Training RNNs
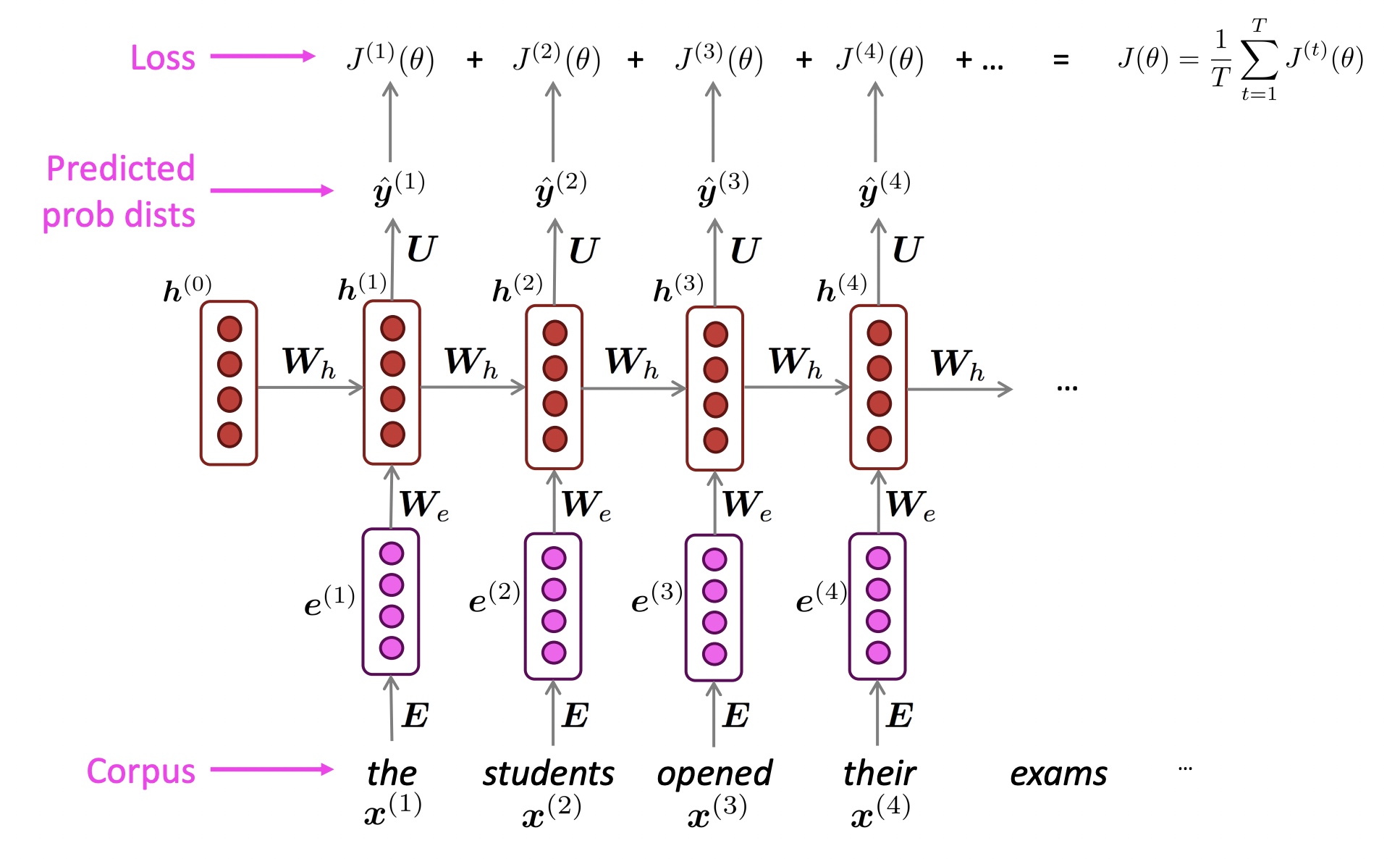
- Teacher forcing 기법을 사용
- Whole corpus를 한 step에 다 하는 것은 너무 expensive하기 때문에, whole corpus를 shorter pieces(sentence or document)로 cut한다.
- 그래서 training에서 더 빠른 speed와 efficiency를 위해 batch of sentence에 대해 update한다. Model에 32개의 sentences를 feed in하여 gradient를 계산하고 weights를 update한다.
✔️ Teacher forcing
- 현재 time step에서 나온 predicted probability distribution이 무엇이든지 간에 상관없이 다음 time step의 input으로 ground truth word를 넣어준다. 그리고 model이 ground truth word를 제안하지 않은 것에 대해 model을 penalize한다.
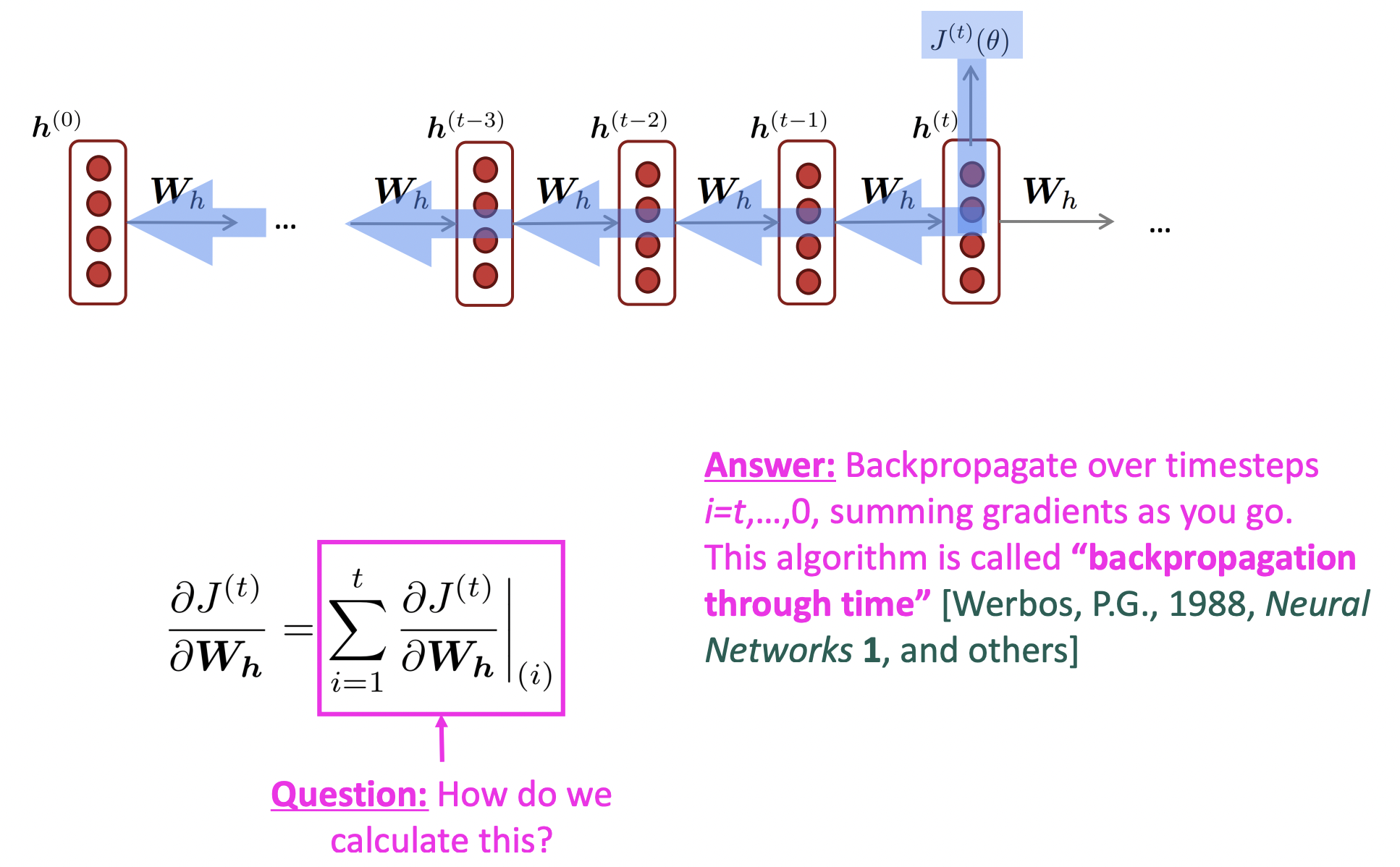
🔗 Backpropagation Through Time
- Backpropage하면서 의 gradient 결과를 계속 더해주면서 나아간다. 그리고 끝나면 모두 더한 것을 한번에 적용하여 update한다.
🔗 Truncated Backpropagation Through Time
- 상수를 선택(ex. 20)하여, 20 time steps에 대해서만 back propagation을 하고 이 20개의 gradient만 더하고 끝낸다. 그리고 이것으로 를 update한다.
Uses of RNNs
🔗 Generating text with a RNN Language Model
- Softmax를 통해 next words에 대한 probability distribution을 generate하고 그 distribution에서 sampling을 한다.
- output을 복사해서 다음 time step의 input으로 넣는다.
- 주로 아무것도 없는 상태에서 문장을 generate하고 싶을 것이므로, beginning of sequence token이라는 special token을 처음에 넣는다.
- RNN이 end of sequence symbol이라는 special symbol을 생성하면 text를 generate하는 것을 끝낸다.
Evaluating Language Models
🔗 Perplexity
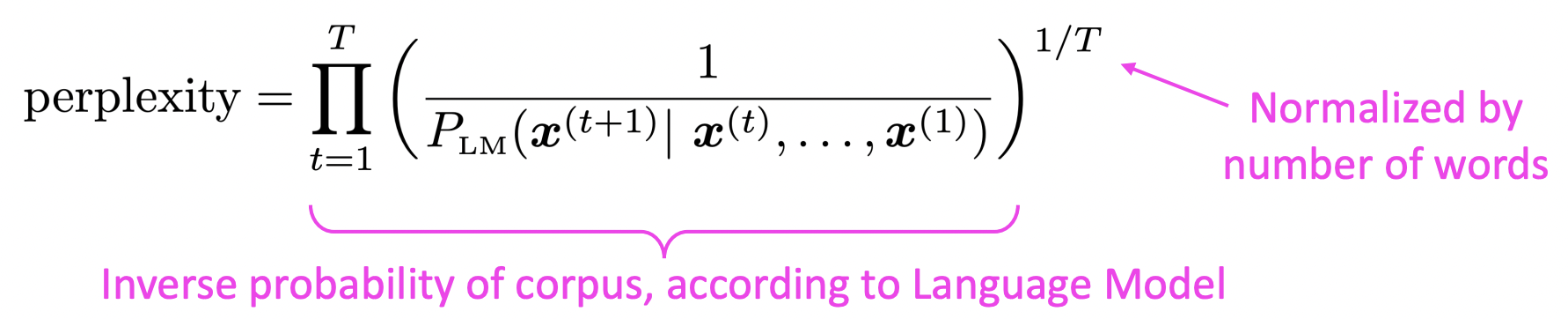
- Language Model에서 쓰는 standard evaluation metric
- Geometric mean of the inverse probabilities
- Perplexity는 얼마나 next word에 대해 불확실한가를 의미한다.
- Equal to the exponential of the cross-entropy loss J(Θ)
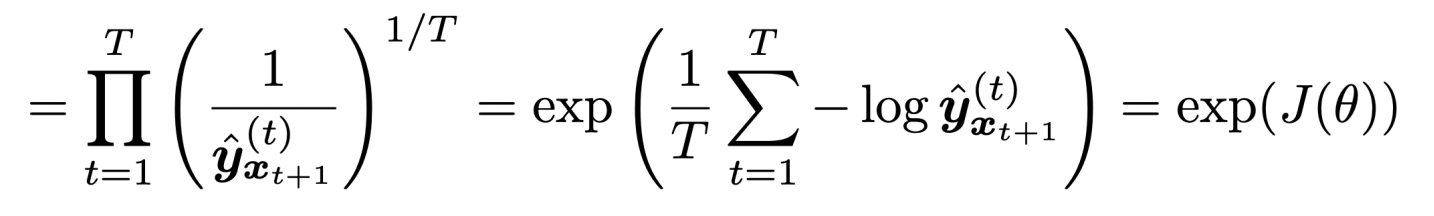
- Cross-entropy와 반대로 perplexity는 더 작을수록 더 좋다.
Other RNN uses
- Sequence tagging
- Ex) part-of-speech tagging, named entity recognition
- Sentence classification
- Ex) sentiment classification
- Langauge encoder module
- Ex) question answering, machine translation, many other tasks
- Sentence representation을 얻기 때문에 language encoder module이다. Encoder처럼 행동한다.
- Generate text
- Ex) speech recognition, machine translation, summarization
- RNN을 language로 decode하는 용도로 사용할 수도 있다.
- Conditional language model : neural net(or function)을 사용하여 initial hidden state를 얻는다. 그리고 이것을 기반으로 text를 generate한다.
Problems
🔗 Vanishing gradient problem
-
배경) Train할 때 composition과 chain rule을 통해 sequence를 따라 loss를 backpropagate한다. 이를 통해 전체 sequence를 따라 크고 긴 chian rule을 얻고, 많은 것을 곱하게 된다. 이로써 연속적인 hidden state간의 편미분값은 작아지고, 그래서 gradient가 점점 작아지게 되고 upstream gradient가 없게 되어 parameter를 update할 수 없게 된다.
-
만약 matrix의 모든 eigenvalue가 1보다 작으면 이 matrix는 작은 것이고 gradient는 vanish된다.
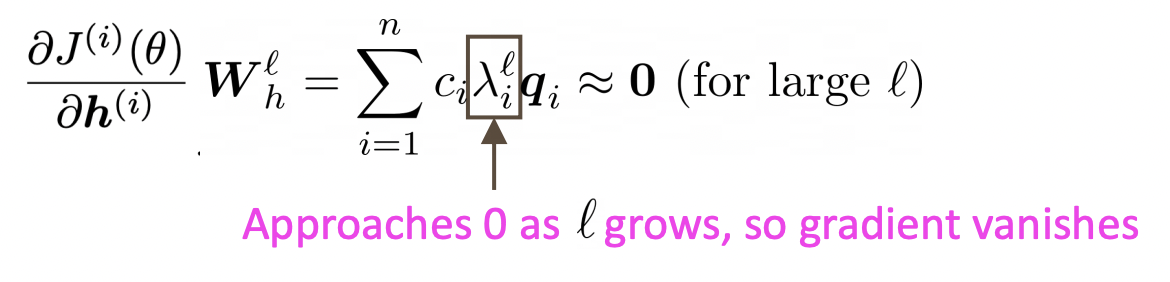
-
멀리 있는 information에 대한 gradient signal이 사라지기 때문에 model weights는 long-term effects에 대한 update를 하지 못하고 near effects에 대해서만 update를 하게된다. 그래서 미래에 필요한 유용한 멀리 있는 정보를 효율적으로 가져오지 못한다.
-
Model이 similar long-distance dependencies를 예측하는 것을 못한다.
🔗 Exploding gradient problem
-
Gradient가 너무 커도, 너무 큰 step을 가기 때문에 적절한 update를 하지 못한다. 나중에는 Inf나 NaN과 같은 숫자가 아닌 것이 나와 training을 못하게 된다.
-
Gradient clipping: solution for exploding gradient
- 만약 gradient의 norm이 어떤 threshold보다 높으면, SGD update를 하기 전에 gradient를 낮춘다. 자주 사용되는 threshold 값은 20이다.
Vanishing gradient problem의 문제는 RNN이 많은 timesteps의 정보를 보존하는 것을 학습하지 못한다는 것이다.
Vanilla RNN에서 hidden state는 계속 rewritten되기 때문에 이 memory를 좀 더 flexible하게 유지한다면 정보를 보존하기 쉬워질 것이다.
그래서 vanishing gradient problem의 solution으로 LSTM을 내놓았다.
Long Short-Term Memory RNNs (LSTMs)
- LSTM에서는 하나의 hidden vector를 가지는 것이 아니라, 각 time step에 2개의 hidden vector를 가지게된다.
- 각 gate는 얼마나 지울지, 얼마나 쓸지, 얼마나 읽을지의 의미를 가지고 있다.
- Cell이 long-term information을 저장하며, RAM과 같은 역할을 맡는다.
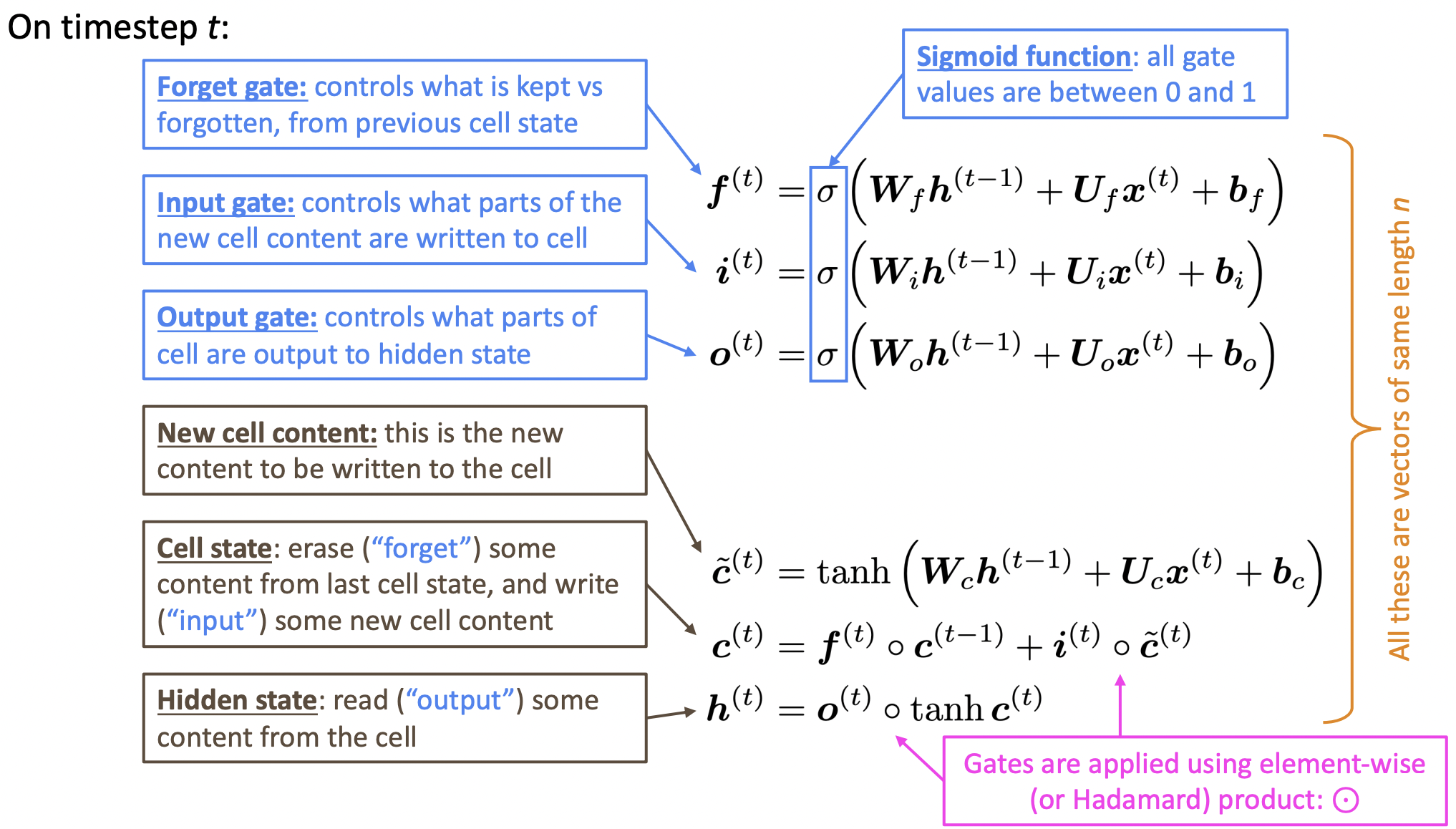
- Forget gate, input gate, output gate, 그리고 candidate new cell content 모두 서로 의존하는 것이 없으므로 병렬적으로/동시에 계산할 수 있다.
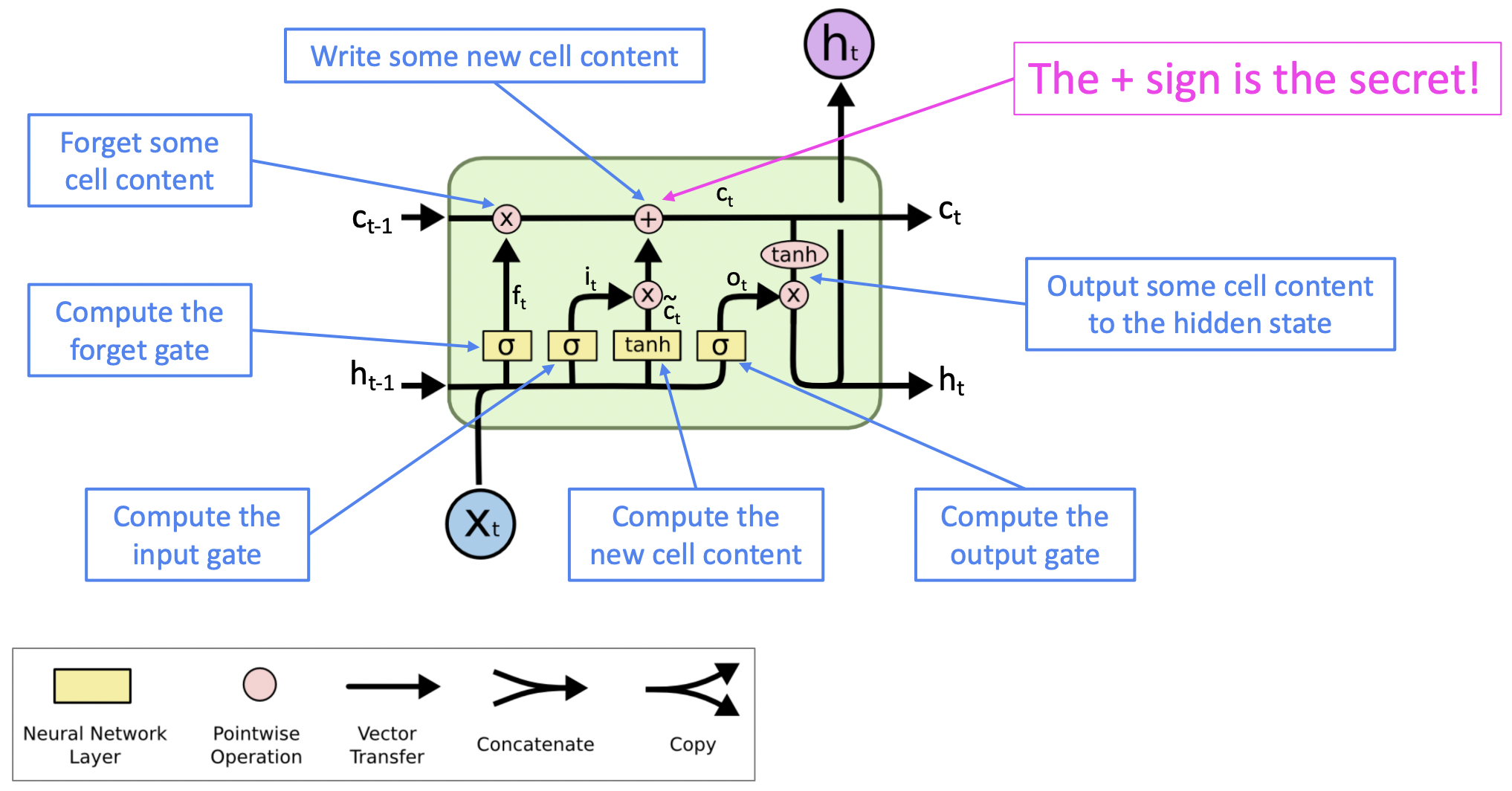
- t-1에서의 cell state가 큰 일 없이 t에서의 cell state로 pass된다. 몇몇은 forget gate에 의해 삭제되고, candidate new cell content에 의해 새로운 것이 쓰여진다.
- new stuff가 기존 cell에 그냥 더해진다. SimpleRNN에서는 각 연속적인 step에서 곱셈을 했었는데 LSTM에서는 더하기를 하기 때문에 cell에 있는 정보를 보존하기 쉽다.
- 이를 통해 많은 timesteps의 정보를 보존하는 것을 학습하는 것이 수월해진다.
🔗 Solutions about vanishing/exploding gradient in other neural architectures
- ResNet : residual connections(skip connections)
- Identity connection preserves information by default
- DenseNet : dense connections
- Add skip connections forward to every latent layer
- HighwayNet : highway connections
- ResNet처럼 identity connection을 가지는 것이 아니라 extra gate를 소개한다. input에서 얼마만큼을 highway로 보내고 neural net layer로 보낼지를 결정한다. 그리고 이 둘이 output으로 합쳐진다. LSTM과 더 비슷하다.
Vanishing/exploding gradients 문제는 모든 neural architecture에서 문제가 될 수 있는 general problem이지만, RNN에서 특히 문제이다. 왜냐하면 하나의 weight matrix를 time sequence에서 반복적으로 사용하여 반복적인 곱셈을 하기 때문이다.
Bidirectional RNNs
- 배경) 왼쪽 context뿐 아니라 오른쪽 context도 중요한 경우가 많다.
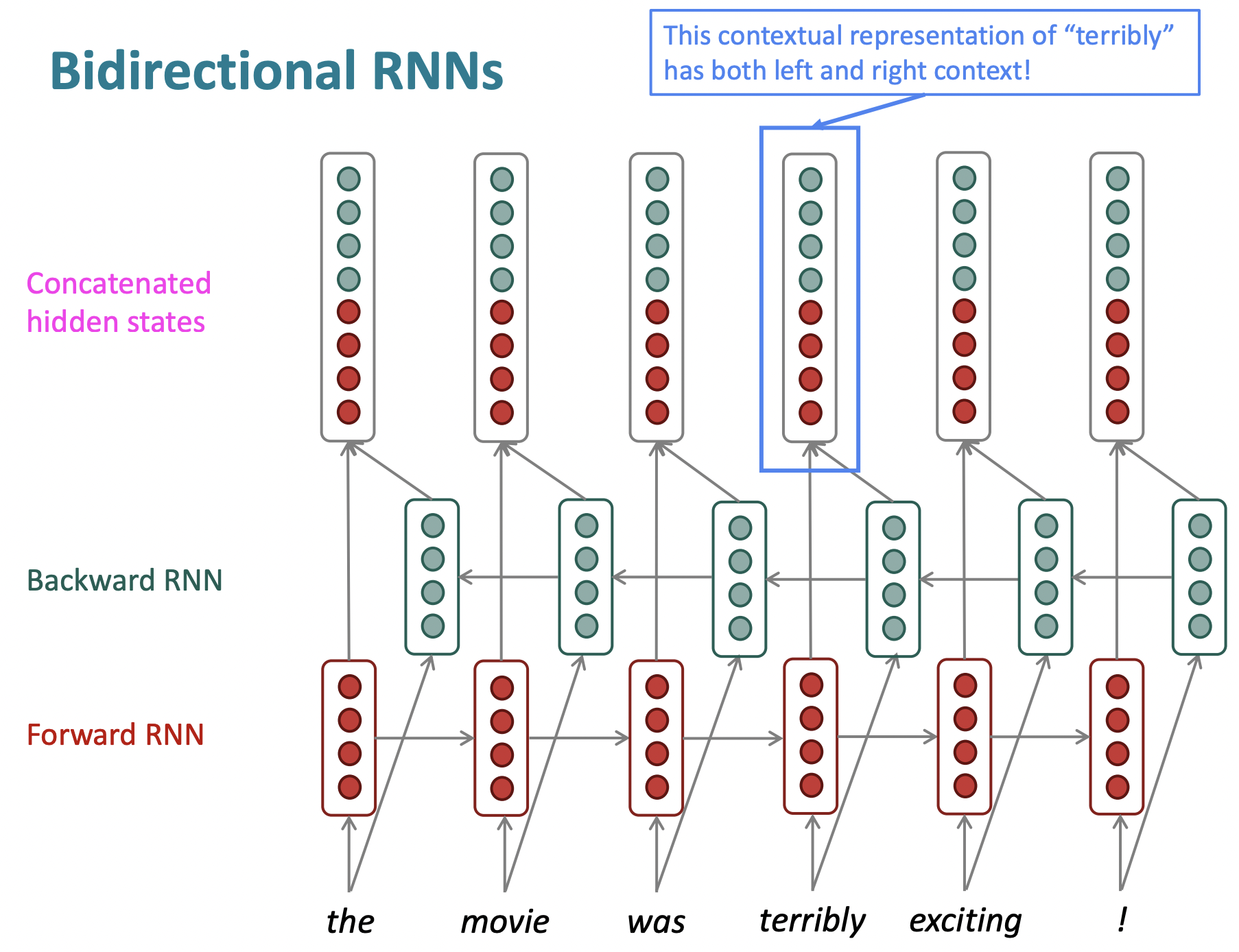

- Sentence의 neural encoding을 얻고싶을때, 완전히 분리되어 학습할 prameter를 가진 second RNN을, backward로 sentence를 통과하면서 각 word에 대한 backward representation을 얻는다. 그러고 나서 두 representation을 concatenate함으로써 각 word와 context에 대한 overall representation을 얻을 수 있다.
✔️ Simplified diagram
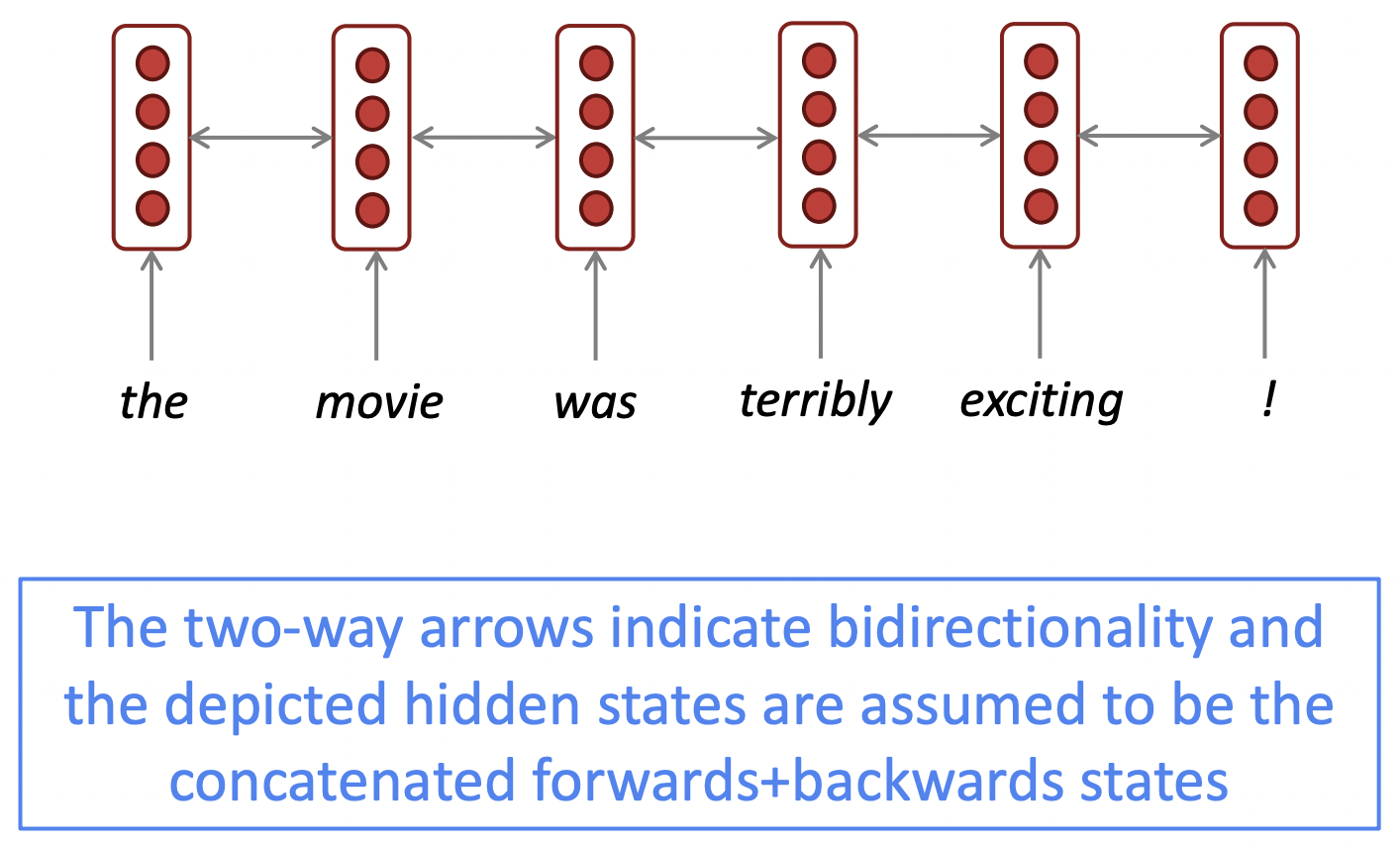
-
<->로 간단하게 표현한다. <->의 의미는, 양쪽 방향으로 두 개의 RNN을 돌리는 것이다. 그리고 그 결과를 각 timestep에서 concatenate한다. 이것이 network의 다음 part에 pass될 것이다.
-
Bidirectional RNN은 entire input sequence를 접근해야 할/가지고 있는 상황에 적합하다. 따라서 sentiment classification이나 question answering같은 encoding problem을 할 때는 bidirectional RNN으로 하기 좋다.
-
하지만 Language Modeling을 하기에는 적합하지 않다. 왜냐하면 language modeling은 next word를 이전 context만을 기반으로 해서 generate해야하기 때문이다
-
BERT도 transformer에 bidirectionality를 바탕으로 하여 더 powerful한 model을 만든 것이다.
Reference
- CS224n: Natural Language Processing with Deep Learning Lecture at Stanford University
