Attention: in equations

- 그리고 나서 이것을 softmax에 넣어 probability distribution을 얻고 next word를 sample한다.
Attention's Advantages
-
Improves NMT performance
- decoder가 source의 특정 부분에 집중할 수 있도록 한 것이 매우 useful하다.
-
Provides more "human-like" model of the MT process
- 번역할 때 다시 source sentence를 뒤돌아보는 사람과 비슷하다.
-
Solves the bottleneck problem
- Decoder가 source를 direct하게 볼 수 있게 하여 bottleneck problem을 우회한다.
-
Helps with the vanishing gradient problem
- Encoder의 모든 hidden state로 가는 shortcuts가 있다. 그래서 gradient flow가 있는 short path가 있어 vanishing gradient problem을 크게 완화한다.
-
Provides some interpretability to sequence to sequence model
- attention distribution을 조사함으로써, decoder가 무엇에 focusing하는지 볼 수 있다.
- alignment system을 명시적으로 훈련한 적이 없는데, network가 alignment를 스스로 학습한다.
Attention variants
Variation을 볼 수 있는 주요한 곳은 attention score를 계산하는 부분이다.
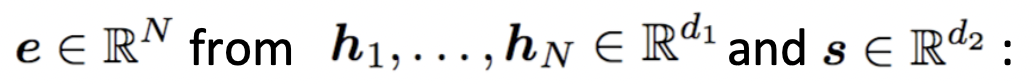
🔗 Basic dot-product attention
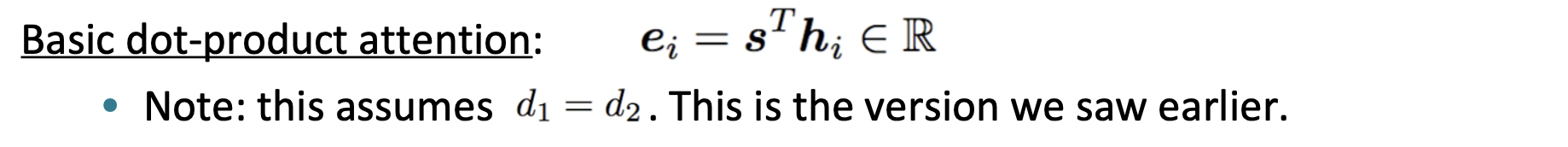
🔗 Multiplicative attention
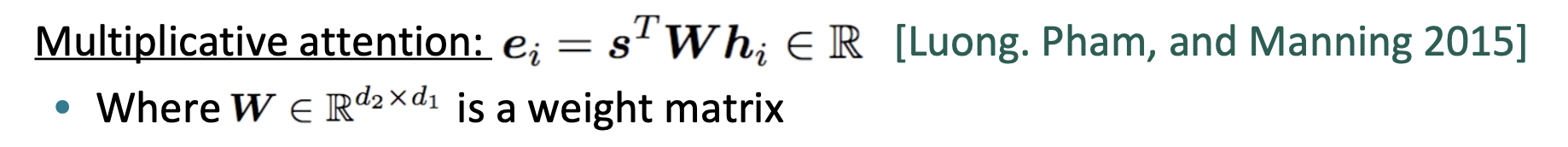
-
배경) Source hidden states와 target hidden states 전체가 모두 어디에 attention해야 하는지에 대한 정보를 가지고 있다고 생각하는 것은 잘못된 것이다. 따라서 attention score를 계산하기 위해 그 안에 있는 정보 중 일부만 사용하려고 한다.
-
W는 matrix of learnable parameters이다.
-
Source hidden state와 target hidden state 사이에 있는 W matrix는 similarity를 계산할 때 s의 어떤 part에 pay attention을 해야하고, h의 어떤 part에 pay attention을 해야하는지 알려준다.
-
문제) W가 많은 parameter를 가지고 있다.
🔗 Reduced rank multiplicative attention
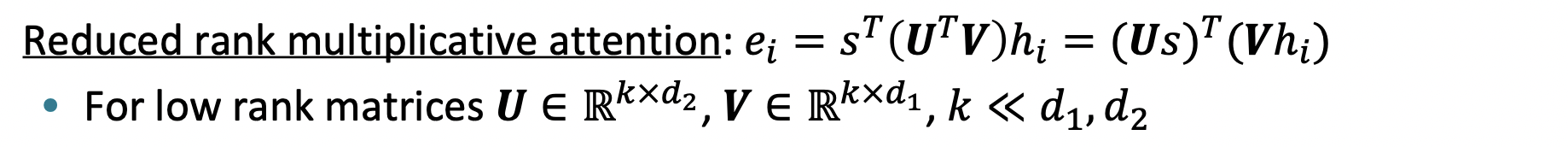
- 배경) 더 적은 parameters를 가지게 하고 싶다.
- W를 UTV로 modeling한다.
- Linear algebra로 식을 정리하면, source hidden vector와 target hidden vector를 각각 low rank linear projection으로 projecting하고, 두 projection을 dot product한 것이다. 이것이 정확히 transformer model에서 일어나고 있는 것이다.
🔗 Additive attention
- Bahdanau가 제안한 것이다.
- Neural net layer를 사용해서 weight(attention score)를 얻는다.
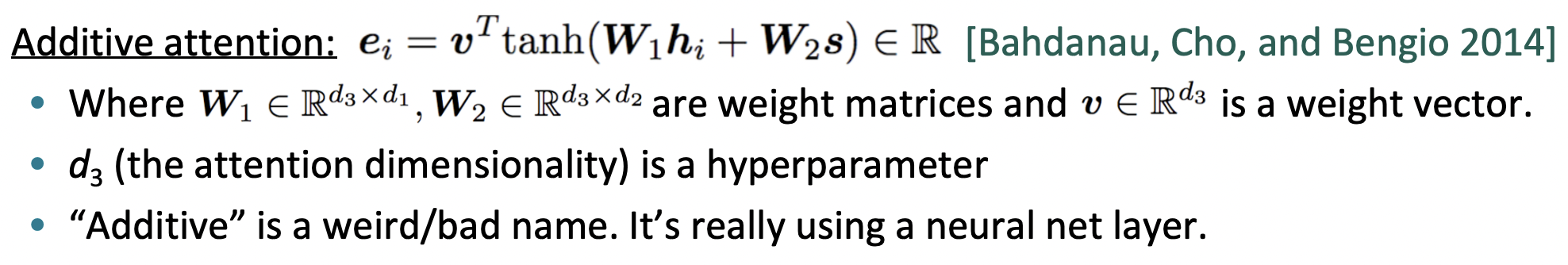
More general definition of attention
-
언제든지 set of vector values, 그리고 a vector query가 주어지면, attention은 query에 따라 값의 weighted sum을 계산하는 기술이다.
-
Query가 values에 집중한다고도 말한다.
- 예를 들어, seq2seq+attention model에서는, 각 decoder hidden state(query)가 모든 encoder hidden states(values)에 집중한다.
-
Attention을 memory access mechanism으로 생각할 수도 있다.
- Values를 RAM으로 생각할 수 있고, query vector는 RAM의 다른 part들에 얼마나 많은 weight를 두어야 하는지를 나타내는 결합적인 memory pointer로 생각할 수 있다. 그런 다음 RAM bit를 비례적으로 검색하여 새 value를 얻는다.
-
Weighted sum은 values에 포함된 정보의 selective summary이며, 여기서 query는 focus on할 values를 결정한다.
- 언제나 whole bunch of values가 있고 이것들을 하나의 vector로 결합하고 싶을 때 쓰는 good general technique이다.
-
Attention은 다른 representation(the query)에 따라 임의의 set of representations(the values)의 fixed-size representation을 얻는 방법이다.
-
Attention은 deep learning model에서 강력하고 flexible하고 general한 way pointer 및 memory manipulation이 되었다.
-
Attention은 2010년대의 진정한 진짜 새로운 아이디어이다!
Reference
- CS224n: Natural Language Processing with Deep Learning Lecture at Stanford University
