수만 낮으면 다행이지, 상품 점수까지 안 좋게 주는 지경에 이를 수도 있다. 그냥 차라리 늦게 올 것이지, 괜히 기대하게 만들어서 말이야. 자, 그렇다면 실제론 어떨까?
과연 예고된 날짜에 비해 늦게 도착한 상품들의 리뷰 점수가 그렇지 않은 상품들의 리뷰 점수에 비해 정말 낮을까?
검증해보자.
2) 가설 수립
우리의 가설(연구가설, 대립가설)은 이렇게 될 것이다.
H1(연구가설) : '예고된 날짜에 비해 늦게 상품을 배송받은 고객의 리뷰 점수는 그렇지 않은 집단의 고객의 리뷰 점수에 비해 낮을 것이다.'
기본적인 통계 검증을 배웠다면 연구가설/대립가설, 그리고 귀무가설/영가설에 대해서 알고 있을 것이다. 연구가설은 우리가 검증하고자 하는 가설이고, 귀무가설은 그와 반대되는 가설이다.
H0(귀무가설) : '예고된 날짜에 비해 늦게 상품을 배송받은 고객의 리뷰 점수는 그렇지 않은 집단의 고객의 리뷰 점수에 비해 같거나 높을 것이다.'
통계 검증 상황에선 전통적으로 연구가설이 지지됨을 보이기 위해서 연구가설이 옳을 확률을 보는 게 아니라 귀무가설이 옳을 확률을 본다. 그래서 귀무가설이 옳을 확률이 '충분히', '우연이라고 할 수 없을 정도로' 낮다면, 귀무가설을 기각하고, 연구가설을 채택한다.
왜 굳이 반대 개념을 하나 더 만들어서 헷갈리게 하는 걸까? 에 대해선 이 링크를 참고하길 바란다.
아무튼, 이렇게 귀무가설까지 세웠으니, 검증에 필요한 데이터를 가져와야 하는데 여기서 SQL이 힘을 발휘한다.
3) 데이터 가져오기
sql = """
SELECT
DATEDIFF(
orders.order_estimated_delivery_date,
orders.order_delivered_customer_date
) AS delay,
COUNT(*),
orders.order_estimated_delivery_date,
orders.order_delivered_customer_date,
SUM(order_reviews.review_score)
FROM
orders
LEFT JOIN
order_reviews
ON
orders.order_id = order_reviews.order_id
GROUP BY
delay
ORDER BY
delay
"""
with conn.cursor() as cursor:
cursor.execute(sql)
result = cursor.fetchall()
df = pd.DataFrame(result)
df.columns = [
'DATEDIFF', 'COUNT', 'estimated', 'delivered', 'review_score'
]
df = df.dropna()ANSI SQL이라고 해서 두려워할 건 없고, 사실은 우리가 SQL을 배운다 하면 보통 배우는 게 바로 ANSI SQL, 즉 표준 SQL이다. 그러니 배운대로 그대로 SQL문 작성해주면 되고, 해석도 그대로 해주면 된다. SQL문을 보면, orders와 order_reviews를 left join해주는 sql인 걸 알 수 있다. 그리고 delay라는 열을 새로 생성하여 그걸 기준으로 groupby까지 해주는 걸 확인할 수 있다. 이 pandas로 하려면 복잡한 과정을 sql문 하나로 간단히 처리할 수 있는 것이다. 얼마나 편리한가??
df_copy = df.copy()
df_copy['fast'] = (df_copy['DATEDIFF'] >= 0) + 0
df_copy['review_score'] = df_copy['review_score'].astype(int)
table = df_copy.groupby(['fast'])[['COUNT', 'review_score']].sum()
table['review_mean'] = table['review_score'] / table['COUNT']
table이렇게 긁어온 데이터를 살짝 전처리해주고, 다시 'fast'(택배가 일찍 도착했거나 정시에 도착했을 경우 1, 아니면 0)를 기준으로 'COUNT', 'review_score'를 groupby로 더하여, 나눠주면,
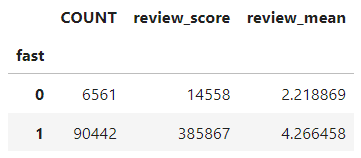
다음과 같은 결과가 나온다. 일단 딱 봐도 택배가 늦게 온 집단(0)의 리뷰 평점 평균이 그렇지 않은 집단(1)의 평균에 비해 확연히 낮은 것을 확인할 수 있다. 그래도, 단순히 인간의 감으로 판단을 끝내서는 통계 검증을 했다고 할 수 없다. 여기서 바로 두 집단의 평균 비교에 사용되는 통계 검정 기법 'T검정'을 사용해주자.
4) T검정
import numpy as np
from scipy import stats
fast_1 = np.array(df_copy[df_copy['fast']==1]['review_score'])
fast_0 = np.array(df_copy[df_copy['fast']==0]['review_score'])
_, p_value_equal_var = stats.levene(fast_1, fast_0)
print("등분산 검정 p-값:", p_value_equal_var)
# 유의 수준
alpha = 0.05
# 등분산 가정은 검정 p값이 유의수준보다 높을 경우 가정을 만족한다고 본다.
if p_value_equal_var < alpha:
print("등분산 가정 : 기각\n")
equal_var = False
else:
print("등분산 가정 : 만족\n")
equal_var = True
# 독립표본 T-검정 수행
t_statistic, p_value = stats.ttest_ind(fast_1, fast_0, equal_var=equal_var)
# 결과 출력
print("T-통계량:", t_statistic)
print("p-값:", p_value, '\n')
# p-값과 유의 수준 비교
if p_value < alpha:
print("귀무 가설 기각 : 연구 가설 채택")
else:
print("귀무 가설 채택 : 연구 가설 기각")
T검정에 대한 자세한 설명은 생략하겠지만, 두 집단은 모집단이 다르므로, 독립표본 T검정을 사용해줬고, 독립표본 T검정에 있어서 등분산 검정의 만족 여부에 따라 검정 방법이 달라지므로 등분산 검정도 우선 수행해주었다.
그 결과, 연구 가설을 채택할 수 있다는 결과가 나왔다. 즉, fast_1의 리뷰 평점 평균이 높다는 건 통계적으로 지지받는 가설임을 확인할 수 있다.
5. 정리
가설을 세우고 SQL을 활용해 데이터베이스에서 데이터를 가져와 가설 검증까지 완료해봤다. SQL은 어렵지 않다. 본 문서에서 사용된 명령어로도 사실 얼마든 원하는 task를 수행해볼 수 있을 뿐더러, 추가로 무언가 더 해보고 싶다면 그냥 검색해보고 찾아서 명령어 하나 살짝 추가해주면 된다. 찾는 것도 요즘은 챗gpt 활용하면 금방 찾을 수 있다. 얼마나 수월한가.
그러나 결국은, 데이터 분석에서 핵심은 어떤 기술이나 언어를 얼마나 능숙하게 쓰냐 보단, 데이터 자체에 대해서 얼마나 잘 이해하고 있냐가 결과물의 퀄리티를 가른다. 데이터에 대한 이해를 위해선 혼자 공부를 해볼 수도 있지만, 현업 종사자 및 관계자들과의 원활한 소통이 거의 모든 면에 있어서 훨씬 효율적이다. 물론 데이터 분석가로서 EDA 등을 수행해 현업자조차 발견하지 못한 인사이트를 새로 추출할 수도 있겠지만, 이것조차 현장의 어려움과 동떨어진 얘기라면 말짱 도루묵일 뿐이다.
