
참여 계기
제가 가장 자주 시청하는 스트리머 분이 있습니다. 게임 스트리머로 시작하시고, 최근에는 한국에 버츄얼 생태계를 만들어 내면서 더욱 유명해지신 우왁굳 님입니다. 우왁굳 님의 팬덤 문화 중에는 특이한 점이 있는데 바로 팬 분들이 직접 플랫폼을 개발해서 제공해주는 것입니다.
많은 오리지널 플랫폼들이 있지만 대표적으로 위와 같은 플랫폼들이 있습니다.
방송을 시청하면서 이러한 플랫폼들 덕분에 많은 사람들이 더 재밌게 즐길 수 있는 것을 보고 저도 이러한 생태계에 기여 해보고 싶다는 생각이 들었습니다. 그래서 팬카페인 왁물원을 통해서 모집 공고에 지원해서 2023년 7월에 왁스코드 팀에 합류하게 되었습니다.
프로젝트 개요
우왁굳님은 고정멤버와 중간계라는 네임드 시청자 분들이 있습니다. 방송을 하게되면 몇만명이 시청하고 동시에 채팅을 보내기 때문에 네임드 분들이 작성하는 채팅을 보기 어려운 문제가 있었습니다. 이러한 채팅들이나 방송 시작, 공지 등을 구독을 하면 디스코드로 웹훅을 통해서 알림을 전송해주는 서비스 입니다. 2024년 4월 기준으로 구독 수가 143,900개이고, 월 알림 전송 수는 약 1억 3천만 건이 발생하고 있습니다.
설계
아키텍처 설계
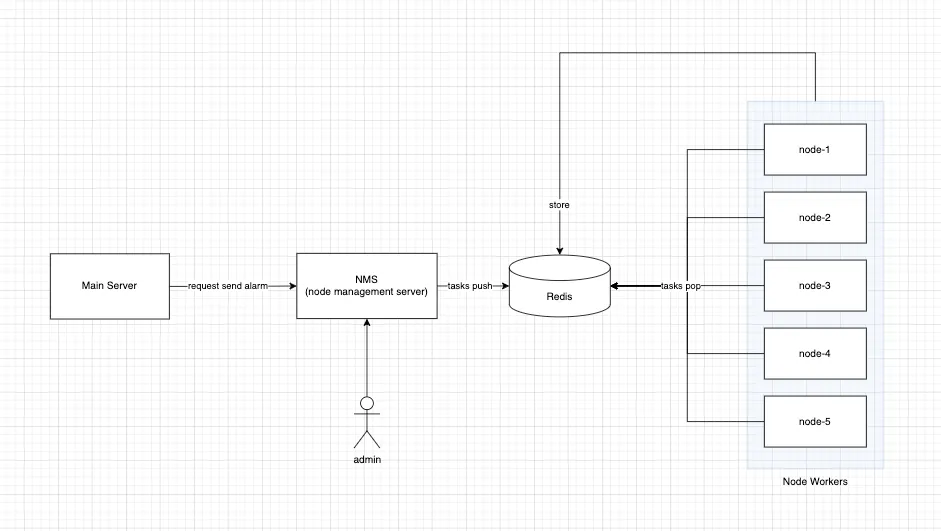
알림이 전송되는 프로세스는 간단하게 설명하자면 다음과 같습니다.
- 카페 공지 사항 업로드, 네임드 시청자의 채팅 작성 이벤트 등을 메인 서버에서 감지
- 메인 서버에서 알림 전송 작업을 NMS(노드 서버 관리 API)에 요청
- NMS에서 알림을 구독한 수만 명의 구독자를 노드 서버 수만큼 작업을 나눠서 레디스에 작업을 등록
- 각 노드 서버에서는 해당 작업을 레디스에서 읽고, 구독자들에게 비동기로 알림 전송
메인 서버는 기존 시스템이 존재하던 서버이고, 저는 노드 서버와 NMS API 개발을 담당했습니다.
왁스코드는 기업에서 진행하는 것이 아니라 우왁굳님을 좋아하는 팬 분들이 모여서 만드는 서비스이다보니 별도의 서버비를 지불해서 인프라를 구성하기 어려웠습니다. 그래서 다른 팬 분들에게 프리티어 인스턴스들을 기부 받아서 운영하고 있기 때문에 사용할 수 있는 자원들이 한정되어 있는 상황이었습니다.
따라서, 클라우드 서비스에서 제공해주는 관리형 서비스들을 사용하기 어려웠습니다. 메시지 큐로 흔히 사용되는 카프카는 직접 구성하기에는 많은 복잡도와 자원을 사용하는 단점이 있어서 적합하지 않다고 판단했습니다. 그래서 메시지 큐와 캐싱의 역할도 같이할 수 있는 레디스를 선택했습니다.
객체 설계

위와 같이 요구사항에 따른 유스케이스를 정리하고 객체를 정의했습니다. AlarmSender는 알람을 전송하는 책임을 갖도록 하고 AlarmResponseValidator는 알람을 전송 후 응답을 검사하는 역할을 맡도록 설계했습니다.
Celery에서 aiohttp 방식으로 변경
첫 노드 서버 설계는 Celery를 기반으로 구현하려고 했으나, 당시에 Celery에서 asyncio를 지원해 주지 않는 문제를 갖고 있어서 aiohttp 방식으로 재구현을 해서 asyncio.gather로 수천 명의 구독자들에게 알림 요청을 보낼 수 있도록 개선했습니다. (commit)
또한, 서버마다 다른 리소스를 갖고 있으므로 부하를 조절할 수 있도록 MAX_CONCURRENT 옵션을 추가하고 해당 옵션에 따라서 작업을 Chunk 해서 보낼 수 있도록 했습니다. (commit)
트러블 슈팅
Redis max_clients 이슈
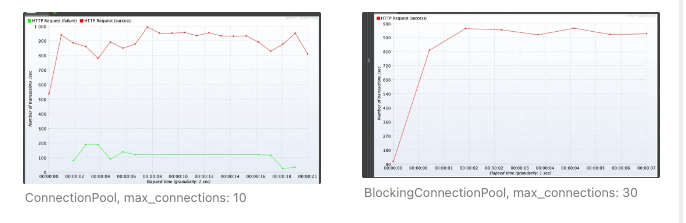
로그에 Redis max_clients 에러가 올라와서 확인해 보니 ConnectionPool의 기본 client session 개수보다 동시성 등을 이유로 더 많이 사용하고 있어서 발생했었습니다. 그래서 max_connections 상태에 도달해도 설정한 timeout 동안 세션을 얻으면 에러를 발생시키지 않는 BlockingConnectionPool로 변경하고, 위와 같이 Jmeter를 활용한 부하테스트를 통해서 max_connections 30이 적절하다는 것을 확인하여 해결했습니다. (PR)
알림 전송 실패 이슈
asyncio.gather로 보낸 후에는 각종 알림 전송 실패 이슈들이 있었습니다. 전송 중에 세션이 끊기면서 발생하는 ConnectionResetError, ServerDisConnectedError 등이 발생하였고 이외에도 Discord 서버의 이슈로 500 에러나 Rate Limit인 429 에러도 발생했습니다.
이러한 이슈들은 각 예외 케이스들을 정의하고 재시도 요청을 백그라운드로 실행하도록 했습니다. 지수 백오프(Exponential Backoff)의 전략을 적용해서 재시도 요청을 각 시도 횟수에 비례해서 재시도 주기도 선형적으로 증가해서 요청하도록 구현했습니다.
Redis 큐가 멈추는 이슈
Redis의 blpop 간격을 infinite로 설정할 때 Redis 큐가 멈춰서 작업을 가져오지 못하는 이슈가 있었습니다. Python Redis 라이브러리 이슈를 확인해 보니 HTTP keep alive 기본값이 False로 되어있는데 blpop이 infinite로 되어있을 때 특정 시간 동안 작업이 추가가 되지 않으면 세션이 끊기면서 무한 대기 상태로 빠지는 이슈였습니다. 그래서 이러한 이슈를 Redis 연결 속성에서 socket_keep alive 옵션을 True로 변경하고, socket_timeout에 시간을 지정해 주면서 해결할 수 있었습니다. (PR)
인프라 구성
기존 환경의 경우 프리티어 인스턴스로 분산 노드 서버를 구성해서 사용하고 있었습니다. 단순 인스턴스 서버에서 관리하다 보니 다음과 같이 여러 문제점이 있었습니다.
- 새로 기증받은 서버에 서비스를 구성하기 어려움, 스케일 아웃을 하기 어려움
- 여러 서버에서의 환경 변수를 관리하기가 어렵고, 보안에 민감한 변수를 Image에 포함
위와 같은 문제점을 도커 스웜의 도입을 통해서 해결했습니다.
첫 번째 문제는 스웜 자체가 컨테이너 오케스트레이션 이기 때문에 자연스럽게 해결할 수 있었고, 두 번째 문제는 .env 파일을 스웜의 Secret에 등록해서 매니저 노드에서만 관리하면 워커 노드에서 암호화된 값으로 환경 변수를 사용할 수 있도록 구성하여 해결했습니다.
쿠버네티스 대신에 스웜을 선택한 이유는 다음과 같습니다.
- 인스턴스 10개 정도의 규모에서 스웜이 도입하기 적절하다는 생각
- 관리 비용이 많이 드는 쿠버네티스에 비해서 Docker 설치 시에 기본적으로 포함된 서비스
- 러닝 커브가 높지 않기에 다른 구성원들도 쉽게 익힐 수 있음
서버 종료 시 작업도 종료되는 이슈
기증받은 서버들을 회수할 때나 스케일인을 하게 될 때 서버를 종료하는 경우가 생기는데 그때 현재 진행 중인 작업도 같이 종료되는 이슈가 있었습니다. 서버 시작 시에 asyncio 이벤트 루프에 SIGINT와 SIGTERM 시그널이 오면 현재 실행 중인 비동기 작업이 모두 완료되고 서버를 종료하도록 애플리케이션 코드 단에서 구현했습니다. (PR)
asyncio.gather로 보낸 후에는 각종 알림 전송 실패 이슈들이 있었습니다. 전송 중에 세션이 끊기면서 발생하는 ConnectionResetError, ServerDisConnectedError 등이 발생하였고 이외에도 Discord 서버의 이슈로 500 에러나 Rate Limit인 429 에러도 발생했습니다.
이러한 이슈들은 각 예외 케이스들을 정의하고 재시도 요청을 백그라운드로 실행하도록 했습니다. 지수 백오프(Exponential Backoff) 전략을 사용해서 재시도 요청을 각 시도 횟수에 비례해서 재시도 주기도 선형적으로 증가해서 요청하도록 구현했습니다.
마무리
이렇게 2023년 7월에 합류해서 초기 버전을 8월에 배포했는데 늦게나마 후기를 작성해봤습니다. 지금 기준으로 봤을 때 개선할 부분들이 많이 보여서 좀 여유로워 지면 개선을 진행해봐야 되겠습니다. 코드는 아래 레포지토리에서 확인해볼 수 있습니다.
