이번 강의에서는 Machine Translation이라는 새로운 task를 소개하고 이를 수행하는 sequence-to-sequence라는 새로운 neural architecture와 이를 더 발전시킨 형태인 attention이라는 새로운 nerual technique를 소개한다.
Machine Translation
- 한 언어(source language)의 문장 x에서 다른 언어(target language)의 문장 y로 번역하는 task
Statistical Machine Translation
- 1997-2013(1990s-2010s)에, Statistical Machine Translation이 아주 큰 연구 분야였다.
🔗 Core idea
- Data로부터 probabilistic model을 학습한다.
- P(y|x) = P(x|y)P(y)
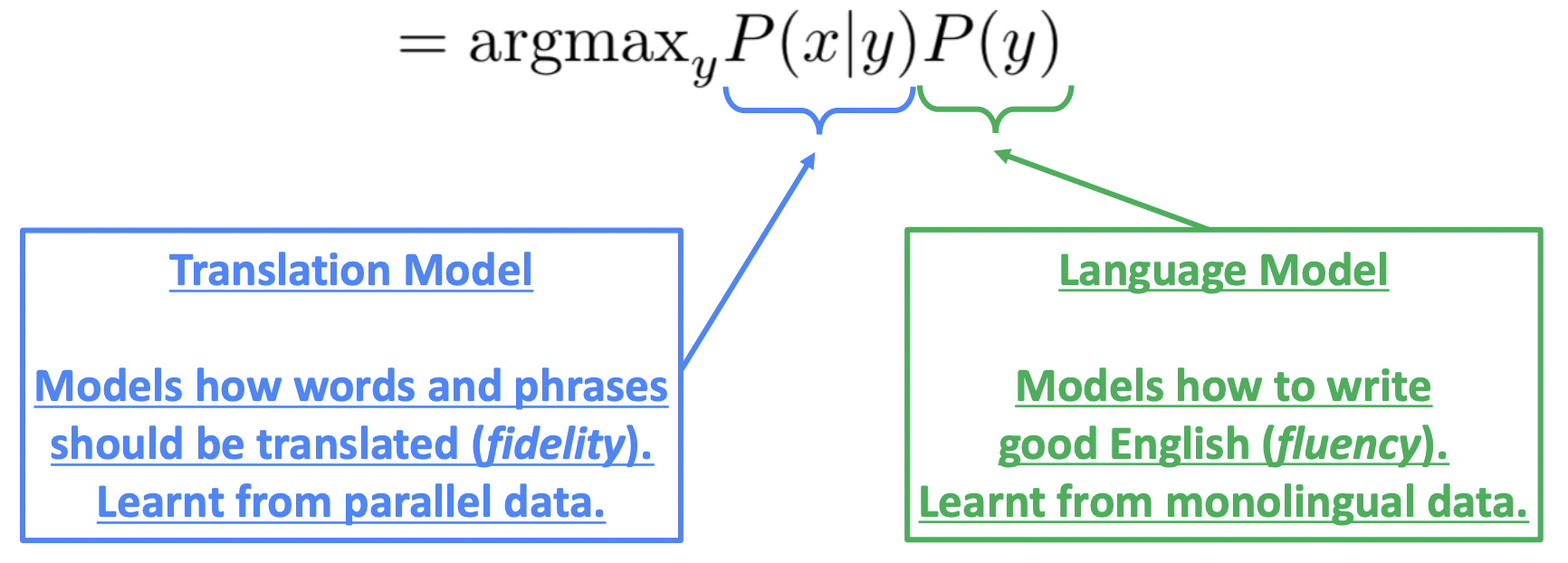
Translation Model P(x|y)을 어떻게 학습할까?
🔗 Learning alignment for SMT
- 문제 : 대응하는 게 없는 word가 있었고, many-to-one, one-to-many, many-to-many등 다양한 경우의 수가 나올 수 있어 복잡하다.
모든 가능한 y에 대해 이 probability를 계산하는 것은 매우 expensive하다. 그 해결로 decoding이라고 불리는 과정을 수행한다.
🔗 Decoding for SMT
-
모델에 강한 independence assumptions를 적용하고 globally optimal solutions를 위해 dynamic progamming을 사용한다.
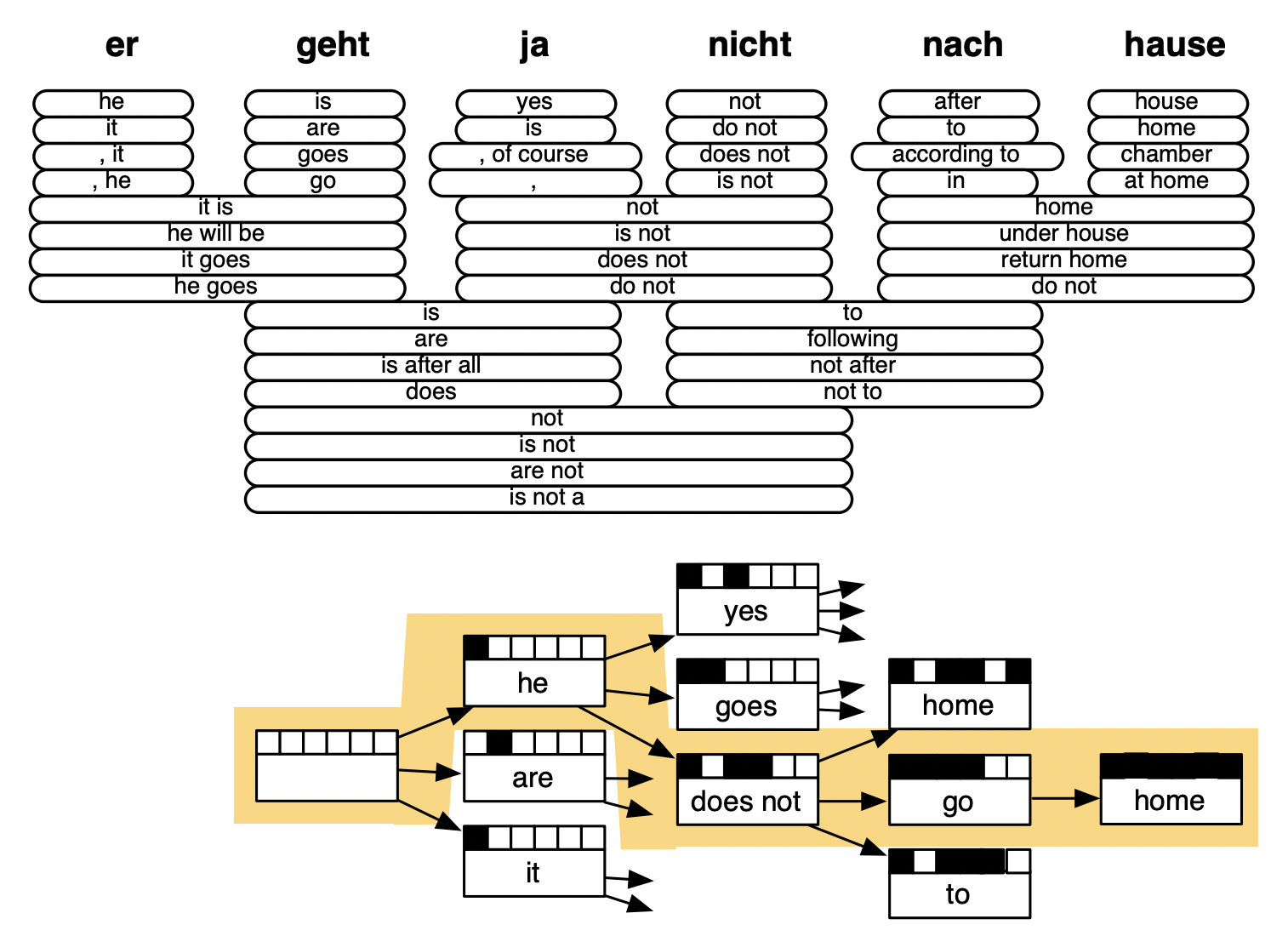
① Source sentence에서 시작한다.
② 각 German word or phrase마다 translation될 만한 단어나 Phrase를 가지고 있는다. Translation을 완성하기위해 쓰는 lego piece라고 보면 된다.
③ Neural Language model처럼 하나하나 번역을 생성해나간다.
④ 먼저 empty translation부터 시작한다.
⑤ Search process : 다양한 possible한 것을 explore한다.
- Language model에 의해 guide를 받으면 he로 문장을 시작하는 것이 더 가능성 있다.⑥ 이런 식으로 반복하여 he does not go home으로 번역한다.
🔗 단점
- 너무 복잡하다.
- 수백 가지의 중요한 세부 사항이 있다.
- System은 seprately-designed subcomponents가 많았다.
- 많은 feature engineering이 필요하다.
- Extra resources를 compiling하고 maintaining하는 것이 필요하다.
- 유지하기 위해 많은 (반복적인) human effort가 들어간다.
BUT. 그럼에도 불구하고 꽤 성공적이었다.
Neural Machine Translation
-
Machine Translation을 하기 위해서 neural network를 사용한다는 의미 뿐 아니라, 번역을 완전하게 end-to-end로 하는 하나의 매우 큰 neural network를 만든다는 의미이다.
- 따라서 예전처럼 많은 seperate component가 있는 것이 아니라 entire system이다.
-
이 neural network architecture는 sequence-to-sequence model(aka seq2seq)이라고 불린다. 그리고 이것은 2개의 neural networks로 되어있다.
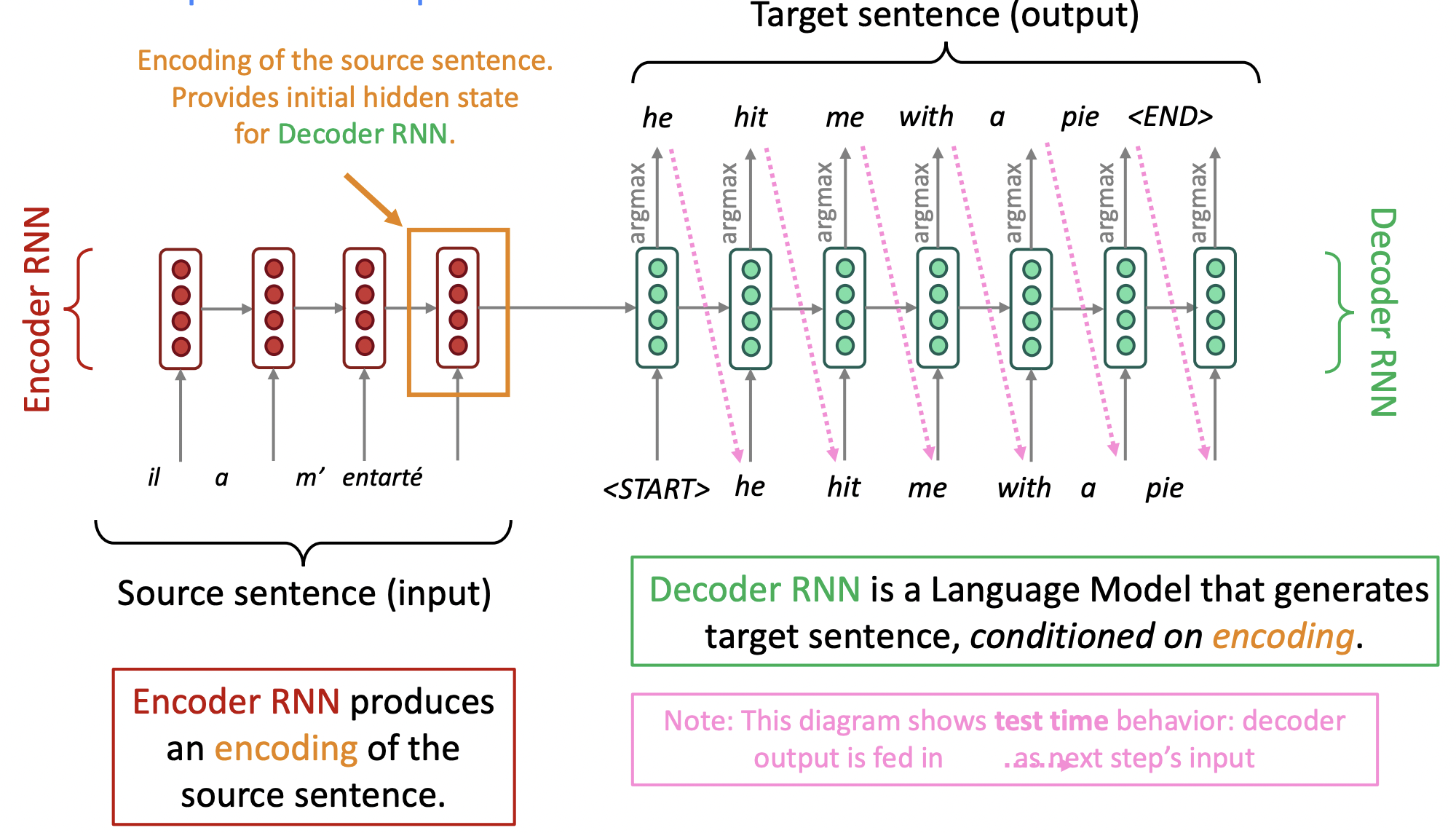
- EncoderRNN은 source sentence에 대한 encoding(representation of the content)를 생성한다.
- DecoderRNN은 encoding(=final hidden state of encoderRNN)에 conditioned되어 target sentence를 생성하는 Language Model이다.
- Start symbol을 input으로 시작한다.
- Training time behavior : LM을 training하는 것처럼 teacher forcing을 하고 실제 source sentence에 있는 word를 예측하게 한다.
- EncoderRNN과 DecoderRNN은 서로 완전히 분리된, 다른 parameters를 사용한다.
✔️ Sequence-to-sequence model은 Conditional Language Model의 예이다.

- 목표) Encoder에서 source sentence에 대한 정보를 decoder에 전달하여, decoder에서 어떤 것을 generate할지 유발하도록 한다.
- 방법1) encoder의 hidden state를 decoder의 initial state로 놓는다.
- 방법2) 아니면 decoder에 initial input으로 어떤 것을 놓는다.
🔗 Training a Neural Machine Translation system
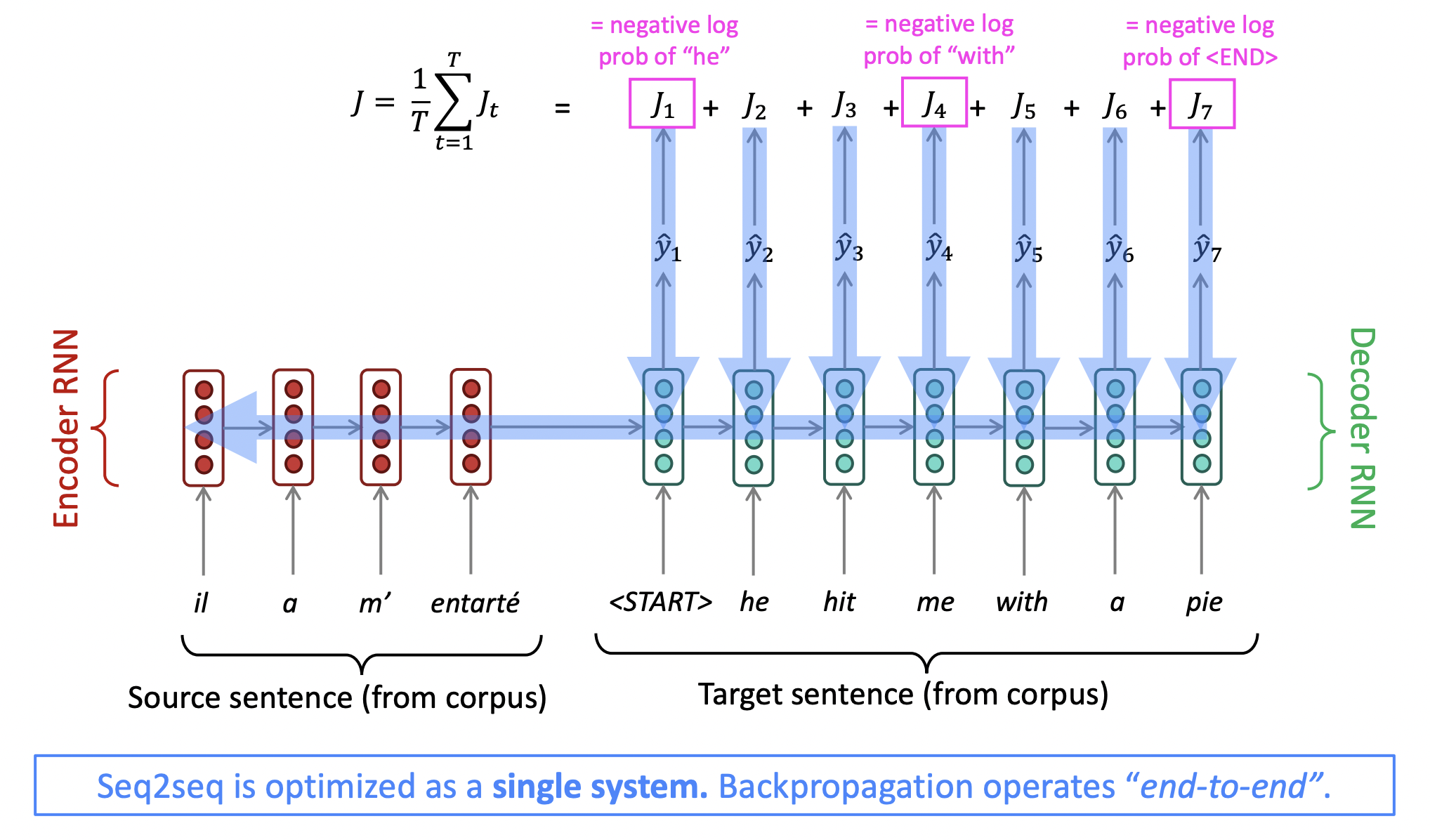
- Big parallel corpus를 준비해서 source sentences와 target sentences의 batch들을 가져온다.
- Teacher forcing : 한번에 한 word만 생성하고, 진짜 생성했어야 하는 word와 관련한 loss를 계산한다.
⭐️ sequence to sequence를 완전 성공하게 한 중요한 것 : 모든 것이 하나의 system으로 end-to-end로 optimize된다. Decoder parameter와 encoder parameter 둘 다 update한다.
🔗 Multi-layer deep encoder-decoder machine translation net
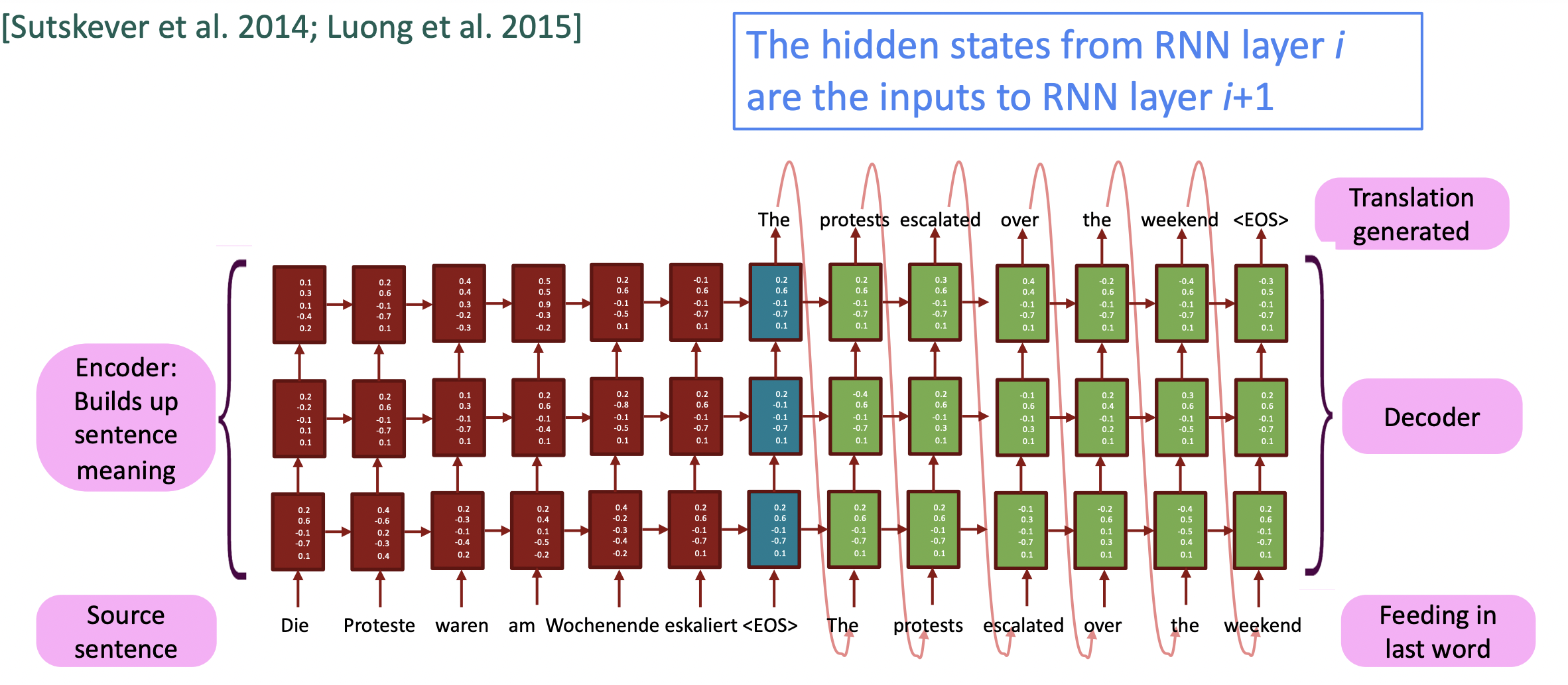
- Neural MT system에서 single layer LSTM encoder-decoder로는 잘 작동하지 않는다. 따라서 multi-layer stacked LSTM neural machine ranslation system을 사용한다.
✔️ Multi-layer RNNs in practice
- 높은 성능의 RNNs는 주로 multi-layer이다.
- EncoderRNN은 2-4 layer가 좋고, decoderRNN으로는 4 layer가 좋다. 더 deeper RNNs를 train하려면 보통 skip-connections/dense-connections가 필요하다.
- Transformer-based networks(ex. BERT)는 보통 더 깊은데, 12 또는 24 layer이다.
Decoding의 더 복잡한 형태를 알아보자.
🔗 Greedy decoding
-
Decoder의 각 step마다 argmax를 취하여 가장 확률이 높은 word를 취한다.
-
문제 : 결정을 되돌릴 수가 없다.
🔗 Exhaustive search decoding
- 모든 가능한 sequence y를 모두 계산한다.
- 이것은 각 step t에서 V^t개의 가능한 partial translations를 tracking하는 것이므로 O(V^t)는 너무 expensive하다(V : vocal size).
🔗 Beam search decoding
- 가장 중요하고 자주 쓰이는 method
- Core idea: decoder의 각 step에서 k개의 가장 probable한 partial translations(=hypotheses)를 keep track한다.
- k: beam size(주로 neural MT에서는 5~10사이 값 사용)

- k: beam size(주로 neural MT에서는 5~10사이 값 사용)
- Heuristic method로, optimal solution을 찾는다는 것을 보장할 수는 없지만 greedy decoding보다 낫고, exhaustive search보다 훨씬 효율적이다.
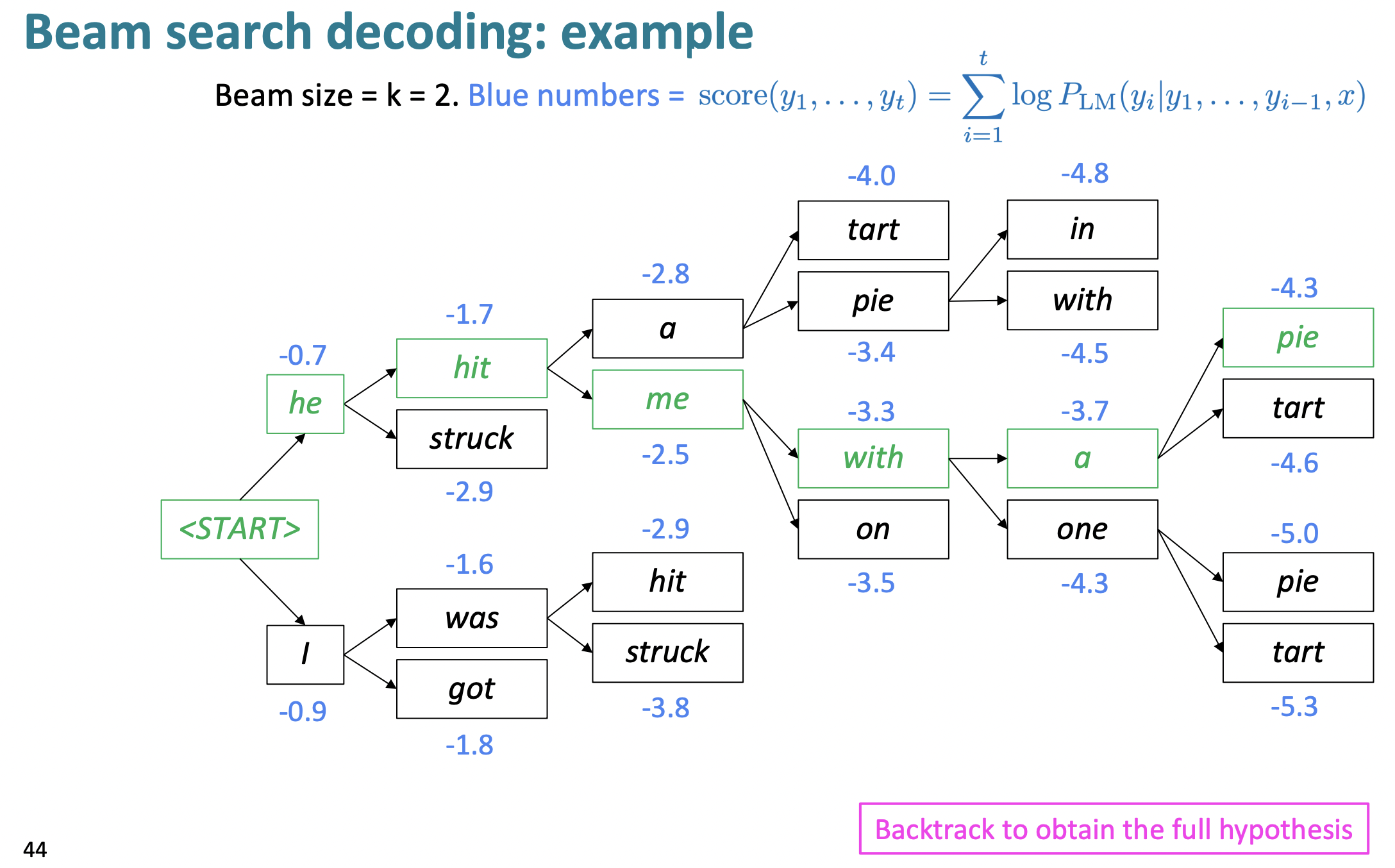
Beam search에 관한 detail이 하나 더 있다.
✔️ Beam search decoding: stopping criterion
-
Greedy decoding에서는 model이 END token을 생성하면 decode를 끝냈지만 beam search decoding에서는 여러 다른 hypothesis마다 END token을 다른 timestep에 생성한다. 그래서 어떤 hypothesis가 END를 생성하면, 그 hypothesis는 끝난 것이고, 계속해서 다른 hypothesis를 beam search를 통해 exploring한다.
-
보통 beam search의 종료 시점
- timestep T에 다다르면
- 최소 n개의 hypothesis들이 완성되었을 때 -> 우리는 이것을 사용
-
Problem : Hypothesis가 길수록 더 낮은 score를 가진다.
-
Solution(Fix) : 길이로 normalize한다.
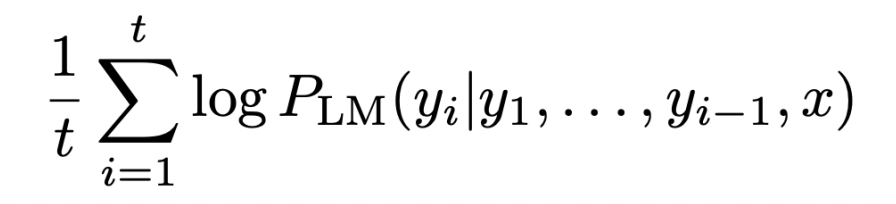
🔗 Advantages of NMT
- Better performance
- ⭐️ Single neural network을 end-to-end로 optimize
- Subcomponents를 개별적으로 optimize하게 되면, 더 큰 system에서 실제로 넣었을 때는 실제 optimal이 아닐 수 있다.
- 따라서 component-wise system보다 더 좋은 성능이 나온다.
- Less human engineering effort
- No feature engineering
- Same method for all language pairs(There's no language specific components)
🔗 Disadvantages of NMT
- Less interpretable
- 왜 이렇게 수행하는지, 무엇을 수행하는지 알기 어려워 debug하기 어렵다.
- Difficult to control
- 번역할때 rule이나 guideline을 명시하는게 어렵다.
그럼, Machine Translation은 어떻게 evaluate할까?
🔗 BLEU(Bilingual Evaluation Understudy)
-
Machine-written translation과 하나 또는 여러개의 human-written translation(s)간의 similarity score를 계산한다.
- Based on n-gram precision(주로 1,2,3,4-grams)
- 그리고 overlap되는 n-gram들간에 geometric average를 취함
-
0~100 사이의 score를 가지는데, 100은 human translation과 완전 같은 경우이고 0은 single unigram도 같은게 없는, overlap하는게 없는 경우이다.
-
Useful but imperfect
- 한 문장은 다양하게 번역될 수 있기 때문에 잘 된 번역이 low n-gram overlap을 가지면 안좋은 BLEU score을 받을 수 있다.
Neural Machine Translation은 엄청난 기술적 변화를 가져다 준 biggest success이다!
이어서 최근 NLP를 위한 neural network 분야 전체를 지배한 huge improvement ATTENTION에 대해 알아보자.
Attention
🔗 Sequence-to-sequence: the bottleneck problem
- EncoderRNN은 하나의 hidden state를 가지고 있어서 여기에 source sentence에 대한 모든 정보를 encode해야한다. 그래서 information bottleneck이 작용한다. 그리고 단지 이 encode된 hidden state만 가지고 conditioned하여 decoderRNN은 문장을 생성해야 한다.
- 해결책으로 sentence representation을 얻기 위해 모든 source에 있는 hidden vector를 평균내는 방법이 있었지만, 이는 sentiment analysis에는 도움이 되지만 machine translation에는 그닥 좋지 않다. 왜냐하면 단어의 순서를 보존하는 것이 MT에서 매우 중요하기 때문이다.
- 따라서 source sentence로부터 더 많은 정보를 얻으면 좋겠다는 생각이 든다.
🔗 Attention
- Bottleneck problem에 대한 해결책을 제공한다.
- Core idea : Decoder의 각 step에서, encoder에 direct connection을 사용하여 source sequence의 특정 부분/단어에 초점을 맞추고 이를 통해 다음에 오는 단어를 생성하는 데 도움을 준다.
먼저 diagram을 살펴보고, 다음 시간에 equation을 살펴본다.
🔗 Sequence-to-sequence with attention
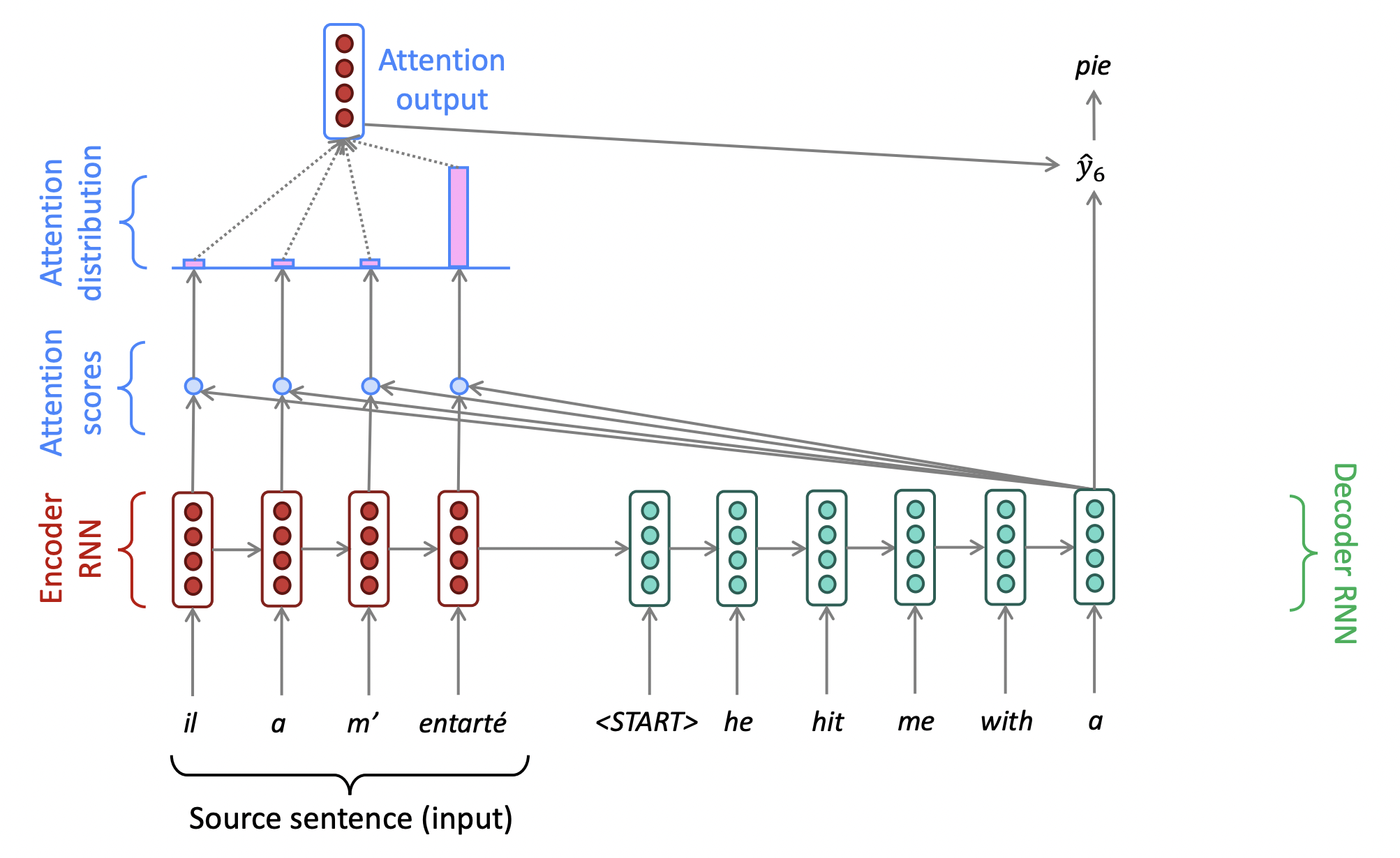
① Encoder에서 hidden representation을 얻는 것까지는 동일하다.
② 하지만 이 시점에서, 우리는 이 hidden representation을 사용하여 이것으로부터 정보를 직접 얻기 위해 source를 돌아본다.
③ Decoder의 hidden state와 encoder의 각 position에서의 hidden state를 비교하여, attention score를 얻는다. Similarity score와 비슷하게 dot product를 한다. Attention score는 실제로 probability weight이다.
④ 구한 attention score들을 기반으로, softmax를 사용하여 probability distribution을 계산한다. 그리고 이 encoder state들 중 어떤 것이 가장 이 decoder state와 비슷한지 본다.
- Ex. 문장의 첫번째 word를 먼저 번역해야겠어! -> 이 곳이 attention을 기울여야 하는 부분이다.
⑤ Softmax를 통해 나온 probability distribution인 이 attention distribution을 기반으로, 새로운 attention output을 생성한다.
- Attention distribution을 기반으로 encoder hidden states의 weighted sum을 구한다.
- 이 attention output은 high attention을 받았던 hidden state의 정보를 가장 많이 가지고 있을 것이다.
⑥ 이 attention output을 가져와서 decoderRNN의 hidden state와 concatenate하고, 이것을 이전처럼 softmax를 통해 어떤 word가 generate될 지 predict하는 데에 사용한다.
- 가끔 이전 step에서 attention output을 가져와서 기존 decoder input과 함께 decoder에 feed in하기도 한다. 이게 가끔 성능을 향상시킨다.
⑦ 각 position에서 이 계산을 반복한다. 이렇게 하면 전체 sentence를 generate한다.
이렇게 함으로써 source sentence에서 더 많은 정보를 가져올 수 있고, 좋은 번역을 생성하도록 더 flexible해지는 효율적인 방법인 것이 증명되었다.
Reference
- CS224n: Natural Language Processing with Deep Learning Lecture at Stanford University
