Paper : DynIBaR: Neural Dynamic Image-Based Rendering
Abstract
배경
- 복잡한 객체 모션과 제어되지 않는 카메라 궤적을 가진 긴 비디오의 경우 흐리거나 부정확한 렌더링을 생성하여 실제 응용 프로그램에서 사용하는 것을 방해
제안
- MLP의 가중치 내에서 전체 동적 장면을 인코딩하는 대신 장면 모션 인식 방식으로 인근 뷰의 특징을 통합하여 새로운 시점을 합성하는 볼륨 이미지 기반 렌더링 프레임워크를 채택하여 이러한 한계를 해결하는 새로운 접근 방식을 제시
결과
- 본시스템은 복잡한 장면을 모델링하고 뷰 의존적 효과를 보는 능력에서 이전 방법의 장점을 유지하지만, 또한 제약 없는 카메라 궤적을 가진 복잡한 장면 역학을 특징으로 하는 긴 비디오에서 사진 사실적인 참신한 뷰를 합성
- 동적 장면 데이터 세트에서 최첨단 방법에 비해 상당한 개선을 보여주며, 또한 이전 방법이 고품질 렌더링을 생성하지 못하는 도전적인 카메라 및 객체 모션으로 야생 내 비디오에 우리의 접근 방식을 적용
3. Dynamic Image-Based Rendering
목표는 frames 과 known camera parameters 가 있는 동적 장면의 단안 비디오가 주어질 때, 비디오 내에서 원하는 시간에 새로운 시점을 합성하는 것이다.
본 연구는 최근 동적 NeRF 방법과 같이 MLP의 가중치에 직접 3D 색상과 밀도를 인코딩하는 것이 아니라, 고전적인 IBR(Image based rendering) 아이디어를 볼륨 렌더링 프레임워크에 통합한다.
- scene-motion-adjusted multi-view feature aggregation(3.1절)
- cross-time rendering in motion-adjusted ray space을 통해 시간적 일관성을 강화(3.2절)
- Bayesian learning framework(3.3절) 내에서 별도로 훈련된 모션 분할 모듈에서 파생된 분할 마스크를 통해 정확한 장면 요인화를 달성
→ 전체 시스템은 정적 모델과 동적 모델을 결합하여 각 픽셀에서 색상을 생성
3.1. Motion-adjusted feature aggregation
시간적으로 가까운 source view에서 추출한 feature를 aggregation하여 새로운 view를 합성한다.
feature aggregation
다차원 데이터에서 다양한 특징들을 압축하거나 변환하여, 데이터를 보다 효율적으로 다루고 중요한 정보를 추출하는 프로세스
시간 에서 이미지를 렌더링하기 위해 먼저 의 temporal radius frame 내에서 source view 를 식별한다. 각 source view에 대해 shared convolutional encoder network를 통해 2D feature map 를 추출하여 입력 튜플 을 구성한다.
Target ray 위에서 샘플링된 각 점의 색상과 밀도를 예측하려면, 장면 모션을 고려하면서 source view feature를 aggregation해야 한다. 정적 장면의 경우, 인접한 source view에서 target ray 위의 점이 해당 epipolar line을 따라 놓여 있다. 이는 단순히 인접한 epipolar line을 따라 샘플링함으로써 잠재적 대응을 aggregation할 수 있다.
Epipolar geometry
https://darkpgmr.tistory.com/83
3차원 공간상의 한 점 P가 영상 A에서는 p에 투영되고, 영상 B에서는 p'에 투영됐다고 가정한다. 이 때, 두 카메라 원점을 잇는 선과 이미지 평면이 만나는 점 e, e'을 epipole이라 부르고 투영점과 epipole을 잇는 직선 l, l'을 epiline (또는 epipolar line)이라 부른다. 이 Epipolar geometry은 Stereo Vision(두 개 이상의 카메라를 사용하여 3D 공간에서 객체를 인식하는 기술)에서 사용된다.
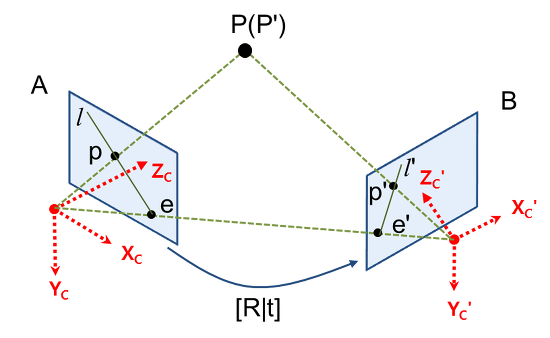
그러나, 동적 장면 요소는 epipolar 제약을 위반하여 움직임이 설명되지 않으면 일관되지 않은 feature aggregation로 이어진다. 따라서, 본 연구는 motion-adjusted feature aggregation을 수행한다.
동적 장면에서 대응 관계를 결정하기 위해서는 MLP를 통해 scene flow field를 추정하여 인근 시간에 주어진 점의 motion-adjusted 3D 위치를 결정할 수 있다. 그러나 이 전략은 MLP의 재귀적 unrolling으로 인해 volumetric IBR 프레임워크에서 계산적으로 실행 불가능하다.
Motion trajectory fields
대신, 학습된 basis function의 관점에서 설명된 motion trajectory field를 사용하여 장면 움직임을 나타낼 수 있다. 시간 에서 target ray 위의 3D 점 에 대한 궤적 계수를 MLP 로 인코딩한다:
- : basis coefficient(아래의 motion basis를 사용하여 에 대한 별도의 계수 사용)
- : positional encoding
- 장면 움직임이 low frequency 경향이 있다는 가정하에, encoding 에 대해 개의 base와 16개의 linearly increasing frequency를 선택
motion basis 는 MLP와 공동으로 최적화되는 입력 비디오의 모든 시간 단계 에 걸쳐있는 global하게 학습 가능한 파라미터(?)이다. 그러면 의 모션 궤적이 로 정의되기에, 시간 에서 와 3D 대응 사이의 상대적 변위는 다음과 같이 계산된다:
이 motion trajectory representation을 사용하면 인접 view에서 query point 에 대한 3D 대응을 찾는 데 단일 MLP 쿼리만 필요하므로 볼륨 렌더링 프레임워크 내에서 효율적인 다중 뷰 기능 집합이 가능하다. 본 연구는 Neural Trajectory Fields for Dynamic Novel View Synthesis에서 제안하는 DCT(Discrete Cosine Transform) 기반으로 basis 를 초기화한다.
Discrete Cosine Transform
주로 신호 처리 및 영상 압축에 사용되는 수학적 기법으로, 신호를 사인 함수의 합으로 분해하는 푸리에 변환과 밀접한 관련이 있지만 영상 압축과 같은 작업에는 DCT가 특히 적합
그러나 고정된 DCT basis은 광범위한 실제 움직임을 모델링하지 못할 수 있기에, 최적화 중에 다른 구성 요소와 함께 fine-tunning해야 한다(그림 4(c)).
시간 에서 추정된 의 운동 궤적을 사용하여 시간 에서 의 해당 3D 지점을 로 나타낸다. 카메라 매개 변수 를 사용하여 각 왜곡된 지점 를 source view 에 투영하고 투영된 2D 픽셀 위치에서 색상 및 feature vector 를 추출한다.
인접 view 에 걸친 source feature의 결과 세트는 weighted average pooling을 통해 output feature가 aggregation되는 공유 MLP에 공급되어 ray 을 따라 각 3D 샘플 지점에서 단일 feature vector를 생성한다. time embedding 가 있는 ray transformer network는 ray를 따라 aggregation된 feature의 시퀀스를 처리하여 샘플당 색상 및 밀도를 예측한다. 이후 표준 NeRF 볼륨 렌더링(Neural Reflectance Fields for Appearance Acquisition)을 사용하여 이 색상 및 밀도 시퀀스에서 ray에 대한 최종 픽셀 색상 를 얻는다.
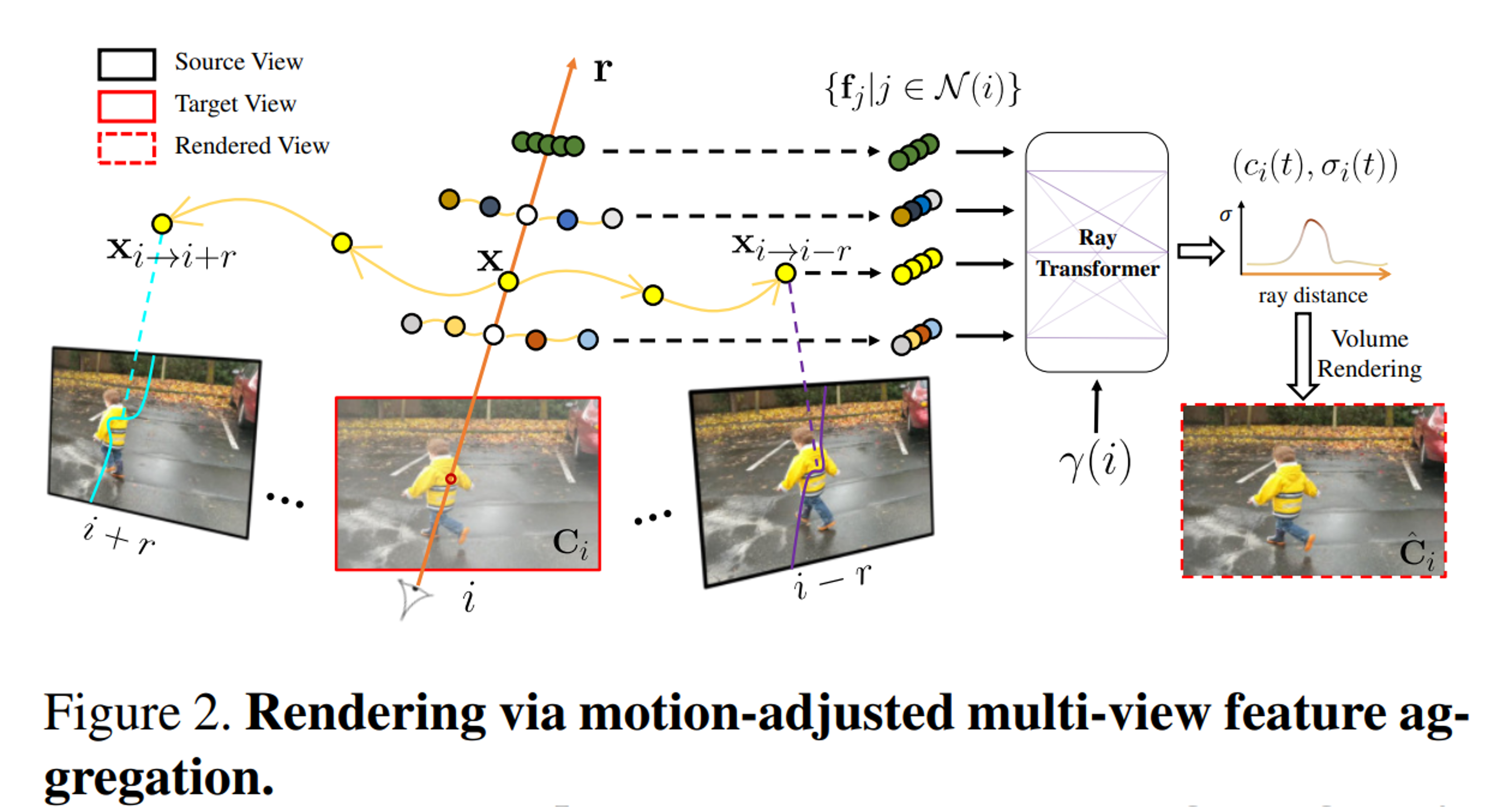
1) 시간 에서 target ray 을 따라 샘플링된 위치 가 주어지면 로 표시되는 인접 시간 에서 의 3D 대응을 결정하는 움직임 궤적을 추정한다. 2) 그런 다음 각 왜곡된 점은 해당 source view에 투영된다. 3) 투영된 곡선을 따라 추출된 Image feature 는 aggregation되어 time embedding 와 함께 ray transformer에 공급되어 샘플당 색상과 밀도를 생성한다. 4) 그런 다음 최종 픽셀 색상 는 을 따라 볼륨 렌더링 에 의해 합성된다.
3.2. Cross-time rendering for temporal consistency
를 단독 와 비교하여 dynamic scene representation을 최적화하면, representation이 입력 영상에 overfit될 수 있다. 이는 representation이 장면 모션을 활용하거나 정확하게 재구성하지 않고도 각 시간 instance에 대해 완전히 별도의 모델을 재구성할 수 있기 때문에 발생할 수 있다.
따라서 일관된 장면을 복구하기 위해 scene representation의 시간적 일관성을 적용한다. 시간적 일관성을 정의하는 한 가지 방법은 장면 모션을 고려할 때 인접한 두 시간 와 의 장면이 일치해야 한다 것이다. 특히, cross-time rendering in motion-adjusted ray space을 통해 optimized representation에 temporal photometric consistency을 적용한다.
이 아이디어는 시간 에서 view를 렌더링하지만, 가까운 시간 를 통해 몇몇의 view를 렌더링하는 것이며, 이를 cross-time rendering이라고 한다. 각 주변 시간 에 대해 ray 위의 점 를 직접 사용하는 것이 아니라 시간 에서 motion-adjusted ray 위의 점 를 고려하여 ray 위에 놓여 있는 것처럼 취급한다.
- Motion-adjusted point 를 계산한 후, MLP를 쿼리하여 새로운 궤적 계수 를 예측하고, 이를 사용하여 temporal window 에서 이미지 에 대한 해당 3D 점 를 계산한다.
- 이 새로운 3D 대응은 곡선의 motion-adjusted ray 위에 있는 것을 제외하고, 3.1절의 "straight" ray 에 대해 설명된 것과 동일하게 픽셀 색상을 렌더링하는 데 사용된다.
즉, 각 점 는 카메라 매개 변수 와 함께 source view 및 feature map 에 투영되어 RGB 색상 및 image feature 를 추출한 다음, 이러한 feature들은 aggresion되어 time embedding 로 ray transformer에 입력된다. - 결과는 시간 에서 를 따라 색상과 밀도 의 시퀀스이며, 이는 볼륨 렌더링을 통해 합성되어 색상 를 형성한다.
- motion-disocclusion-aware RGB reconstruction loss를 통해 와 타겟 픽셀 를 비교한다:
- RGB loss : 일반화된 Charbonnier loss를 사용
- : NSFF에서 설명된 motion disocclusion ambiguity를 해결하기 위해 시간 와 사이의 누적 알파 가중치의 차이로 계산된 motion disocclusion weight
- 일 때 scene motion–induced displacement가 없으며, 이는 를 의미하며 disocclusion weight 미포함()
- temporal consistency을 적용한 방법과 적용하지 않은 방법 비교(그림 4(a))
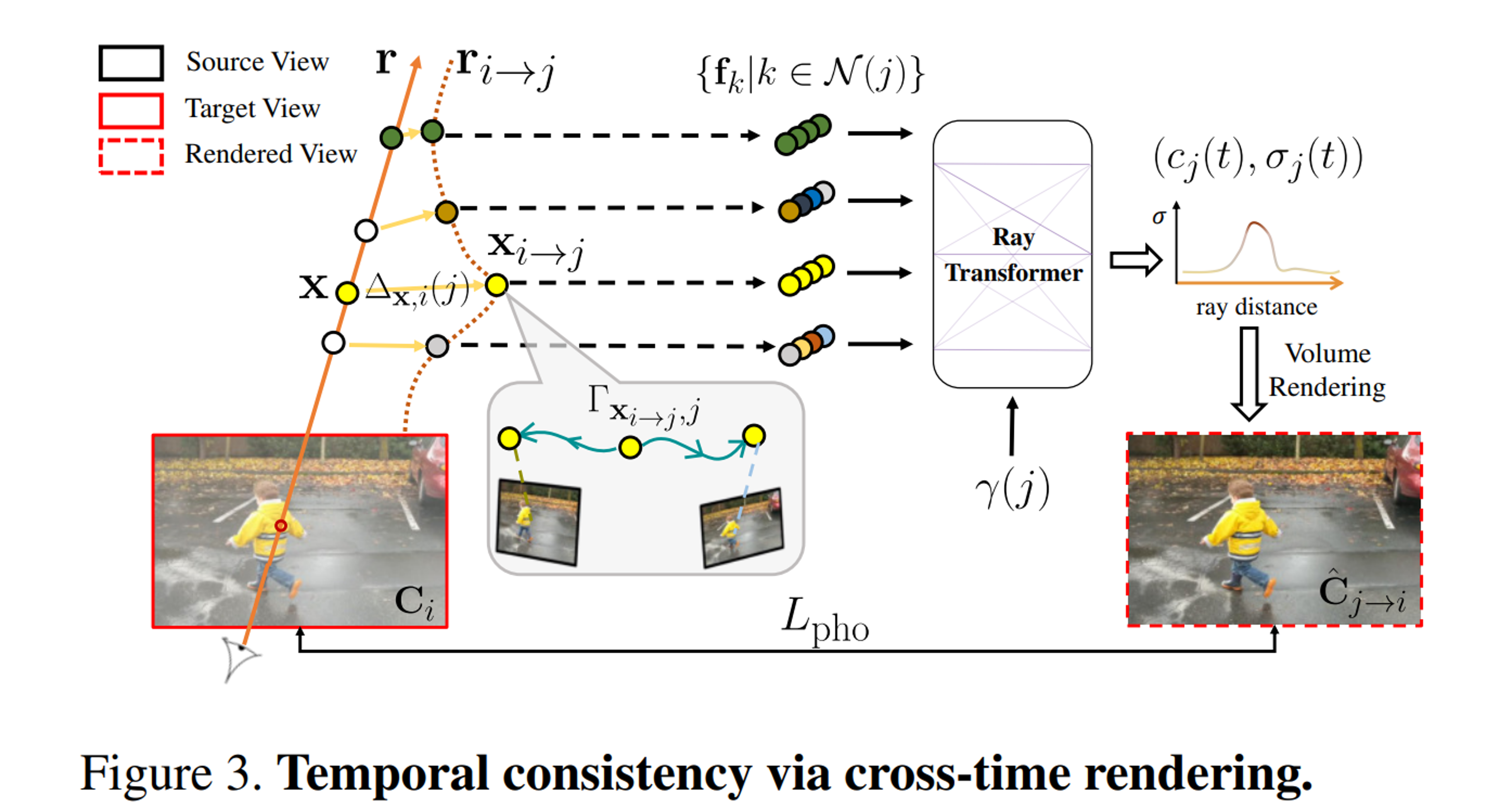
동적 재구성에서 시간적 일관성을 적용하기 위해, 가까운 시간 의 scene model을 사용하여 각 frame 를 렌더링하는데, 이를 cross-time rendering이라고 한다. 이미지 의 ray 대신 곡선 광선 를 사용하여 렌더링되며, 시간 로 왜곡된다. 즉, 위의 모든 샘플링 위치에서 가까운 시간 에서 motion-adjusted point 를 계산한 후 MLP를 통해 와 시간 를 쿼리하여 움직임 궤적 를 예측하고, 이를 통해 시간 내에 source view에서 추출된 image feature 를 aggregation한다. 를 따라 aggregation된 feature는 시간 에서 샘플당 색상과 밀도 를 생성하기 위해 time embedding 를 가진 ray transformer에 공급된다. 픽셀 색상 는 볼륨 렌더링 에 의해 계산된 다음 실측 색상 와 비교하여 reconstruction loss 를 형성한다.
3.3. Combining static and dynamic models
NSFF에서의 작은 temporal window을 사용하여 novel view를 합성하는 방법을 착안하고, 두 개의 개별 representation을 사용하여 전체 장면을 모델링한다. dynamic content 는 time-varying model로 표현된다(최적화 중 cross-time rendering에 사용). static content 는 time-invariant model로 표현되며, time-varying model과 동일한 방식으로 렌더링되지만 장면 모션 조정 없이(즉, epipolar line을 따라) multiview feature을 aggregation한다.
동적 및 정적 예측은 NeRF-W의 정적 및 일시적 모델 결합 방법을 사용하여 단일 출력 컬러 (또는 cross-time rendering 시 )로 결합 및 렌더링된다. 각 모델의 색상 및 밀도 추정치는 별도로 렌더링될 수도 있으므로 static content의 경우 색을, dynamic content의 경우 색을 제공한다.
두 representation을 결합할 때, 식 3의 photometric consistency term을 과 타겟 픽셀 을 비교한 loss로 교체한다:
Image-based motion segmentation
본 프레임워크에서, 초기화 없는 scene factorization는 최근 방법에서도 관찰되는 현상인 시간 불변 또는 시간 가변 representation에 의해 지배되는 경향이 있음을 관찰했다. factorization를 용이하게 하기 위해, Dynamic view synthesis from dynamic monocular video은 모든 이동 객체가 candidate semantic segmentation label 세트에 의해 캡처되고 segmentation mask가 시간적으로 정확하다는 가정에 의존하여 semantic segmentation mask를 사용하여 시스템을 초기화한다. 그러나 Structure and motion from casual videos에서 관찰된 바와 같이 이러한 가정은 많은 실제 시나리오에서 성립하지 않는다. 따라서, 본 연구는 main two-component scene representation을 감독하기 위한 segmentation mask를 생성하는 새로운 motion segmentation module을 제안한다.
특히, main two-component scene representation을 훈련하기 전에 두 개의 경량 모델을 공동으로 훈련시켜 각 입력 프레임 에 대한 motion segmentation mask 를 얻는다. 장면 모션을 고려하지 않고 인근 source view에서 epipolar line을 따라 feature aggregation을 통해 각 ray을 따라 볼륨 렌더링을 사용하여 픽셀 색상 를 렌더링하는 IBR-Net으로 static scene content를 모델링한다. 입력 프레임에서 2D opacity map , confidence map 및 RGB 이미지 를 예측하는 2D convolutional encoder-decoder network 로 dynamic scene content를 모델링한다:
그런 다음 두 모델의 결과를 통해 픽셀 단위로 전체 재구성 영상이 합성한다:
움직이는 물체를 분할하기 위해, 관측된 픽셀 색상이 이분산적 완화체 방식으로 불확실하다고 가정하고, time dependent confidence 를 가진 Cauchy distribution으로 비디오의 관측치를 모델링한다. 관측치의 negative log-likelihood를 취함으로써, segmentation loss가 weighted reconstruction loss로 기록된다:
위 식을 사용하여 두 모델을 최적화함으로써 를 0.5에서 임계값으로 지정하여 motion segmentation mask 를 얻는다. network 에서 skip connection을 제외하여 자연스럽게 inductive basis를 포함하므로 degeneracy를 피하기 위해 NeRF-W와 같이 alpha regularization loss가 필요하지 않다.

Supervision with segmentation masks
동적 영역의 time-varying 모델과 정적 영역의 time-invariant 모델에서의 렌더링에 reconstruction loss를 적용하고 Omnimatte의 mask 를 사용하여 주요 시간 불변 또는 시간 가변 모델을 초기화한다:
mask 경계 근처의 loss을 끄기 위한 동적 영역과 정적 영역의 mask를 각각 얻기 위해 에 대해 형태적 erosion과 dilation을 수행한다. 로 시스템을 감독하고 50K 최적화 단계마다 동적 영역에 대해 가중치를 5배씩 감소시킨다.
3.4. Regularization
시공간 뷰 합성을 위한 main representation을 최적화하는 데 사용되는 최종 결합 loss:
복잡한 동적 장면의 monocular reconstruction은 잘못 제기된 문제이며, photometric consistency을 사용하는 것만으로는 최적화 중 나쁜 local minima를 피하기에 충분치 않다. 따라서 세 가지 주요 부분 으로 구성된 정규화 설계를 채택한다.
- : Zhang et al. 및 RAFT의 추정치를 사용한 monocular depth 및 optical flow consistency prior로 구성된 data-driven term
- : 추정된 trajectory field가 cycle-consistent하고 공간적으로 매끄러운 것을 권장하는 motion trajectory regularization term
- : entropy loss을 통해 장면 분해를 이진화하도록 장려하고 distortion loss을 통해 floater을 완화하는 compactness prior
